







频繁模式挖掘实验报告
本次实验,我主要负责实现Apriori算法的改进算法——Eclat算法。
Eclat算法的基本思想
首先,有引理:每个k+1项的频繁项集可以由两个k项的频繁项集经过或运算生成,并且将这两个频繁项集中的项按排序码从小到大排列后,这两个k项频繁项集只有最后一项不一样,之前的k-1项完全一样。引理容易证明:假设这个k+1项的频繁项集的支持度为a,阈值限制为b,则显然有a≥b。该k+1项中的前k项的集合C1的支持度显然大于等于a,同样前k-1项和最后一项组成的集合C2支持度显然也大于等于a。易得,C1,C2均为频繁项集,且这两个集合经过或运算可以得到上述的k+1项的频繁项集。
下证如果已经找到所有的k项频繁,可以找到所有的k+1项集。假设不能找到所有的k+1项集,那么与引理矛盾。所以可以通过已知所有的k项频繁项集找到所有的k+1项频繁项集。
可以通过扫描一遍数据库,得到所有的一维的频繁项集。则由以上结论,我们可以递归地得到所有的频繁项集。
Eclat算法根据以上结论,可以扫描一遍数据库,先获得一维的频繁项集,然后无需再扫描数据库,直接处理所有的一维的频繁项集,就可以递归得到所有的频繁项集。
Eclat算法的具体实现
主要的数据结构有两个,记录频繁项集以及相关信息的mymap类,和处理单一项的onemap类。mymap类由一个bitset记录频繁项集(当某个项出现在该频繁项集中则相应的bitset位为1),一个bitset记录出现在哪些交易中,以及一个int记录频繁项集的支持度。
onemap类由一个bitset记录该项出现在哪些交易中,以及该项的支持度。该项的具体编号不需要记录,因为建了一个onemap数组对应每一个单项,单项可以通过数组中的下标值区分。
实现的Eclat算法主要分两个阶段,input阶段扫描数据库一遍,connect阶段连接扩展频繁项集维数。
input阶段的主要任务是扫描一遍数据库,数据存入onemap,再导入到mymap中。扫描每条交易时,处理每一项对应的onemap,即支持度加一,交易对应的bitset位置1。扫描完所有的交易后,onemap记录了所有单项的支持度和所在的交易。对所有单项依次进行判断,如果某单项的支持度大于阈值,就mymap动态数组mmp1中加入一个元素,该元素与该单项对应。input完成时,动态数组mmp1中已经存了所有的一维的频繁项集,并且由于之前是依次处理的,所以mmp1中元素是有序的。
connect阶段的主要任务是,通过k维频繁项集生出k+1维频繁项集。这里定义了一个函数,void connect(vector <mymap> & vm1, vector <mymap> & vm2),该函数中vm1中存的是所有的k维频繁项集,函数的作用是生成所有的k+1维频繁项并放入vm2中。另一个函数,bool conmp(int a, int b, vector <mymap> & vm1, vector <mymap> & vm2),函数的功能是对vm1中的第a个元素和第b个元素判断能否生成下一维的元素,若能则存入vm2最后。
conmp函数的实现。认为只有最后一项不同的频繁项集才能生成下一维的频繁项集。则对于vm1两个元素记录频繁项集的bitset找到最后一个非零位置0,如此处理后,如果符合条件,那么这两个bitset应该相同,不同则无法生成下一维。如果可以生成,那么记录频繁项集的两个bitset简单的进行或运算就可以得到下一维频繁项集,记录交易的频繁项集进行与操作就可以得到生成的频繁项集的记录交易的bitset,对该bitset中的非0位进行记数,如果小于阈值,则舍弃,否则加入vm2。
connect函数的实现。由上,一维的频繁项集是按大小有序排列的,本函数确保生成的下一维频繁项集的仍然有序(vm2中元素按记录频繁项集的bitset有序排列)。由于有序,只有最后一项不同的频繁项集显然相邻。对于vm1中的第i项,与i之后的每一项进行conmp,一旦发现一次生成失败,则第i项处理结束,对i+1项进行处理。处理完vm1中所有的元素后,清空vm1中的元素,如果这时vm2中的元素个数大于等于2,则connect(vm2,vm1),即将vm2中的元素当做k维元素,向vm1中生成k+1维的频繁项集。
另:如果需要输出数据的话,在发现一个频繁项集后,立刻输出。
一些优化
选用bitset进行存储,相对于布尔节省了空间。同时,bitset的位运算,在一定程度上,节省了时间,程序更精简。在connect函数的实现中,只是用了两个vector,利用类似与滚动数组的思想,将vm1与vm2不断交换功能,极大地节省了空间。
遇到的问题及解决
一开始出现了爆内存的情况,原因是本来打算将所有频繁项都存在内存中,方便输出时间忽略输入到文件。后来,直接一边找一边输出,如果要计时就直接不输出。还发现程序在小阈值时跑得非常慢。多次检查后发现,connect函数中,i元素与j元素连接失败后,没有停止对i的继续连接。实际上,i与i之后的某元素连接失败后可以开始对i+1元素测试,因为可生成下一维的元素一定相邻。
