







简介:OpenCV是计算机视觉领域中用于图像处理和分析的开源库。在本示例中,我们将深入探讨如何使用OpenCV进行轮廓提取,包括理解轮廓的定义、 findContours 函数的使用、二值化处理、参数设置以及如何选择提取外边缘或内边缘的策略。示例中将通过Python代码展示提取轮廓的过程,并讨论轮廓提取在不同领域的应用实例,如机器人导航、自动驾驶等。 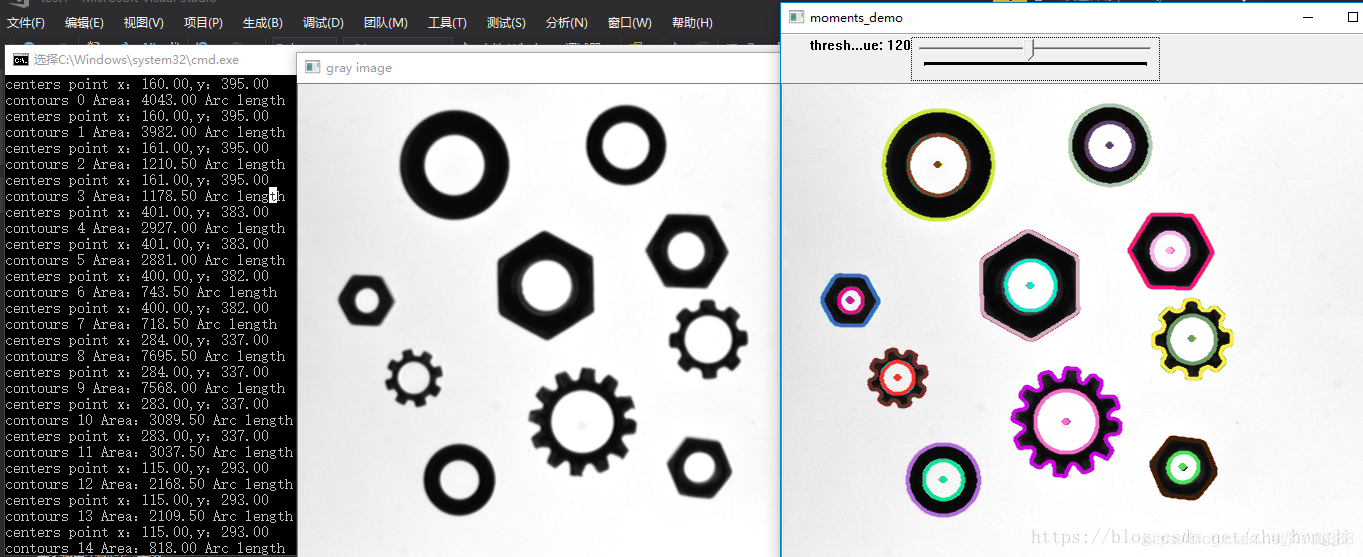
1. OpenCV轮廓提取概念
轮廓提取是计算机视觉和图像处理中的一个重要过程,它能够从数字图像中检测和描绘出物体的边界。在OpenCV库中,轮廓提取功能是通过专门的函数实现的,它能够帮助开发人员识别图像中的物体形状,为后续的图像分析和理解提供基础。
轮廓提取不仅仅是一种简单的边缘检测技术,更是一种可以提取出物体结构信息的强大工具。通过对轮廓进行分析,可以实现许多高级的应用,例如物体识别、特征提取、形状分析等。
本章将首先介绍轮廓提取的基本概念,然后再逐步深入到具体的应用细节和高级技术中,帮助读者建立一个清晰而全面的理解。我们将从轮廓提取的基本原理讲起,逐步过渡到OpenCV中的实际操作和高级应用。
2. findContours 函数应用
2.1 findContours 函数概述
2.1.1 函数功能介绍
findContours 是OpenCV库中的一个重要函数,用于从二值图像中查找轮廓。轮廓可以理解为在图像中形成封闭区域的像素的连续序列,它可以用来识别物体形状、大小和位置等信息。 findContours 函数不仅能找到这些轮廓,还能根据轮廓构建一系列的层次结构信息,便于后续对轮廓进行分析和处理。
2.1.2 函数的输入输出参数
该函数有两个输入参数和三个输出参数。输入参数包括一个二值图像和轮廓检索模式,输出参数是轮廓列表、轮廓的层次结构以及可选的,用于存储轮廓点坐标的向量。轮廓提取是计算机视觉和图像处理中非常常见的操作,广泛用于对象检测、跟踪、识别等任务。
2.2 findContours 函数使用场景
2.2.1 图像类型对提取结果的影响
findContours 函数在提取轮廓时,对于不同类型的图像,提取的效果会有所不同。通常情况下,二值图像更适合使用该函数。如果直接应用于灰度图像或彩色图像,提取效果往往不理想。因此,图像预处理步骤中的二值化处理是必不可少的,二值化后的图像黑白分明,更容易提取到准确的轮廓。
2.2.2 图像预处理对轮廓提取的重要性
图像预处理是为了提高轮廓提取准确度和效率而进行的操作。对于 findContours 函数来说,图像预处理尤为重要。常见的预处理步骤包括去噪、滤波、边缘增强等。特别是二值化处理,它能够将图像转换为只有前景(物体)和背景的简单结构,对于轮廓的准确提取至关重要。合适的预处理可以使得 findContours 函数在提取轮廓时更加高效和准确。
import cv2
# 读取原始图像
original_image = cv2.imread('path_to_image.jpg')
# 转换为灰度图像
gray_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2GRAY)
# 使用阈值方法进行二值化
_, binary_image = cv2.threshold(gray_image, 127, 255, cv2.THRESH_BINARY)
# 找到轮廓
contours, hierarchy = cv2.findContours(binary_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 遍历轮廓并绘制
for contour in contours:
cv2.drawContours(original_image, [contour], -1, (0, 255, 0), 3)
# 显示图像
cv2.imshow('Contours', original_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述代码中,首先读取原始图像,然后将其转换为灰度图像。接着使用 cv2.threshold 函数对图像进行二值化处理,其中 127 是阈值, 255 是二值化后的最大像素值, cv2.THRESH_BINARY 是二值化类型。 findContours 函数用于找到轮廓,最后通过 cv2.drawContours 函数将轮廓绘制在原始图像上并显示。
