







HBase是一个构建在HDFS上的分布式列存储系统;
HBase是基于Google BigTable模型开发的,典型的key/value系统;
HBase是Apache Hadoop生态系统中的重要一员,主要用于海量非结构化数据存储;
从逻辑上讲,HBase将数据按照表、行和列进行存储。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力
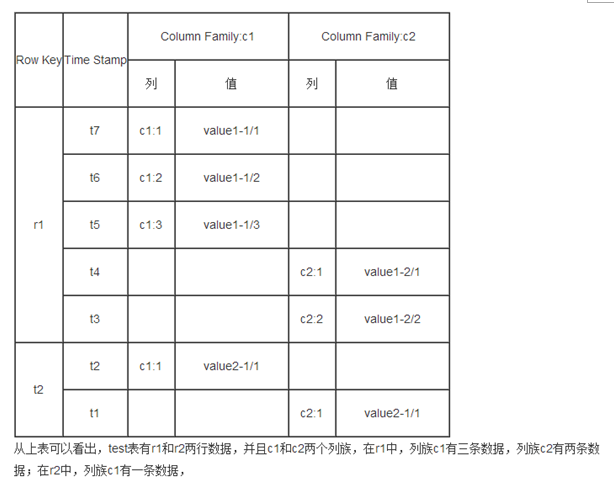
:总结一点,都知道Hbase是一个基于HDFS的列数据库对不对!
Hbase的特征:
BIGTABLE:所谓的大表,一个表可以有数十亿行,和百万个列。
面向列:面向列(族)的存储和权限控制,列(族)独立检索
稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;(所以说,Hbase中没有修改这一个概念,如果修改就是增加数据,只不过时间戳变了。查询出来的数据也就变了。)
数据类型单一:Hbase中的数据都是字符串,没有类型。
注:针对字符串 我需要解释一下:最适合使用Hbase存储的数据是非常稀疏的数据(非结构化或者半结构化的数据)。Hbase之所以擅长存储这类数据,是因为Hbase是column-oriented列导向的存储机制,而我们熟知的RDBMS都是row- oriented行导向的存储机制
结构化数据:结构化信息,我们通常接触的数据库所管理的信息,包括生产、业务、交易、客户信息等方面的记录
非结构化数据:非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等
分析:在许多大型像奇艺,搜狐,腾讯视频 优酷视频。他们的资源可能大部分是非结构化数据。
Hbase存储模型:
HBase的基本元素:
表、行、列、单元格: 表的基本要素
键:一般是指行的键,即唯一标识某行的元素。表中的行,可以根据键进行排序,而对表的访问,也通过键。
列族:所有列族成员拥有相同的前缀,某列族的成员,需要预先定义,但也可以直接进行追加。
列族成员会一起放进存储器。而HBase面向列的存储,是面向列族的数据存储,数据存储与调优都在这个层次,HBase表与RDBMS中表类似,行是排序的,客户端可以把列添加到列族中去。
单元格cell: 单元格中存放的是不可分割的字节数组。并且每个单元格拥有版本信息。HBase的是按版本信息倒序排列。
区域region:将表水平划分,是HBase集群分布数据的最小单位。在线的所有区域就构成了表的内容。

