









【证书认证】
首先需要获取 ml 功能授权。
节点机器学习配置:
配置Elasticsearch - 机器学习设置 - 《Elastic Stack》 - 书栈网 · BookStack
【模块说明】
机器学习功能由 x-pack 模块提供,该模块在 7.x 以后的版本中已经进行了开源,代码如下:
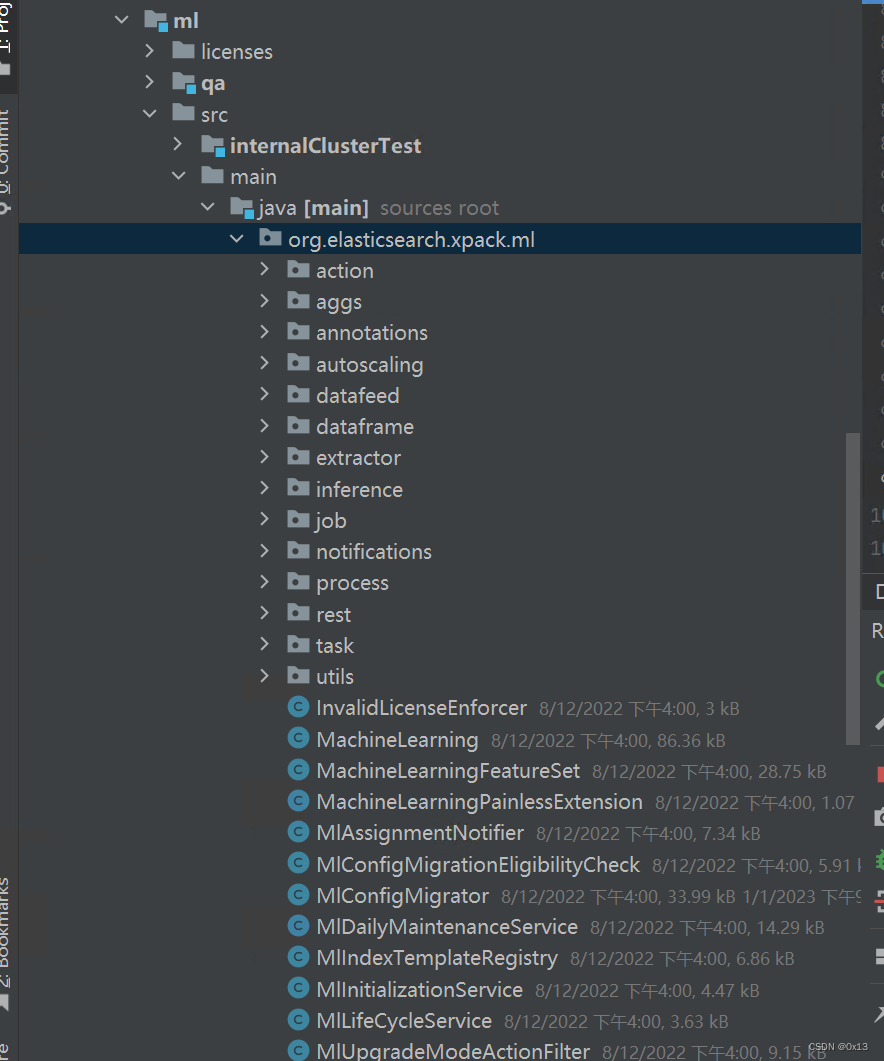
打包插件:
elasticsearch(root)/ x-pack / plugin / ml / Tasks / build / jar
生成的jar目录:
C:\workspace\idea_workspace\elasticsearch\x-pack\plugin\ml\build\distributions\x-pack-ml-7.14.0-SNAPSHOT.jar
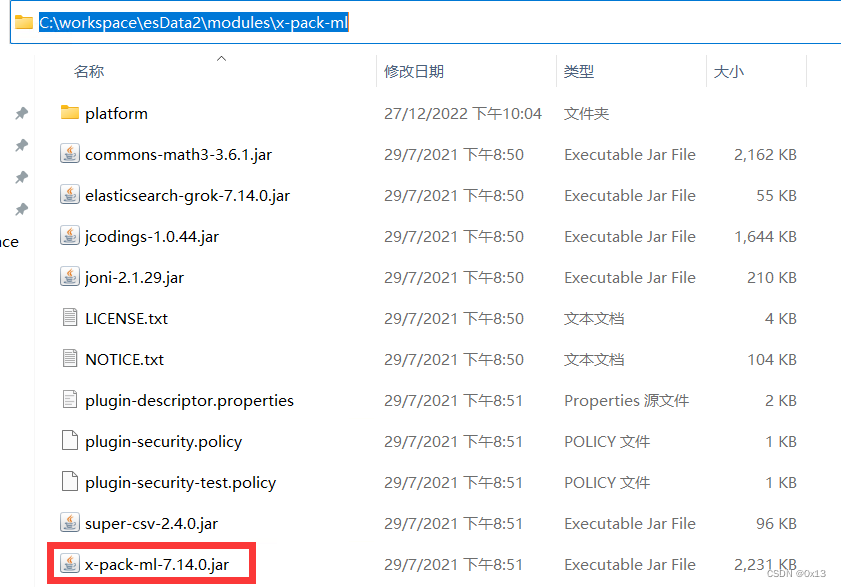
发行版依赖,在数据目录 modules\x-pack-ml 下:

ml任务提交接口请求样例在源码中能找到 rest-api-spec,外部时序数据通过api创建 ml-job,es内部的索引数据通过api转换为 datafeed 作为样本在调用api创建ml-job。
(1)创建单字段的异常检测
PUT _ml/anomaly_detectors/{job_id}
(2)设置job的datafeed,指定某个索引作用样本:
PUT _ml/datafeeds/datafeed-{job_id}
(3)设置datafeed之后任务是关闭的,打开任务:
POST _ml/anomaly_detectors/{job_id}/_open
(4)任务打开后执行启动:
POST _ml/datafeeds/datafeed-{job_id}/_start
(1)创建数据分析任务
PUT /_ml/data_frame/analytics/{data_frame_analytics_id}
(2)开始数据分析任务
POST /_ml/data_frame/analytics/{data_frame_analytics_id}/_start
(3)查看任务结果
GET /_ml/data_frame/analytics/{data_frame_analytics_id}/_stats
【源码入口】
异常检测入口源码:
TransportStartDatafeedAction.masterOperation() => 当前节点接收到前端 _start 请求。
TransportStartDatafeedAction.createDataExtractor => 创建 datafeed 数据提取工厂
PersistentTasksService.sendStartRequest() => 提交任务到集群,任务是机器学习job持久化,主节点处理任务持久化。
TransportStartDatafeedAction.waitForDatafeedStarted() => 当前节点监听到任务持久化成功。
TransportStartDatafeedAction.nodeOperation() => 索引所在的节点真正开始执行任务的入口。
DatafeedRunner.run() => 任务执行器 run
