







我们那么努力,为什么总感觉过得那么憋屈、苦闷?做的事情那么多,为什么业务部门、直接领导和公司貌似都那么不领情?怎么做才能自己更加开心些?
做运维的那么多,快乐的能有几个?
我们那么努力,为什么总感觉过得那么憋屈、苦闷?做的事情那么多,为什么业务部门、直接领导和公司貌似都那么不领情?怎么做才能自己更加开心些?

本专栏的主线实际是一个运维人员的十年成长史,从菜鸟到运维总监。但不是基础技术教学,也不会在运维技术的某一方面过深涉及。更多的是应用技巧、实践经验及案例剖析。专栏中的系列文章,包含作者在运维各个细分领域的技术和个人成才的心得体会。因此也可以成为广大运维朋友的工具书,伴随大家从初级运维成长为高级技术型运维管理人才。
技术专栏就非得那么中规中矩么?咱这个专栏试图以更轻松活泼的文字,徐徐道来,就当是个老朋友,轻松愉快中,希望能给大家带来收获和启发。
前段时间有位IT大佬在网络上发声,我这么有钱,为什么不幸福?诚然,有钱是幸福的最重要条件之一,但有钱就一定幸福么?真的是充分必要条件?当然更悲催的是运维行当,技术好是被认可(幸福)的最重要条件,但技术再好,外部门不说咱们“坏话”,已经是很不错的了。
1. 什么是高效运维
我们收集了一些来自外部门对运维的印(tou)象(su),如下图所示。其中,大家看是否也多少有自己的影子?
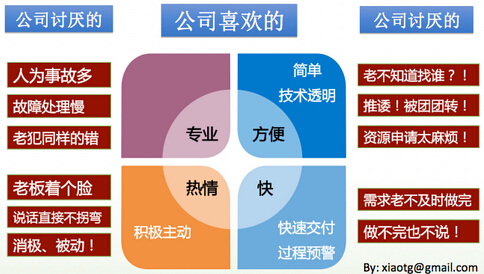
往往看自己都很美,但从外部门来看,槽点多到乃至无力吐槽。首先,做事情不专业,人为事故多(更多是低级的人为事故);很多时候,都是我们业务部门告诉运维,运维才知道发生故障了,而且故障解决时间过长;做个调试,老超出调试时间,超时也不说,是不是完成了也不知会一声;部门内老玩踢皮球的游戏,做个需求,老让我挨个找人;申请个服务器,老费劲了,扔我一个申请表,当自己是衙门呢?或者扔我一个技术文档,我哪看得懂?
专业、热情、方便、快,这是为根治上述各种疑难杂症,经多年自我治疗并综合各方经验,得出的高效运维七字诀。我们用一个简单的公式来表示高效和专业的关系。专业是高效的基石,否则无从谈起高效与否,而技术是专业的基石。但这恰恰也是运维技术人员的误区所在,误以为,技术比较强,就足够了,并因此而忽视其他重要方面。
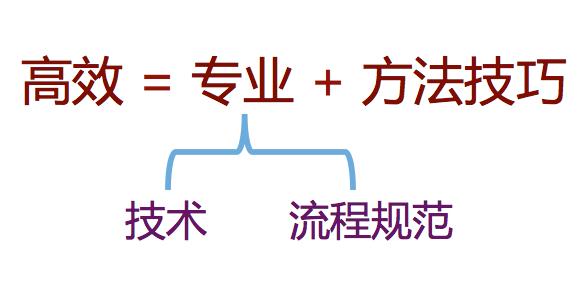
实际上,对外部门而言,运维是个黑盒子,是一个输入输出的关系:外部门提出需求,运维给出结果:完成、或未完成。本质上而言,外部门不关心(也无法关心)我们采用什么技术来实现的,只关心是否如期完成。
合理的流程规范,就像血液,能让部门稳定而高效的运转,大家都觉得开心,这也是专业与否的重要组成部分。但如果希望做到高效运维,良好的客户界面、合适的方法技巧,也非常有必要。这就像网站的UI,给人感觉舒服了,后面很多事情也能轻松愉快、顺理成章地进行。
2. 为什么难以做到高效运维
做不到高效运维,公司和业务部门不满意,上级领导不满意,自己也不满意。原因很多,我们从管理者和员工角度分别来讲。
● 糟糕的分工及连环反应
发生在中小公司的糟糕情况,往往从不明确的分工,开始悲剧之旅。有些游戏创业公司,刚开始时运维人员也就2、3个,基本每人都得会运维的各个工种,游戏运维、网站运维(Nginx/PHP等)、数据库运维(MySQL等)、系统运维(Linux/Windows等)、服务器上架、故障报修、甚至做网线。
公司业务扩大很多后,如果运维组织结构不随之而变,分工不明确,就会发现大家都在疲于奔命,什么都会的结果就是什么都不精。在运维技术如此庞杂的今天,就是把人活活的架在火上烤。这样引发的是多米诺骨牌效应:分工不明确 —> 职责不清楚 —> 考核不量化—> 流程不合理—> 缺规范 、少文档。