感想
总体来说,Eclat算法不难理解也不难理解。经过本次实验,加深了对数据挖掘的理解。不一样的算法,花费的时间相差很大,也让我体会到算法意义不仅仅是做几道题那么简单。本次实验,还让我熟悉了bitset的相关函数。与同学们的合作很愉快,期待下一次合作!
算法比较
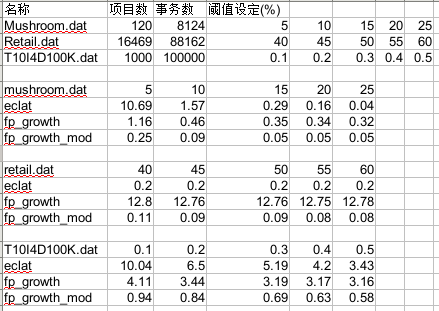
下面列出的三个块分别是对三组数据不同阈值下,三种算法所需的时间,单位秒.
全部算法g++编译,-O2优化,不计算输出时间.
运行环境ubuntu13.04 64位;cpu i5;内存 4G.
相对fp_growth算法与改进版的fp_growth算法来看,还是差了一点的.
[本算法占内存较大!极容易爆内存!]
Eclat代码
/*=============================================================================
# FileName: Eclat.cpp
# Desc:
# Author: zhuting
# Email: cnjs.zhuting@gmail.com
# HomePage: my.oschina.net/locusxt
# Version: 0.0.1
# CreatTime: 2013-12-07 18:54:34
# LastChange: 2013-12-07 18:54:34
# History:
=============================================================================*/
#include <cstdio>
#include <cstdlib>
#include <bitset>
#include <string>
#include <cstring>
#include <time.h>
#include <vector>
#define item 1001
#define line 100000
#define datafile "T10I4D100K.dat"
#define outputfile "r_ans.txt"
#define out_put false
using namespace std;
int min_num = 0;/*最小要求项集出现次数*/
char outputfilename[500] = outputfile;
FILE* fw = fopen(outputfilename, "w");
class mymap
{
public:
bitset <item> it_bs;/*频繁项集*/
int it_set;/*支持度*/
bitset <line> l_bs;/*交易*/
mymap()
{
it_set = 0;
}
};
vector <mymap> mmp1;
vector <mymap> mmp2;
int cur_beg = 0, cur_end = -1, cur_mmp = -1;
/*onemap用来记录一维的频繁项集*/
class onemap
{
public:
int it_set;/*支持度*/
bitset <line> l_bs;/*出现在哪些交易中*/
onemap()
{
it_set = 0;
}
};
onemap om[item];
/*扫描数据库, 获取一维频繁项集*/
void input()
{
char filename[500] = datafile;
FILE* fp = fopen(filename, "r");
char ch_temp[500];
int cur_line = 0;
char ch_num[500];
int num_cur = -1;
int i_temp = 0;
while(cur_line < line)
{
++cur_line;
fscanf(fp, "%[^\n]", ch_temp);
fscanf(fp, "\n");
int len = strlen(ch_temp);
for (int i = 0; i < len; ++i)
{
if (ch_temp[i] == ' ')
{
ch_num[++num_cur] = '\0';
sscanf(ch_num, "%d", &i_temp);
om[i_temp].l_bs[cur_line] = true;
om[i_temp].it_set += 1;
num_cur = -1;
}
else ch_num[++num_cur] = ch_temp[i];
}
}
for (int i = 1; i < item; ++i)
{
if (om[i].it_set >= min_num)/*将一维频繁项集放入mymap*/
{