PersistentTasksService.waitForPersistentTaskCondition() => 先任务持久化
DatafeedJobBuilder.build() => 创建任务
AllocatedPersistentTask.updatePersistentTaskState() => 创建任务持久化
MasterService.submitStateUpdateTasks() => 提交集群任务
DatafeedRunner.run.onResponse() => 监听到任务持久化成功,开始执行任务
DatafeedRunner.TaskRunner.runWhenJobIsOpened() => 任务运行入口
DatafeedRunner.TaskRunner.runTask() => 任务运行入口
DatafeedRunner.innerRun() => 任务运行入口
DatafeedRunner.innerRun.doRun() => 执行真正的数据处理
DatafeedRunner.Holder.executeLookBack() => 加锁并执行任务
DatafeedJob.runLookBack() => 执行任务
DatafeedJob.run() => 开始执行数据提取,并执行任务,while 提交每批次数据给底层机器学习库
DatafeedJob.postData() => 提交每个批次数据提交训练
TransportPostDataAction.taskOperation() => 处理数据提交的 action
AutodetectProcessManager.processData() => 将本批次数据传给 native process 也就是 ml-cpp 模块
AutodetectCommunicator.writeToJob() => 提交数据
JsonDataToProcessWriter.write() => 传递json数据到 native process
AbstarctDataToProcessWriter.transformTimeAndWrite() => 循环 while 提交每一行记录
AbstractNativeProcess.writeRecord() => 循环 while 提交每一行记录
LengthEncodedWriter.writeField() => 调用 BufferedOutputStream 将每个字段进行提交
DatafeedJob.flushJob() => flush 结果,到这里任务就完成了。
DatafeedRunner.Holder.finishedLookback() 设置完成状态 lookbackFinished=true
数据分析入口源码:
TransportStartDataFrameAnalyticsAction.DataFrameAnalytics() => 机器学习处理器入口
DataFrameAnalyticsTask.init() =>
PersistentTasksService.waitForPersistentTaskCondition() => 先任务持久化
PersistentTasksCustomMetadata.PersistentTask<TaskParams>.onResponse() => 监听到任务持久化完成,准备开始任务job