这个例子展示了从读取图像到预处理,再到轮廓提取和显示的完整流程,是 findContours 函数应用的典型使用场景。
3. 二值化处理方法
二值化是图像处理中的一项基本技术,它通过设定一个阈值将图像上的像素点的灰度值设置为0或255(对于8位的灰度图像而言),从而实现将图像简化为只有两种颜色(通常是黑色和白色)的表示形式。这种方法在去除图像噪声、简化数据复杂度以及突出感兴趣的区域方面具有很大的优势。下面将详细介绍二值化处理的原理、意义、阈值设置及实践中的技巧。
3.1 二值化图像处理概述
3.1.1 二值化原理和意义
二值化处理的核心原理是确定一个合适的阈值,然后对每个像素点进行判断。如果像素点的灰度值高于阈值,就将其设为白色(255),否则设为黑色(0)。这个过程可以用下面的公式简要表示:
B(x, y) = {
255 if I(x, y) > T
0 otherwise
}
其中,B(x, y)是二值化后的图像,I(x, y)是原图像,T是设置的阈值。
二值化处理的意义在于,它能够大幅减少图像数据的复杂度,这在进行图像分析和特征提取时尤其有用。例如,在文字识别(OCR)中,将文本图像二值化可以更容易地分割文字和背景,提高识别准确性。此外,二值化也常作为图像分割、边缘检测等后续处理步骤的前期准备。
3.1.2 二值化中的阈值设置
阈值的设置是二值化过程中最为关键的部分。不同的应用场景对阈值的选取有不同的要求。一般来说,可以手动设定阈值,也可以通过算法自动计算。
手动设定阈值时,通常需要根据图像的特性及处理目标来进行调整。例如,在进行文本图像二值化时,可能需要根据文字和背景的对比度手动选取一个合适的阈值。
自动计算阈值的方法主要有两种:全局阈值和自适应阈值。全局阈值将整个图像看作一个整体来选取阈值,适用于图像的亮度比较均匀的情况。而自适应阈值根据图像上每个像素点邻域内的亮度信息来计算阈值,这适用于图像亮度不均的情况。
3.2 二值化操作的实践技巧
3.2.1 选择合适的阈值方法
在实际操作中,选择合适的阈值方法是提高二值化效果的关键。以下是几种常见的阈值方法及其适用场景:
- 全局阈值(Global Thresholding) :适用于图像中前景和背景对比度较高的情况。
- 自适应阈值(Adaptive Thresholding) :适用于图像中亮度不均匀的情况,可以有效避免因亮度不均导致的误分割。
- Otsu's Thresholding :一种自动阈值方法,根据图像的直方图来确定最佳阈值。
接下来,我们可以通过一个简单的Python代码示例来演示如何使用OpenCV库进行全局阈值二值化操作。
import cv2
import numpy as np
# 读取图像
image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 应用全局阈值
_, binary_image = cv2.threshold(image, 128, 255, cv2.THRESH_BINARY)
# 显示原图像和二值化后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Binary Image', binary_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个示例中,我们首先读取一张灰度图像,然后使用 cv2.threshold 函数进行全局阈值二值化。 cv2.threshold 的第一个参数是输入图像,第二个参数是阈值,第三个参数是最大值(在这里设置为255),最后一个参数是阈值类型,这里我们使用 cv2.THRESH_BINARY ,表示超过阈值的像素点设为255,否则设为0。
3.2.2 避免二值化过程中的常见问题
在进行二值化处理时,会遇到一些常见的问题,比如由于噪声导致的误分割、因图像亮度不均而难以选取合适的阈值等。为了提高二值化的效果,我们可以采取以下策略:
- 图像预处理 :在二值化之前对图像进行去噪和增强处理,可以使用中值滤波去除随机噪声,或者使用直方图均衡化来提高图像的整体对比度。
- 阈值方法选择 :根据图像的具体情况灵活选择阈值方法。例如,在图像亮度不均的场合,可以使用自适应阈值方法。