● 做vs说的困境
一般运维技术人员都不善于沟通(至少表面上,虽然大家都普遍有火热的心,呵呵)。在微信、QQ大行其道的今天,这个问题变得更严重,而不是减轻。这也和工作性质有关,想想,一天到晚和服务器说话的时间,比和人说话时间都多。
另外,从人脑结构来看,做和说两难全,也是合理的。控制计算、推理能力的是左脑,而表现力等由右脑控制。如果强行要求会做还会说,说不定会导致紊乱、崩溃甚至“脑裂”呢,呵呵(当然,这个问题也是有解决方法的)。
更严重的是,很多同学没意识到自己的沟通表达是有问题的,说句话能把人呛死,也不知道如何有效表达。这样就谈不上热情了。
● 资源错配
管理者和员工都可能存在资源错配的问题。对管理者而言,包括人员错配和时间错配,员工主要是时间错配。
管理者如果把错误的人安排在错误的岗位,那么注定是个错误。例如,某位同学喜欢钻研技术,不喜表达,非得让他作为和外部门的接口人,那自然费力不讨好,大家都不开心。
管理者的时间错配包括三种情况。
1)沉迷解决技术问题。这一般发生在刚从技术岗位提拔为管理者的时候,忘记自己是管理者了。解决复杂技术问题,能带来愉悦感,否则就是挫折感。于是遇到技术问题时,非得死磕到底,然后一周过去了,而部门其他同学却放羊一周。
2)一心扑在管理上。这又是一个极端了,忘记自己的技术身份。把自己变成一个项目经理,整天只关心时间节点,不关注技术人员的小情怀,不协助他们解决具体的技术问题。
3)沉迷单个业务模块。这是另一个特例。一般发生在内部提拔时。例如某位同学,之前是DBA组的负责人,提拔为运维部经理后,还是习惯于抓其擅长的数据库工作,这也是不应该的,否则就没必要提拔了嘛。
员工的资源错配主要体现在时间安排上。事情多了,分不清轻重缓急,没有一个合理的排序原则、指导思想;混淆技术进步和工作要求(有时过分追求技术进步),简单的问题复杂化,降低客户满意度。
3. 如何做到高效运维
高效运维从来不是一个简单的事情,需要多方面共同努力来实现,本文先择其要点简述之,以后专栏系列文章会有更多深入阐述。
● 明确分工/职责
美国著名管理学者史蒂芬·柯维在畅销书《高效能人士的七个习惯》中提出了产出/产能平衡原则。想多产出,先得扩大产能。想金鸡多下蛋,就不能杀鸡取卵。那么对于高效运维而言,产能是什么呢?
包括三部分:1)框架,即合理的分工/职责/KPI,抱歉我提到了KPI,多么让人如此爱恨交织的词语;2)血液,即专业的流程/规范;3)界面,即良好的服务意识/技巧。这些投入足够多,才会得到心仪的产出——高效运维。在贯彻实施这些一段时间后,外部门会诧异的感觉:哟,怎么运维变化这么大。虽然他们不知道原因,但我们可以微微一笑,呵呵。
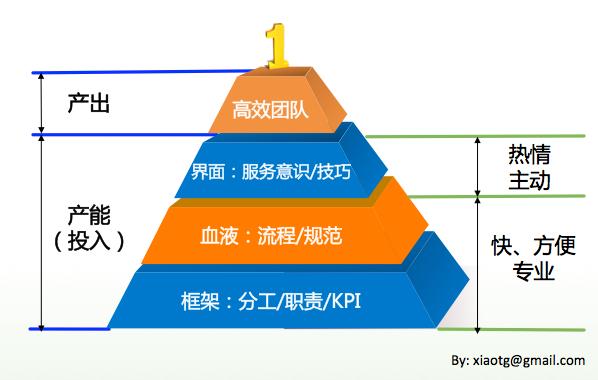
具体到运维部门而言,我们的分工,区别于内网IT部。一个是服务外部客户,一个是服务内部客户,差别还是蛮大的。根据部门分工,拆解出各个小组的分工,再落实到每个员工头上。有章法,大家也觉得舒心。
运维是支持部门,成本中心,难以产生利润。所以其中重要的考核指标其实是客户满意度,请相关业务部门给运维同学打分,运维内部根据分工,也可以相互打分,这对应着外部满意度和内部满意度。KPI虽然令人不舒服,但总的来说,还是有存在的合理性。

● 技术的专业化
技术上的专业化运维,涉及面也很广,下面仅列举几例。
1)优化监控系统
谁来监控监控系统?怎么保证比业务部门先发现问题?是否需要添加业务监控?URL监控是否返回状态码200即万事大吉?是否需要文件监控?短信报警、邮件报警是否足够?是否需要自动语音报警及垂直升级功能?