TransportDataFrameAnalyticsAction.waitForAnalyticsStarted() =>
DataFrameAnalyticsManager.execute() => 执行任务
DataFrameAnalyticsManager.executeStep() step=reindexing =>
DataFrameAnalyticsManager.executeStep() step=analysis =>
AnalyticsProcessManager.runJob() =>
AnalyticsProcessManager.startProcess() =>
AnalyticsProcessManager.createProcessConfig() => 创建数据分析配置
AnalyticsProcessManager.createProcess() => 创建 AnalyticsProcess 处理器对象
AnalyticsProcessManager.createResultProcessor() => 创建 AnalyticsResultProcessor 对象
AnalyticsResultProcessor.process() => 开始分析处理
AnalyticsProcessManager.processData() => 开始加载数据
AnalyticsResultProcessor.processRowResult() => 处理每个 row 的结果
DataFrameAnalyticsManager.executeStep() step=inference
DataFrameAnalyticsManager.executeStep() step=final
Native 线程管理:
异常检测和数据分析模块由 ml-cpp 进程提供,es 线程调用输出流提交数据,而 NativeController 则负责管理和 ml-cpp native processes 的连接。native 进程是在创建任务 job 的时候启动运行的。
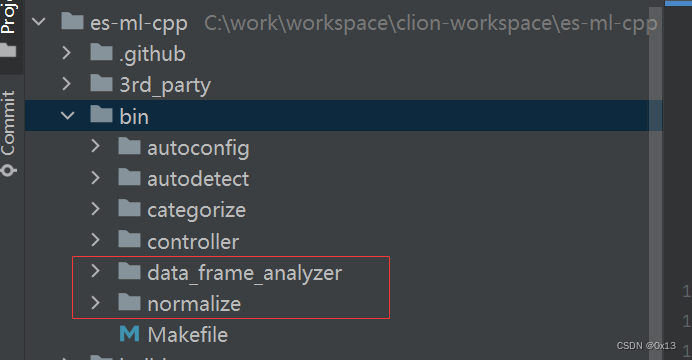
NativeController.startProcess() => 启动进程 cmd=[./normalize, 或者./data_frame_analyzer],这个 normalize 就是可执行文件,可以在 ml-cpp 的源代码中找到。
NativeController.setupResponseTracker() => 设置响应
NativeController.awaitCompletion() => 等待处理完成
NativeController.removeResponseTracker() => 清除响应缓存
ml-cpp 源码可以找到异常检测、数据分析的相关bin,后续编译后再分析相关算法源码:
【算法简介】
es支持异常检测、数据分析两种大类机器学习。每种机器学习又支持不同的job,有的需要训练有的不需要训练。
Anomaly Detection(异常检测):
Single metric:数据分析仅在一个索引字段上执行,在单个时间序列中检测异常。unsupervised。
