









既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
queryBuilder.analyzer(request.param("analyzer"));
queryBuilder.analyzeWildcard(request.paramAsBoolean("analyze\_wildcard", false));
queryBuilder.lenient(request.paramAsBoolean("lenient", null));
String defaultOperator = request.param("default\_operator");
if (defaultOperator != null) {
queryBuilder.defaultOperator(Operator.fromString(defaultOperator));
}
return queryBuilder;
}
### 调用doToQuery函数
获取到 QueryStringQueryParser
protected Query doToQuery(SearchExecutionContext context)
QueryStringQueryParser queryParser;
queryParser = new QueryStringQueryParser(context, resolvedFields, isLenient);
### es跨字段检索实现
SearchExecutionContext context = createSearchExecutionContext();
QB firstQuery = createTestQueryBuilder();
QB controlQuery = copyQuery(firstQuery);
QueryBuilder rewritten = rewriteQuery(firstQuery, new SearchExecutionContext(context));
Query firstLuceneQuery = rewritten.toQuery(context);
### Rewriteable
public interface Rewriteable{
static <T extends Rewriteable> void rewriteAndFetch(
T original,
QueryRewriteContext context,
ActionListener rewriteResponse,
int iteration
) {
T builder = original;
try {
for (T rewrittenBuilder = builder.rewrite(context); rewrittenBuilder != builder; rewrittenBuilder = builder.rewrite(context)) {
builder = rewrittenBuilder;
if (iteration++ >= MAX_REWRITE_ROUNDS) {
// this is some protection against user provided queries if they don’t obey the contract of rewrite we allow 16 rounds
// and then we fail to prevent infinite loops
throw new IllegalStateException(
"too many rewrite rounds, rewriteable might return new objects even if they are not " + “rewritten”
);
}
if (context.hasAsyncActions()) {
T finalBuilder = builder;
final int currentIterationNumber = iteration;
context.executeAsyncActions(
ActionListener.wrap(
n -> rewriteAndFetch(finalBuilder, context, rewriteResponse, currentIterationNumber),
rewriteResponse::onFailure
)
);
return;
}
}
rewriteResponse.onResponse(builder);
} catch (IOException | IllegalArgumentException | ParsingException ex) {
rewriteResponse.onFailure(ex);
}
}
}
### AbstractQueryBuilder类
public abstract class AbstractQueryBuilder<QB extends AbstractQueryBuilder> implements QueryBuilder
static Collection toQueries(Collection queryBuilders, SearchExecutionContext context) throws QueryShardException,
IOException {
List queries = new ArrayList<>(queryBuilders.size());
for (QueryBuilder queryBuilder : queryBuilders) {
Query query = queryBuilder.rewrite(context).toQuery(context);
if (query != null) {
queries.add(query);
}
}
return queries;
}
