







elasticsearch内部的调用关系复杂,抽象几张图来说明Index流程,其中忽略一些细节,突出数据流转。
假设ES集群有2个Node组成,里面的某一索引包含3个Shard,我们要执行一次插入操作。

请求的流程:
1. ES任何一个节点都可以接受请求,假设请求落在Node1,ES通过Netty接收到index请求,将请求转发到Action(org.elasticsearch.action.index.TransportIndexAction)进行处理;
2. Action的doExecute方法会判断索引是否存在并尝建立或调整索引,索引的建立由master节点完成,这里不是写入的主流程,暂不在图中标识。之后请求进入路由阶段,由RerountPhase线程进行;
3. RerountPhase会获取shardId并判断当前节点是否是shardId对应的Primary节点,假设本次请求很不幸落在了2shard上。ReroutPhase会将请求转发给Transport层,从图中可以看到,ES集群的所有请求都是由transport层完成转发的,即使请求落在当前Node。
4. tranport判断shardId对应的Node不是当前CurrentNode,会调用Netty进行请求转发,请求转发到Node2;
5. Node2同样会把请求转发给RerountPhase,此时CurrentNode就是shardId对应的Node,进入PrimaryPhase阶段,PrimaryPhase是异步线程池;
6. PrimaryPhase会通过Action的子类完成对应的操作——operationOnPrimary,当Primary完成操作后,PrimaryPhase会创建ReplicationPhase,开启副本操作。
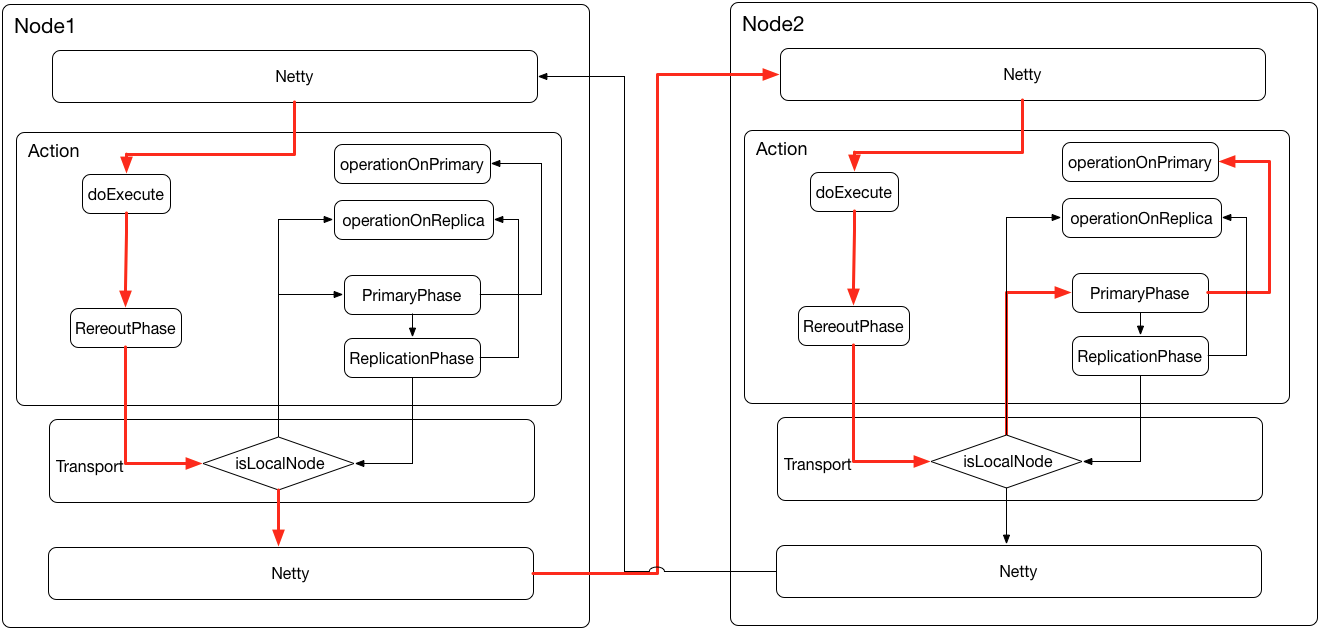
7. 后续操作与primary节点类似,请求通过netty转发到Node1。Node1在ReroutPhase会判断出是副本请求且当前节点是副本,进入——operationOnReplica;
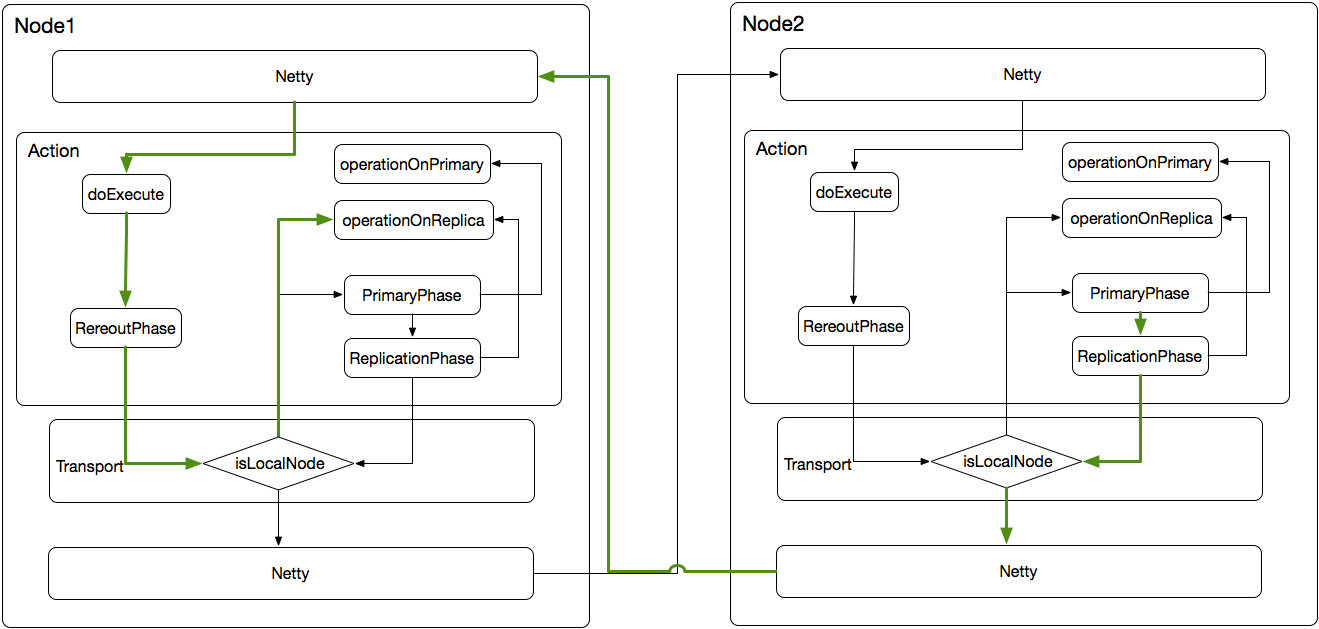
Elasticsearch作为分布式的集群,transport层的作用功不可没。通过Rerout阶段的参数进行请求转发,提供的统一的网络通信层与请求转发逻辑。当然,强带的代码复用性导致代码的可读性比较差,流程的串接依赖参数的值。















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