Mutil metric:数据分析在多个索引字段上执行,使用一个或多个指标检测异常,并可以选择拆分分析。unsupervised。
Populartion:对不常见数据(例如检测总体中的异常值)的分布行为的数据分析。unsupervised。
Advanced:可以对多个索引字段执行数据分析。提供检测器和影响者的完整配置设置。
Categorization:将日志消息分组,并检测其中的异常情况。
Rare:检测时间序列数据中的罕见值。
Data Frame Analytics(数据分析):
Outlier detection:异常值检测识别数据集中的异常数据点。unsupervised。
Regression:回归预测数据集中的数值。supervised。
Classification:分类预测数据集中数据点的类别。supervised。
异常检测主要是针对时序数据进行实时检测。而数据分析主要是通过历史数据进行分析得出一些结果。
针对 Time-series(时序) 数据的分析。它包括异常侦测及预测。这也就是我们常说的非监督机器学习。在这种模式下,用户不用训练机器学习什么是异常,期望得到的是什么,什么是对的,什么是错误的。Elastic ML 通过对数据的观察进行学习。Data frame analytics。这是一种监督的途径。Classification 及 Regression 被用来解决非常复杂的问题。在这种方式下,Elastic ML 需要一定的数据来进行训练,然后我们可以运用训练的模型来对未来的数据进行分类或预测。
不用训练的:
异常检测 [Anomaly detection] 需要时间序列数据。它构建了一个概率模型,并且可以连续运行以识别发生的异常事件。模型会随着时间而演变;您可以使用它的洞察力来预测未来的行为。
异常值检测 [Outlier detection] 不需要时间序列数据。它是一种数据框分析,通过分析每个数据点与其他数据点的接近程度及其周围点簇的密度来识别数据集中的异常点。它不会连续运行;它会生成数据集的副本,其中每个数据点都带有异常值分数。分数表示与其他数据点相比,数据点是异常值的程度。
需要训练的:
有两种类型的数据框分析需要训练数据集: 分类和回归。
在这两种情况下,结果都是您的数据集的副本,其中每个数据点都带有预测和经过训练的模型的注释,您可以部署它来对新数据进行预测。有关详细信息,请参阅 监督学习简介。
分类 [classification] 学习数据点之间的关系,以预测离散的分类值,例如 DNS 请求是来自恶意域还是良性域。
回归 [regression] 学习数据点之间的关系,以预测连续的数值,例如 Web 请求的响应时间。
Outlier detection 和 Population 的区别:
前者是基于实体 entity ,找出一组 entity 中和群体表现差异较大的 entity。例如基于消费者名称找出消费金额、频次比较突出的个体。
后者是基于时序,先找出群体群体中和大部分个体的变化趋势差异较大的小部分群体。
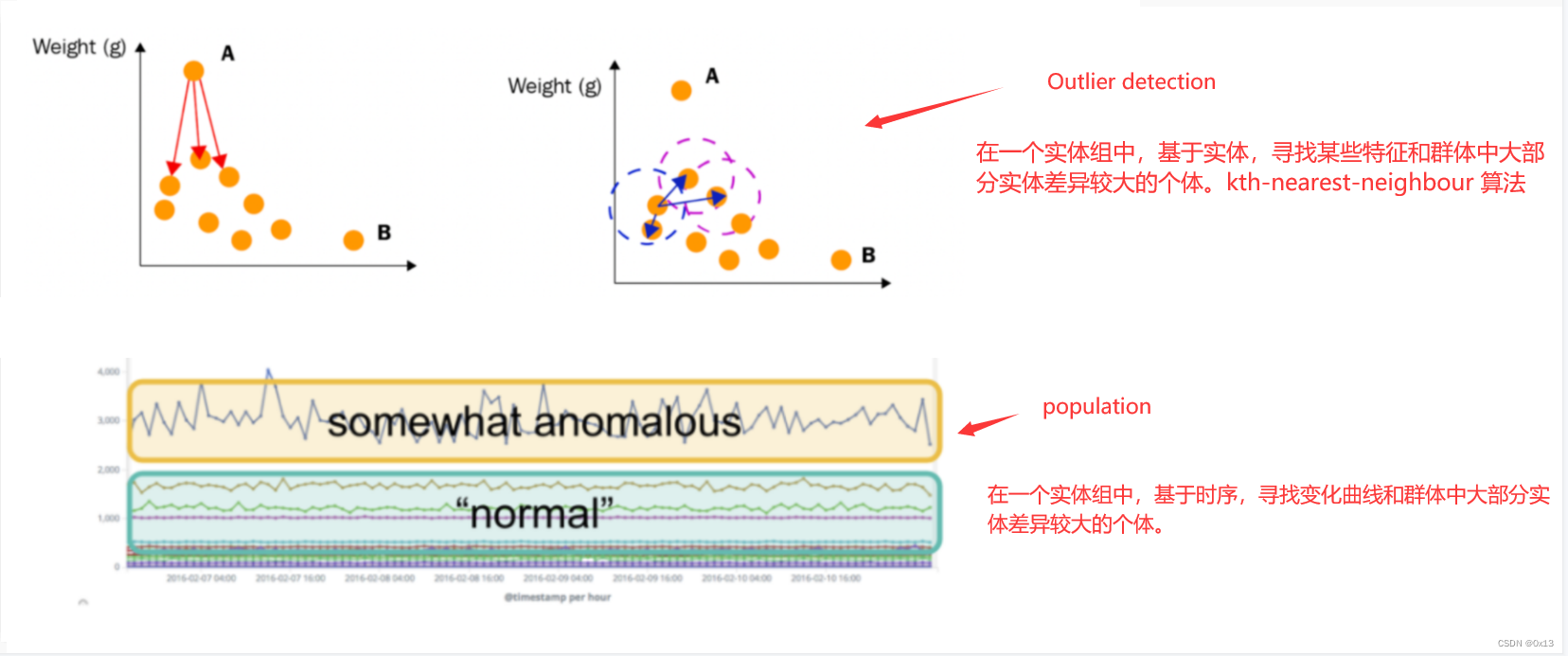
前者自己和自己比,后者自己和其他大部分人比。注意 mutil-metric 可以选择 split 字段,不选择则是对全局数据进行异常曲线分析,选择 custom_id 则是对每个用户进行数据异常曲线分析。