public final Query toQuery(SearchExecutionContext context) throws IOException {
Query query = doToQuery(context);
if (query != null) {
if (boost != DEFAULT_BOOST) {
if (query instanceof MatchNoDocsQuery == false) {
query = new BoostQuery(query, boost);
}
}
if (queryName != null) {
context.addNamedQuery(queryName, query);
}
}
return query;
}
### MultiMatchQueryParser实现
MultiMatchQueryParser parser = new MultiMatchQueryParser(searchExecutionContext);
Map<String, Float> fieldNames = new HashMap<>();
fieldNames.put(“field”, 1.0f);
fieldNames.put(“field_split”, 1.0f);
fieldNames.put(“field_normalizer”, 1.0f);
fieldNames.put(“field_split_normalizer”, 1.0f);
Query query = parser.parse(MultiMatchQueryBuilder.Type.BEST_FIELDS, fieldNames, “Foo Bar”, null);
DisjunctionMaxQuery expected = new DisjunctionMaxQuery(
Arrays.asList(
new TermQuery(new Term(“field_normalizer”, “foo bar”)),
new TermQuery(new Term(“field”, “Foo Bar”)),
new BooleanQuery.Builder().add(new TermQuery(new Term(“field_split”, “Foo”)), BooleanClause.Occur.SHOULD)
.add(new TermQuery(new Term(“field_split”, “Bar”)), BooleanClause.Occur.SHOULD)
.build(),
new BooleanQuery.Builder().add(new TermQuery(new Term(“field_split_normalizer”, “foo”)), BooleanClause.Occur.SHOULD)
.add(new TermQuery(new Term(“field_split_normalizer”, “bar”)), BooleanClause.Occur.SHOULD)
.build()
),
0.0f
);
### MultiMatchQueryBuilder
public class MultiMatchQueryBuilder extends AbstractQueryBuilder
protected Query doToQuery(SearchExecutionContext context){
MultiMatchQueryParser multiMatchQuery = new MultiMatchQueryParser(context);
multiMatchQuery.setAnalyzer(analyzer);
multiMatchQuery.setOccur(operator.toBooleanClauseOccur());
multiMatchQuery.setTieBreaker(tieBreaker);
return multiMatchQuery.parse(type, newFieldsBoosts, value, minimumShouldMatch);
}
### MultiMatchQueryParser
public class MultiMatchQueryParser extends MatchQueryParser {
public Query parse(MultiMatchQueryBuilder.Type type, Map<String, Float> fieldNames, Object value, String minimumShouldMatch)
final List queries = switch (type) {
case PHRASE, PHRASE_PREFIX, BEST_FIELDS, MOST_FIELDS, BOOL_PREFIX -> buildFieldQueries(
type,
fieldNames,
value,
minimumShouldMatch
);
case CROSS_FIELDS -> buildCrossFieldQuery(fieldNames, value, minimumShouldMatch, tieBreaker);
};
return combineGrouped(queries, tieBreaker);
return new DisjunctionMaxQuery(groupQuery, tieBreaker);
}
#### buildCrossFieldQuery 核心
跨字段召回的 核心代码,生成一堆 List should链接
叶子是 CrossFieldsQueryBuilder
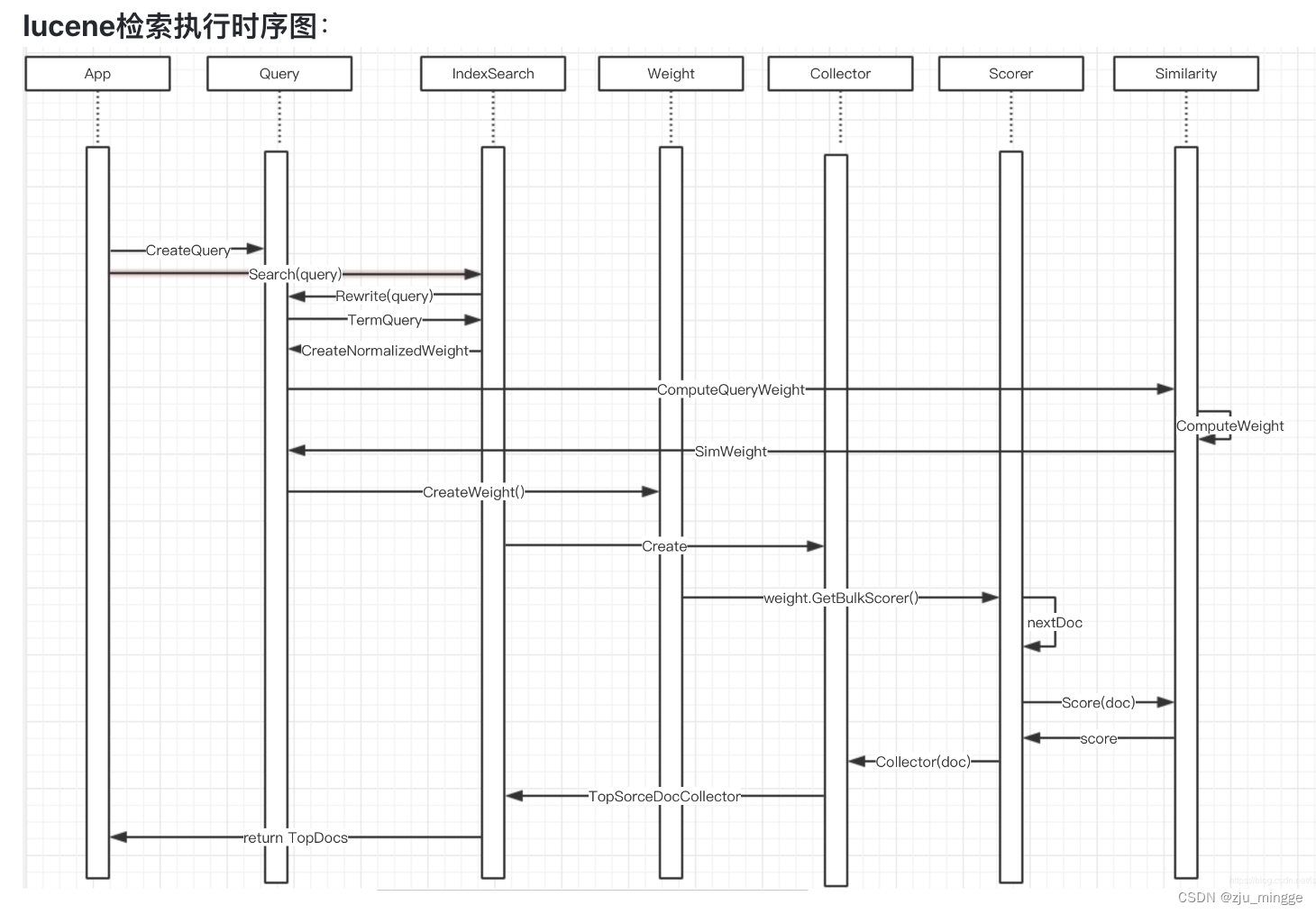
### lucene检索流程
Analyzer analyzer = new StandardAnalyzer();
Path indexPath = Files.createTempDirectory("tempIndex");