mymap mp;
mp.it_bs[i] = true;
mp.it_set = om[i].it_set;
mp.l_bs = om[i].l_bs;
++cur_mmp;
mmp1.push_back(mp);
if (out_put)
{
for (int j = 0; j < item; ++j)
{
if (mp.it_bs[j]) fprintf(fw, "%d ", j);
}
fprintf(fw, ":%d\n", mp.it_set);/*输出支持度*/
}
}
}
fclose(fp);
return;
}
bool conmp(int a, int b, vector <mymap> & vm1, vector <mymap> & vm2)
{
bool afind = 0, bfind = 0;
bitset <item> a_bs = vm1[a].it_bs;
bitset <item> b_bs = vm1[b].it_bs;
for (int i = item - 1; i >= 0; --i)/*判断两个项集是否只相差最后一个项,即是否可以生成k+1项*/
{
/* 从后向前找到第一个bitset值为1的位置,并将其置0.
* 如果两个项集只相差最后一个项不同,则分别置0后,两个项集应该一样*/
if (!afind && a_bs[i])
{
afind = true;
a_bs[i] = 0;
}
if (!bfind && b_bs[i])
{
bfind = true;
b_bs[i] = 0;
}
if (afind && bfind)
{
break;
}
}
if (a_bs != b_bs) return false;/*分别置0操作后,若不一样,则无法生成k+1项*/
bitset <line> bs_temp = vm1[a].l_bs & vm1[b].l_bs;/*由k项生成k+1项*/
int i_temp = bs_temp.count();/*支持度*/
if (i_temp >= min_num)
{
mymap mp;
mp.it_bs = vm1[a].it_bs | vm1[b].it_bs;
mp.l_bs = bs_temp;
mp.it_set = i_temp;
vm2.push_back(mp);
++cur_mmp;
if (out_put)
{
for (int j = 0; j < item; ++j)
{
if (mp.it_bs[j]) fprintf(fw, "%d ", j);
}
fprintf(fw, " : %d\n", mp.it_set);
}
}
return true;
}
void connect(vector <mymap> & vm1, vector <mymap> & vm2)
{
for (int i = 0; i < vm1.size(); ++i)
for (int j = i + 1; j < vm1.size(); ++j)
{
bool b_temp = conmp(i, j, vm1, vm2);
if(!b_temp) break;
}
vm1.clear();
if(vm2.size() >= 2) connect(vm2, vm1);/*充分利用空间,两个vector交替使用*/
return;
}
int main()
{
float minsup;/*阈值,小数形式.eg.%5, 阈值为0.05*/
printf("input limit...\n");
scanf("%f", &minsup);
min_num = (int)((float)(line) * minsup) + 1;/*min_num为最小要求的个数*/
if (out_put) printf("%d\n", min_num);
if (out_put) printf("now load date...\n");
int start = clock();/*开始计时*/
input();
if (out_put) printf("now connect...\n");
connect(mmp1, mmp2);
int finish = clock();/*结束计时*/
printf("total time: %f\n", (float)((float)(finish - start) / (float)CLOCKS_PER_SEC));
printf("%d\n", cur_mmp + 1);/*输出总的频繁项集数*/
//if(out_put) fprintf(fw, "%d\n", cur_mmp + 1);
fclose(fw);
return 0;
}














 1751
1751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