后者是群体分析。,建立 “典型” 用户,机器或其他实体在指定时间段内所做的工作的概况,然后识别与其它群体相比表现异常的时候。

【使用流程】
异常检测使用内部数据作为样本需要创建 datafeed,也就是指定某个索引按照过滤、时间等得到的数据集作为一个 job 的 datafeed,如下:
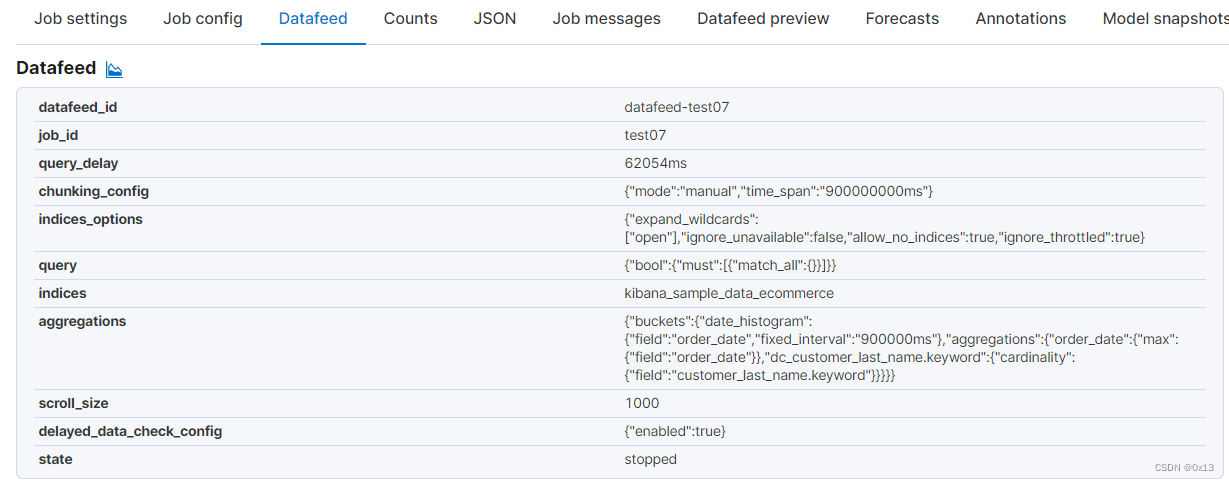
Mutil metric(无监督):
同 Single metric 一样,只不过可以同时分析多个字段,流程一样先创建job然后根据索引时间过滤得到 datafeed 然后运行。
Population(无监督):
在设置 datafeed 时需要设置下列信息,一是分析纬度 Popolation field(例如商品名称)、二是多个评价指标聚合函数 metric(例如 sum/avg)、三是 Bucket span(聚合时间)。可以得到每个商品在一段时间内的聚合统计值,以及该聚合统计值相比所有商品是否异常:

Categorization(无监督):
主要用于半结构化的日志聚类并统计分析,日志一般都相似的格式,同一个格式的日志里面某一些字段(文档片段)不同。Categorization 可以将这种半结构化日志进行分类。分类之后按照时间 bucket 进行统计( 计数)最后进行数据分析判断异常。
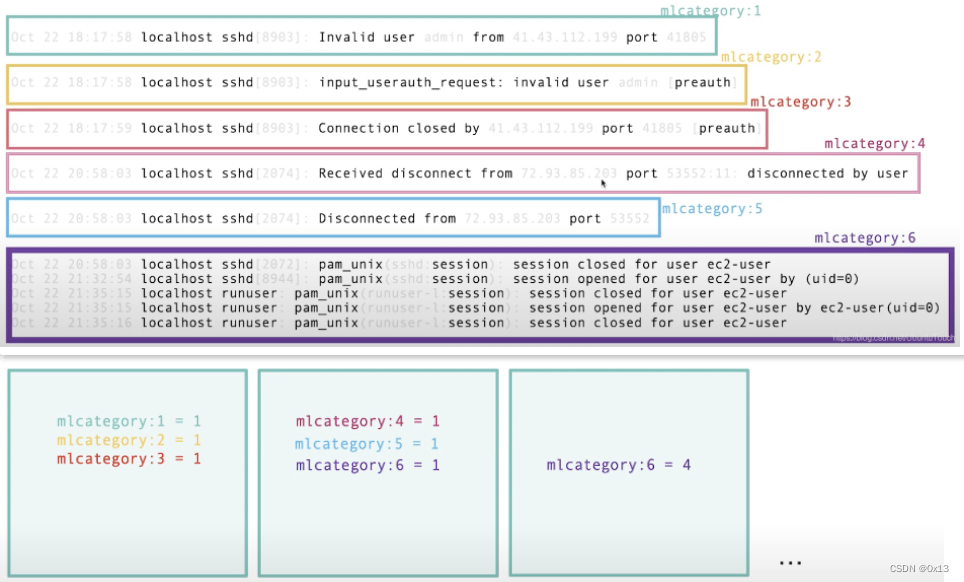
使用内部数据作为样本同样需要根据索引来指定训练集,但是相比异常检测的 datafeed(时序数据) 会更加复杂,es 引入了 transfer 流程,也就是将一个索引定义 transfer 转化为另外一个索引作为数据分析的数据集:
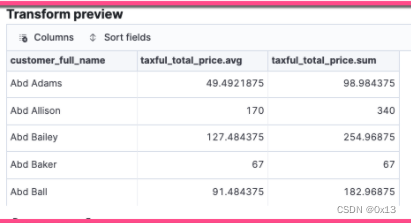
例如将样例 kibana_sample_data_ecommerce 订单索引按照顾客名称、商品名称等某个单体的维度作为 entity 执行 transfer,转换过程就是先提前执行一下分组聚合得到以 entity 纬度的表格。比如可以
以 customer_full_name(顾客名称)为实体聚合每个顾客所有订单的总金额 sum/avg(taxful_total_price),得到一个每个顾客的平均消费金额和总消费金额,也就是 transfer 得到的是一般意义的样本数据而不是 datafeed 一样的时序数据。
回归分析通常用于走势预测,同样需要通过索引设置样本,索引里面有多个字段,因为多个影响因素造成某一个结果,例如楼层、年代、套间数等造成的房价可以得到一个多维模型,模型可以根据楼层、年代等预测房价,并给出某一个因素对房价影响的贡献度。
在设置训练样本要定训练、测试集的比例。
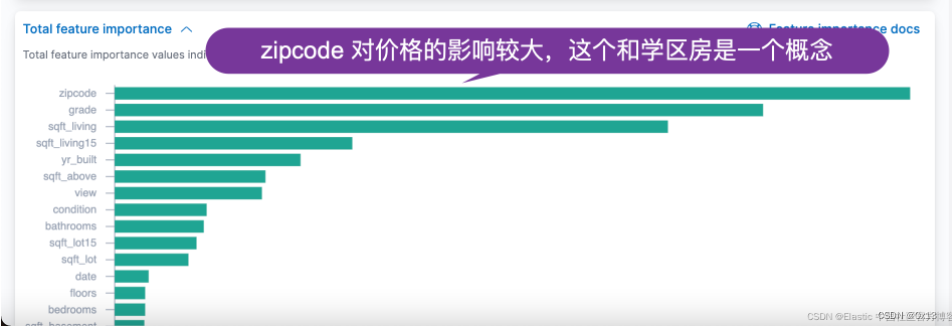
分类模型是最常用的机器学习算法,和回归分析不一样的是分类模型得到有限个类别,根据多个特征来计算属于哪一个类别。类别可以是好瓜、坏瓜这种二分类,也可以是0%、50%、100%多分类。通常也需要 transfer 做提前的聚合。在创建任务时需要设置以下信息。
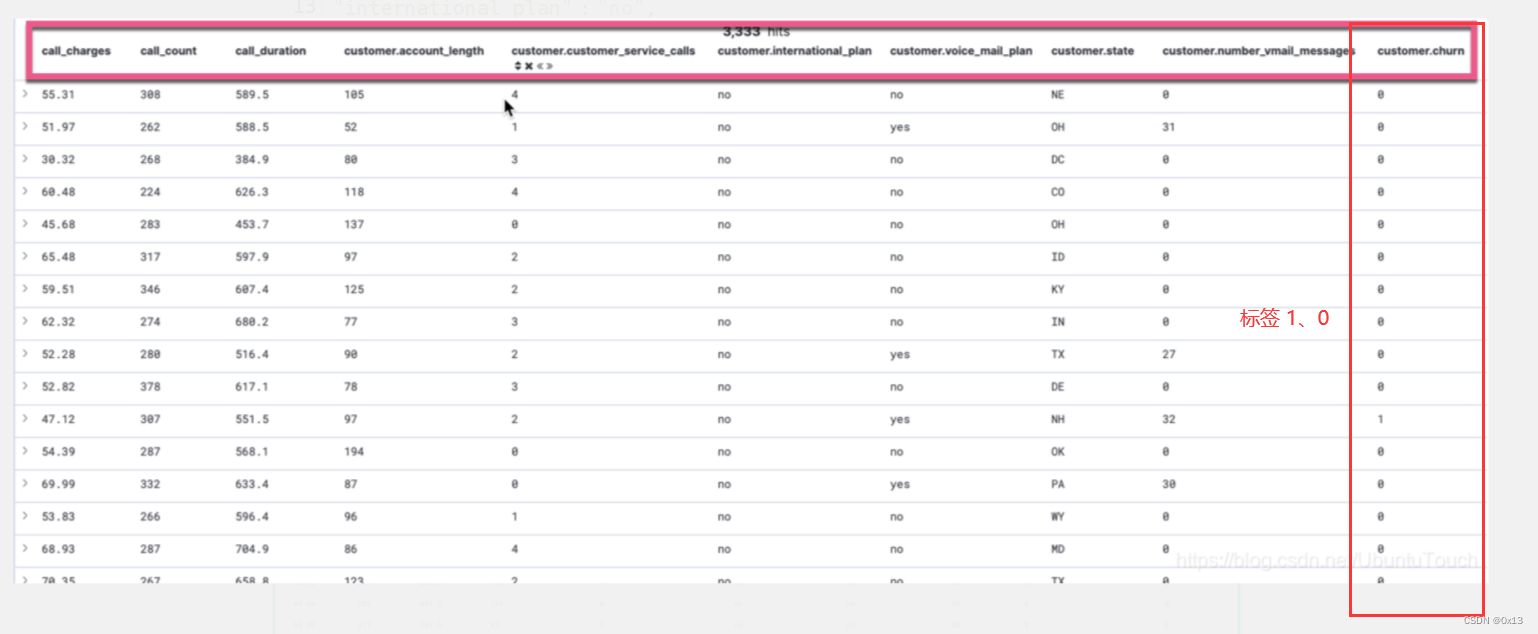
一是标签,二是特征列。例如根据通话次数、时间、短信数等预测客户是否流失,建立模型之后可以进行预测。