Directory directory = FSDirectory.open(indexPath)
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter iwriter = new IndexWriter(directory, config);
Document doc = new Document();
String text = "This is the text to be indexed.";
doc.add(new Field("fieldname", text, TextField.TYPE_STORED));
iwriter.addDocument(doc);
iwriter.close();
// Now search the index:
DirectoryReader ireader = DirectoryReader.open(directory);
IndexSearcher isearcher = new IndexSearcher(ireader);
// Parse a simple query that searches for "text":
QueryParser parser = new QueryParser("fieldname", analyzer);
Query query = parser.parse("text");
ScoreDoc[] hits = isearcher.search(query, 10).scoreDocs;
assertEquals(1, hits.length);
// Iterate through the results:
for (int i = 0; i < hits.length; i++) {
Document hitDoc = isearcher.doc(hits[i].doc);
assertEquals("This is the text to be indexed.", hitDoc.get("fieldname"));
}
ireader.close();
directory.close();
IOUtils.rm(indexPath);
### es检索流程
public TransportSearchAction(
ThreadPool threadPool,
CircuitBreakerService circuitBreakerService,
TransportService transportService,
SearchService searchService,
SearchTransportService searchTransportService,
SearchPhaseController searchPhaseController,
ClusterService clusterService,
ActionFilters actionFilters,
IndexNameExpressionResolver indexNameExpressionResolver,
NamedWriteableRegistry namedWriteableRegistry,
ExecutorSelector executorSelector
)
SearchTransportService.registerRequestHandler(transportService, searchService);
transportService.registerRequestHandler(
QUERY_ID_ACTION_NAME,
ThreadPool.Names.SAME,
QuerySearchRequest::new,
(request, channel, task) -> {
searchService.executeQueryPhase(
request,
(SearchShardTask) task,
new ChannelActionListener<>(channel, QUERY_ID_ACTION_NAME, request)
);
}
);
public void executeQueryPhase(QuerySearchRequest request, SearchShardTask task, ActionListener listener)
runAsync(getExecutor(readerContext.indexShard()), () -> {
readerContext.setAggregatedDfs(request.dfs());
try (
SearchContext searchContext = createContext(readerContext, shardSearchRequest, task, true);
SearchOperationListenerExecutor executor = new SearchOperationListenerExecutor(searchContext)
) {
searchContext.searcher().setAggregatedDfs(request.dfs());
QueryPhase.execute(searchContext);
if (searchContext.queryResult().hasSearchContext() == false && readerContext.singleSession()) {
// no hits, we can release the context since there will be no fetch phase
freeReaderContext(readerContext.id());
}
executor.success();
// Pass the rescoreDocIds to the queryResult to send them the coordinating node and receive them back in the fetch phase.