监控是门学问,是专业运维的入口。展开说可以很大篇幅,先抛砖引玉,提出这些问题。实际上,对于资深、聪明的运维同学,看到问题,就已经有了自己的答案。
2)减少人为事故
人为事故是运维最头疼、最不专业的事情之一。例如网站运维中,如果每次更新都需要登录服务器,svn update/git pull,难免会出差错。所以可以用类似Jenkins的工具,实现Web更新,这样,除非重大更新(包括数据库更新),否则都只需要点点鼠标即可。甚至,可以把网站更新外包回开发部门,这样还能减少运维操作带来的沟通成本、时间成本。
3)运维自动化
运维自动化是个大课题,网络上的讨论也很多。建议选择合适自己的方式、方法。轻量级工具如ansible,无需在被管理服务器安装客户端程序,这在针对多台服务器进行分发管理(特别是管理仅有临时账号权限的服务器时),具有较大优势。另一个吸引人的地方是,操作结果和操作日志集中存储。
4)合理优化架构
近几年国内优秀的开源软件层出不穷,设计和优化架构,很多时候并不是非得自己从零起步来搞。例如Redis,以其高效、稳定,已成为缓存系统的最好选择之一,但Redis单实例的支撑能力有限,目前Redis集群的实现,大多采用Twemproxy,但使用起来老感觉有些美中不足,那么,有没有一个取而代之的产品?
Codis就是其一,Codis由豌豆荚开源,并广泛用于其自身的业务系统。Codis刚好击中Twemproxy两大痛点(无法sharding,运维不友好)。Codis可以平滑的扩容/缩容,随时增减Redis服务器;并提供友好的运维界面,不仅能看到Codis系统运行情况,还能进行数据迁移、主备切换等操作。
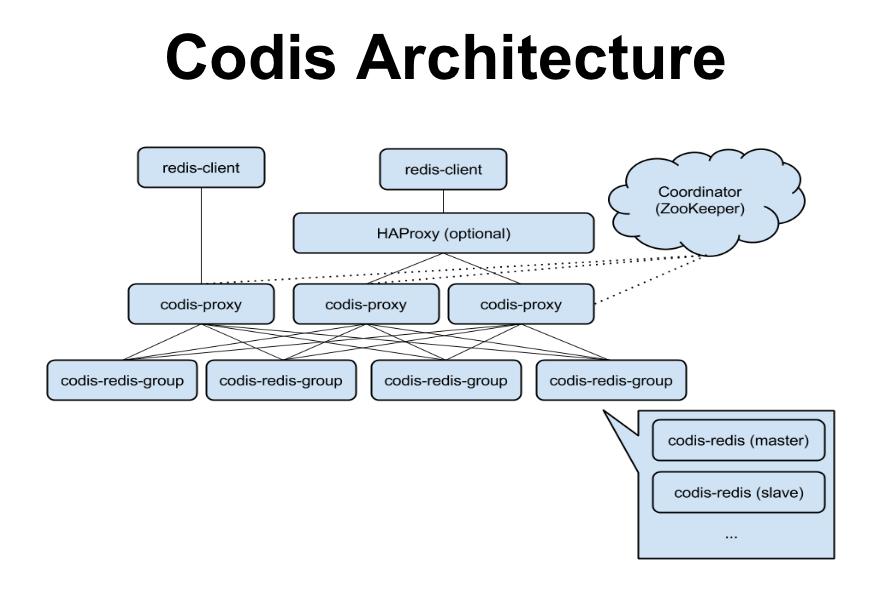
另外,Codis还提供工具,将依赖于Twemproxy的Redis集群,平滑的迁移至Codis(太酷了,那画面太美,我简直不忍看)。性能方面,经我们实测,在正常Value长度下,Codis的get/set性能,优于Twemproxy。
5)代码持续部署
线上系统程序代码可否自动打包、持续部署? 测试环境的新版本发布可否由开发人员自己来做,甚至自己来做测试? 这些无疑可以很大提升运维和开发效率。
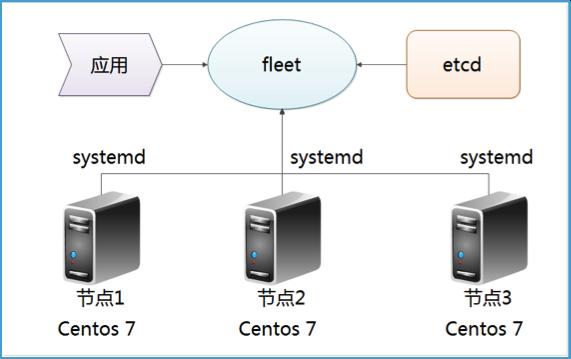
Docker高可用集群,加上Jenkins发布,可以把这些需求变成现实。Centos 7的systemd用来底层支持Docker高可用,etcd实现了配置文件的集中存储,而不是分散在各台服务器的本地。fleet作为etcd和systemd之间的桥梁,并通过systemd来控制集群服务器。
Jenkins从svn服务器获取到新代码版本后,通过shell脚本,打包成image,放入Docker私有库,从而被Docker集群服务器update并使用。
● 管理的专业化