【源码】异常检测
这里 DatafeedJob.run() 是异常分析的入口,流程是调用数据提取器提取一批次数据,然后while循环调用 postData() 提交训练,Action=cluster:admin/xpack/ml/job/data/post,然后由
DatafeedJob.run() 代码如下:
private void run(long start, long end, FlushJobAction.Request flushRequest) throws IOException {
if (end <= start) {
return;
}
// A storage for errors that should only be thrown after advancing time
RuntimeException error = null;
long recordCount = 0;
DataExtractor dataExtractor = dataExtractorFactory.newExtractor(start, end);
while (dataExtractor.hasNext()) {
if ((isIsolated || isRunning() == false) && dataExtractor.isCancelled() == false) {
dataExtractor.cancel();
}
if (isIsolated) {
return;
}
// 提取到的数据
Optional<InputStream> extractedData;
try {
extractedData = dataExtractor.next();
}
catch (Exception e) {
if (e.toString().contains("doc values")) {
throw new ExtractionProblemException(nextRealtimeTimestamp(), new IllegalArgumentException(
"One or more fields do not have doc values; please enable doc values for all analysis fields for datafeeds" +
" using aggregations"));
}
throw new ExtractionProblemException(nextRealtimeTimestamp(), e);
}
if (isIsolated) {
return;
}
if (extractedData.isPresent()) {
DataCounts counts;
try (InputStream in = extractedData.get()) {
counts = postData(in, XContentType.JSON);
LOGGER.trace(() -> new ParameterizedMessage("[{}] Processed another {} records with latest timestamp [{}]", jobId, counts.getProcessedRecordCount(), counts.getLatestRecordTimeStamp()));