// We also pass the rescoreDocIds to the LegacyReaderContext in case the search state needs to stay in the data node.
final RescoreDocIds rescoreDocIds = searchContext.rescoreDocIds();
searchContext.queryResult().setRescoreDocIds(rescoreDocIds);
readerContext.setRescoreDocIds(rescoreDocIds);
return searchContext.queryResult();
} catch (Exception e) {
assert TransportActions.isShardNotAvailableException(e) == false : new AssertionError(e);
logger.trace(“Query phase failed”, e);
// we handle the failure in the failure listener below
throw e;
}
}, wrapFailureListener(listener, readerContext, markAsUsed));
/*
Query phase of a search request, used to run the query and get back from each shard information about the matching documents
* (document ids and score or sort criteria) so that matches can be reduced on the coordinating node
*/
QueryPhase类 负责执行搜索,获取结果
public static void execute(SearchContext searchContext){
AggregationPhase.preProcess(searchContext); // 预处理
boolean rescore = executeInternal(searchContext); // 执行
QuerySearchResult queryResult = searchContext.queryResult(); //
Query query = searchContext.rewrittenQuery(); // 构造query
boolean shouldRescore = searchWithCollector(searchContext, searcher, query, collectors, hasFilterCollector, timeoutSet);
searcher.search(query, queryCollector); // 调用lucene的api
ExecutorService executor = searchContext.indexShard().getThreadPool().executor(ThreadPool.Names.SEARCH);
if (rescore) { // only if we do a regular search
RescorePhase.execute(searchContext);
}
SuggestPhase.execute(searchContext);
AggregationPhase.execute(searchContext);
searchContext.queryResult().profileResults(searchContext.getProfilers().buildQueryPhaseResults());
}
public class ContextIndexSearcher extends IndexSearcher implements Releasable
// lucene api
void search(Query query, Collector results)
query = rewrite(query); // 重写query
Query query = original;
for (Query rewrittenQuery = query.rewrite(reader); rewrittenQuery != query;
rewrittenQuery = query.rewrite(reader)) {
query = rewrittenQuery;
}
search(leafContexts, createWeight(query, results.scoreMode(), 1), results);
weight = wrapWeight(weight);
collector.setWeight(weight);
for (LeafReaderContext ctx : leaves) { // search each subreader
searchLeaf(ctx, weight, collector);
leafCollector = collector.getLeafCollector(ctx);
Bits liveDocs = ctx.reader().getLiveDocs();
BitSet liveDocsBitSet = getSparseBitSetOrNull(liveDocs);
BulkScorer bulkScorer = weight.bulkScorer(ctx);
bulkScorer.score(leafCollector, liveDocs);
}
public Query rewrite(IndexReader reader) throws IOException {
if (termArrays.length == 0) {
return new MatchNoDocsQuery(“empty MultiPhraseQuery”);
} else if (termArrays.length == 1) { // optimize one-term case
Term[] terms = termArrays[0];
BooleanQuery.Builder builder = new BooleanQuery.Builder();
for (Term term : terms) {
builder.add(new TermQuery(term), BooleanClause.Occur.SHOULD);
}
return builder.build();
} else {
return super.rewrite(reader);
}
}
如果用户需要对搜索结果自定义一套评分机制,并且获得更强的控制力,可以自定义一套query,weight和scorer对象树。
query对象树是对用户查询信息(比如,布尔逻辑表达式)的抽象。
weight对象树是对query内部统计信息(比如,TF-IDF值)的抽象。
scorer对象树提供了评分与解说评分的接口能力。
### 查询语句分类
将子查询结果按照must, should, filter, must\_not分类.
根据should, must, filter数量进行:
pure conjunction.
pure disjunction.
conjunction-disjunction mix.
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
njunction.
pure disjunction.
conjunction-disjunction mix.
[外链图片转存中...(img-5wVpUyDJ-1715590488529)]
[外链图片转存中...(img-giVuDT11-1715590488529)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