Hbase的存储原理:
自动分区:(跟hadoopHDFS很相似)
Hbase中一个表被划分了很多个Region,它可以动态扩展,保证整个系统的负载均衡。
让一个Region达了上限的时候,就会自动拆分二个相等的Region。(原理就是Hbase中的split和compaction)
每个Region由一个RegionServer管理,一个RegionServer可以管理多个Region。
4. RgionServer管理100-1000个region比较合适。 Region的大小一般在1-20GB
表设计优化:
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式数据库,但是当并发量过高或者已有数据量很大时,读写性能会下降。我们可以采用如下方式逐步提升 HBase 的检索速度。
预先分区
默认情况下,在创建 HBase 表的时候会自动创建一个 Region 分区,当导入数据的时候,所有的 HBase 客户端都向这一个 Region 写数据,直到这个 Region 足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的 Regions,这样当数据写入 HBase 时,会按照 Region 分区情况,在集群内做数据的负载均衡。
Rowkey 优化
HBase 中 Rowkey 是按照字典序存储,因此,设计 Rowkey 时,要充分利用排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
此外,Rowkey 若是递增的生成,建议不要使用正序直接写入 Rowkey,而是采用 reverse 的方式反转 Rowkey,使得 Rowkey 大致均衡分布,这样设计有个好处是能将 RegionServer 的负载均衡,否则容易产生所有新数据都在一个 RegionServer 上堆积的现象,这一点还可以结合 table 的预切分一起设计。
减少ColumnFamily 数量
不要在一张表里定义太多的 ColumnFamily。目前 Hbase 并不能很好的处理超过 2~3 个 ColumnFamily 的表。因为某个 ColumnFamily 在 flush 的时候,它邻近的 ColumnFamily 也会因关联效应被触发 flush,最终导致系统产生更多的 I/O。
缓存策略 (setCaching)
创建表的时候,可以通过 HColumnDescriptor.setInMemory(true) 将表放到 RegionServer 的缓存中,保证在读取的时候被 cache 命中。
设置存储生命期
创建表的时候,可以通过 HColumnDescriptor.setTimeToLive(int timeToLive) 设置表中数据的存储生命期,过期数据将自动被删除。
硬盘配置
每台 RegionServer 管理 10~1000 个 Regions,每个 Region 在 1~2G,则每台 Server 最少要 10G,最大要 1000*2G=2TB,考虑 3 备份,则要 6TB。方案一是用 3 块 2TB 硬盘,二是用 12 块 500G 硬盘,带宽足够时,后者能提供更大的吞吐率,更细粒度的冗余备份,更快速的单盘故障恢复。
分配合适的内存给 RegionServer 服务
在不影响其他服务的情况下,越大越好。例如在 HBase 的 conf 目录下的 hbase-env.sh 的最后添加 export HBASE_REGIONSERVER_OPTS="-Xmx16000m $HBASE_REGIONSERVER_OPTS”
其中 16000m 为分配给 RegionServer 的内存大小。
写数据的备份数
备份数与读性能成正比,与写性能成反比,且备份数影响高可用性。有两种配置方式,一种是将 hdfs-site.xml 拷贝到 hbase 的 conf 目录下,然后在其中添加或修改配置项 dfs.replication 的值为要设置的备份数,这种修改对所有的 HBase 用户表都生效,另外一种方式,是改写 HBase 代码,让 HBase 支持针对列族设置备份数,在创建表时,设置列族备份数,默认为 3,此种备份数只对设置的列族生效。
WAL(预写日志)
可设置开关,表示 HBase 在写数据前用不用先写日志,默认是打开,关掉会提高性能,但是如果系统出现故障 (负责插入的 RegionServer 挂掉),数据可能会丢失。配置 WAL 在调用 Java API 写入时,设置 Put 实例的 WAL,调用 Put.setWriteToWAL(boolean)。
批量写
HBase 的 Put 支持单条插入,也支持批量插入,一般来说批量写更快,节省来回的网络开销。在客户端调用 Java API 时,先将批量的 Put 放入一个 Put 列表,然后调用 HTable 的 Put(Put 列表) 函数来批量写。
客户端一次从服务器拉取的数量
通过配置一次拉去的较大的数据量可以减少客户端获取数据的时间,但是它会占用客户端内存。有三个地方可进行配置:
1)在 HBase 的 conf 配置文件中进行配置 hbase.client.scanner.caching;
2)通过调用 HTable.setScannerCaching(int scannerCaching) 进行配置;
3)通过调用 Scan.setCaching(int caching) 进行配置。三者的优先级越来越高。
RegionServer 的请求处理 IO 线程数
较少的 IO 线程适用于处理单次请求内存消耗较高的 Big Put 场景 (大容量单次 Put 或设置了较大 cache 的 Scan,均属于 Big Put) 或 ReigonServer 的内存比较紧张的场景。
较多的 IO 线程,适用于单次请求内存消耗低,TPS 要求 (每秒事务处理量 (TransactionPerSecond)) 非常高的场景。设置该值的时候,以监控内存为主要参考。
在 hbase-site.xml 配置文件中配置项为 hbase.regionserver.handler.count。
Region 大小设置
配置项为 hbase.hregion.max.filesize,所属配置文件为 hbase-site.xml.,默认大小 256M。
在当前 ReigonServer 上单个 Reigon 的最大存储空间,单个 Region 超过该值时,这个 Region 会被自动 split 成更小的 Region。小 Region 对 split 和 compaction 友好,因为拆分 Region 或 compact 小 Region 里的 StoreFile 速度很快,内存占用低。缺点是 split 和 compaction 会很频繁,特别是数量较多的小 Region 不停地 split, compaction,会导致集群响应时间波动很大,Region 数量太多不仅给管理上带来麻烦,甚至会引发一些 Hbase 的 bug。一般 512M 以下的都算小 Region。大 Region 则不太适合经常 split 和 compaction,因为做一次 compact 和 split 会产生较长时间的停顿,对应用的读写性能冲击非常大。
此外,大 Region 意味着较大的 StoreFile,compaction 时对内存也是一个挑战。如果你的应用场景中,某个时间点的访问量较低,那么在此时做 compact 和 split,既能顺利完成 split 和 compaction,又能保证绝大多数时间平稳的读写性能。compaction 是无法避免的,split 可以从自动调整为手动。只要通过将这个参数值调大到某个很难达到的值,比如 100G,就可以间接禁用自动 split(RegionServer 不会对未到达 100G 的 Region 做 split)。再配合 RegionSplitter 这个工具,在需要 split 时,手动 split。手动 split 在灵活性和稳定性上比起自动 split 要高很多,而且管理成本增加不多,比较推荐 online 实时系统使用。内存方面,小 Region 在设置 memstore 的大小值上比较灵活,大 Region 则过大过小都不行,过大会导致 flush 时 app 的 IO wait 增高,过小则因 StoreFile 过多影响读性能。















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