timingStatsReporter.reportDataCounts(counts);
} catch (Exception e) {
if (e instanceof InterruptedException) {
Thread.currentThread().interrupt();
}
if (isIsolated) {
return;
}
LOGGER.error(new ParameterizedMessage("[{}] error while posting data", jobId), e);
boolean shouldStop = isConflictException(e);
error = new AnalysisProblemException(nextRealtimeTimestamp(), shouldStop, e);
break;
}
recordCount += counts.getProcessedRecordCount();
haveEverSeenData |= (recordCount > 0);
if (counts.getLatestRecordTimeStamp() != null) {
lastEndTimeMs = counts.getLatestRecordTimeStamp().getTime();
}
}
}
lastEndTimeMs = Math.max(lastEndTimeMs == null ? 0 : lastEndTimeMs, dataExtractor.getEndTime() - 1);
if (error != null) {
throw error;
}
if (isRunning() && isIsolated == false) {
Instant lastFinalizedBucketEnd = flushJob(flushRequest).getLastFinalizedBucketEnd();
if (lastFinalizedBucketEnd != null) {
this.latestFinalBucketEndTimeMs = lastFinalizedBucketEnd.toEpochMilli();
}
}
if (recordCount == 0) {
throw new EmptyDataCountException(nextRealtimeTimestamp(), haveEverSeenData);
}
}数据提取器接口 DataExtractor 有多个子类:
AbstractAggregationDataExtractor
AggregationDataExtractor
ChunkedDataExtractor :
CompositeAggregationDataExtractor
RollupDataExtractor
ScrollDataExtractor
然后将每批次数据构造 PostDataAction.Request 转交给 TransportPostDataAction 进行处理,其中 Action=cluster:admin/xpack/ml/job/data/post :
DatafeedJob.postData 代码如下:
private DataCounts postData(InputStream inputStream, XContentType xContentType) throws IOException {
// dataDescription 里面就是 job 的详细配置
PostDataAction.Request request = new PostDataAction.Request(jobId);
request.setDataDescription(dataDescription);
request.setContent(Streams.readFully(inputStream), xContentType);
try (ThreadContext.StoredContext ignore = client.threadPool().getThreadContext().stashWithOrigin(ML_ORIGIN)) {
PostDataAction.Response response = client.execute(PostDataAction.INSTANCE, request).actionGet();
return response.getDataCounts();
}
}
最终由 TransportPostDataAction 进行处理,会将批次数据传给 native process 。
protected void taskOperation(PostDataAction.Request request, JobTask task, ActionListener<PostDataAction.Response> listener) {
TimeRange timeRange = TimeRange.builder().startTime(request.getResetStart()).endTime(request.getResetEnd()).build();
DataLoadParams params = new DataLoadParams(timeRange, Optional.ofNullable(request.getDataDescription()));a
try (InputStream contentStream = request.getContent().streamInput()) {
processManager.processData(task, analysisRegistry, contentStream, request.getXContentType(),
params, (dataCounts, e) -> {
if (dataCounts != null) {
listener.onResponse(new PostDataAction.Response(dataCounts));
} else {
listener.onFailure(e);
}
});
} catch (Exception e) {
listener.onFailure(e);
}
}
















 3814
3814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