管理上的专业化运维,甚至包括调试通报和故障通报,都很有说法。系统运行一段时间后趋于稳定,调试/更新就变成了故障的主要来源之一,怎么让调试少出人为事故,顺利如期的完成?这是个技术活。
1)运维345法则
故障通报是细究故障的不二法门,一次长时间的故障,往往有很多细节可以推敲,我们总结出运维345法则。3是指故障时长被分成三部分,4是指对应的四个故障时刻点,5是指在这个过程中我们可以做的五件事。这样,我们就可以有的放矢地进行优化解决了。

2)不要让流程吞噬责任
流程规范是很好,不可或缺,好处谁都晓得。只是,流程有时会成为挡箭牌,会让人变得本位,不愿担当,也不愿从事个人职责之外的事情。

这其实是错误的、短视的,“害人害己”的。如果真的出了一个非常严重的故障,个人就能“出污泥而不染”么?没戏。如果是顶级故障,老板想的甚至是把整个运维部门端掉,皮之不存、毛将焉附?
● 良好的客户界面
伸手不打笑脸人。合适的言语表达,可以大事化小、小事化了,反之亦然。只是对做技术的运维同学而言,这是很不容易的事情,甚至有人宁愿多加班,也不去和人沟通。但,工作的要求有时往往需要善于表达,其实也可以换个角度想,把良好的沟通当做一门技术来攻克,如何?
1)当面沟通
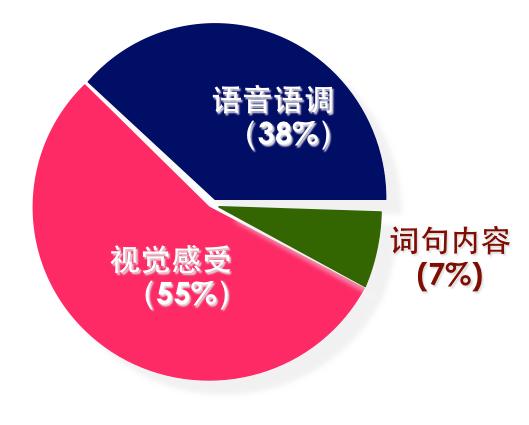
即时聊天工具如QQ、微信实际上是加剧了沟通成本。大家变得更加依赖与此,本来当面沟通或电话沟通,几分钟就能说明白的事情,来来去去几十分钟,更有甚者,还能吵起来,没法愉快的玩耍了。根据国外一项调查,一次有效沟通中,词句内容仅占据一小部分。
我们一般都会要求素未谋面的小伙伴,先当面聊一下。举个真实的例子,有位同学之前和某位运营同学一直QQ、邮件沟通,某次实在说不清楚,于是面聊,发现对方居然是个美女,于是之后合作很愉快(虽然美中不足的是,该女士已有男友)。
2)来的都是客
做运维的,应该放下身段,不一定非得低三下气地做事情,但至少意识得到位。运维的沟通中,也适应心理学的投射原理:越是觉得别人盛气凌人、服务不到位,其实自己也往往是这样的。
来的都是客。如果自己实在忙不开,响应慢。礼貌用语总是可以的嘛,不好意思,对不起,抱歉,谢谢。
4. 小结
絮絮叨叨说了这多,也不知大家看烦木有。运维很苦闷,让苦闷的人变得更苦闷。但不管怎样,也是一门技术。这年头,有门手艺,虽然发达需良机,但至少生存无忧。话说回来,哪行都不容易。
本人做运维这么些年,结合各种失败与成功、痛苦与苦痛的经验,终于悟出高效运维的七字诀:专业、热情、方便、快。不一定完全适合您,但终归是多年的领悟,自成一个小体系,如各位盆友喜欢,以后逐一阐述,如能对大家有所裨益,幸莫大焉。















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