- 多阈值二值化 :在某些应用中,一个阈值可能无法同时满足前景和背景的提取,此时可以采用多阈值二值化,分别对前景和背景进行处理。
下表展示了不同二值化方法在处理含有噪声的图像时的效果对比:
| 方法 | 描述 | 适用场景 | |--------|-------------------------|------------------------------------------| | 全局阈值 | 为整个图像设定一个固定的阈值 | 图像前景和背景对比度较高时适用。 | | 自适应阈值 | 根据局部区域的亮度信息动态设定阈值 | 图像亮度不均时适用,但计算量较大,可能会使边缘模糊。 | | Otsu法 | 自动计算最佳阈值 | 当前景色和背景对比度未知,需要自动确定阈值时适用。 |
通过本节的内容,我们对二值化处理的基本概念、原理以及实际应用中的技巧有了初步了解。在后续章节中,我们将进一步深入探讨轮廓提取的参数配置、内外边缘提取策略以及实际应用案例,以期掌握在各种复杂情况下进行高效准确轮廓提取的综合技能。
4. 轮廓提取参数配置
轮廓提取是计算机视觉中一个重要的步骤,它帮助我们从图像中分离出想要研究的对象。参数配置在这一过程中起着至关重要的作用。本章将详细解析轮廓提取中常用的参数,并展示如何通过实践操作来调优这些参数以达到最佳的提取效果。
4.1 轮廓提取中的参数解析
4.1.1 轮廓检索模式
轮廓检索模式决定了在 findContours 函数中如何处理轮廓的父子关系。在OpenCV中,轮廓检索模式有三种:
-
RETR_EXTERNAL:仅检索最外围轮廓。 -
RETR_LIST:检索所有轮廓,并将其组织为一个列表,不保存父子关系。 -
RETR_CCOMP:检索所有轮廓,并将它们组织为两层:第一层是整个轮廓的顶层,第二层是那些连接到顶层轮廓的洞的列表。
选择不同的检索模式会导致不同的结果,这取决于我们想要提取轮廓的类型。
4.1.2 轮廓近似方法
轮廓近似方法用于简化轮廓,通过指定精度来近似原始轮廓。在OpenCV中,使用 cv2.arcLength() 函数进行轮廓近似时可以指定参数 epsilon 来控制精度,该参数决定了轮廓简化时每个顶点到轮廓线的最大距离。
-
epsilon设置较大时,轮廓简化更多,提取的轮廓线条更加平滑。 -
epsilon设置较小时,轮廓的细节更多,但可能导致轮廓线条出现不必要的抖动。
4.2 参数调优的实践操作
4.2.1 参数调整对结果的影响
参数的微小变化可能会对轮廓提取的结果产生显著影响。例如,对于边缘平滑度的处理,如果 epsilon 值过小,可能会保留太多的细节,导致轮廓过于复杂;如果值过大,则可能会过度简化轮廓,丢失重要的特征点。
在实际应用中,我们通常会通过观察提取的轮廓与原始图像的匹配程度,不断调整 epsilon 值,以达到最佳的轮廓近似效果。
4.2.2 精细调整参数的策略
在进行参数调整时,一个重要的策略是采用迭代的方法。首先可以使用一个粗略的 epsilon 值进行轮廓近似,然后逐渐调整该值直到获得满意的结果。
例如,可以在代码中设置一个参数调整循环:
# 假设已经获取了轮廓contours
for epsilon in range(10, 20): # epsilon的初始值
approx = cv2.approxPolyDP(contours, epsilon / 100.0, True)
if len(approx) == 4: # 假设我们想要四边形
break
在上面的代码块中,我们通过不断减少 epsilon 值来精细调整轮廓。由于 epsilon 值在 cv2.approxPolyDP() 函数中被除以100.0,我们可以通过逐渐增加epsilon的范围来细化轮廓。
请注意,本章节仅提供了轮廓提取参数配置的基础知识和实践操作。在实际应用中,参数的调整需要根据具体的图像内容和目标对象的特征来进行。接下来的章节将继续深入探讨如何通过代码实现轮廓提取,并分析提取结果。
5. 外边缘与内边缘提取策略
5.1 外边缘与内边缘概念区分
5.1.1 外边缘和内边缘的定义
在图像处理中,外边缘(Outer Edge)通常指的是对象的最外围轮廓,而内边缘(Inner Edge)则指对象内部的轮郭边界。这两种边缘提取对于理解对象的结构、形状和特征至关重要。外边缘提取有助于我们获取对象的尺寸、位置和方向,而内边缘则能够提供对象内部结构的详细信息,这对于进行更高级的图像分析和识别非常重要。
5.1.2 提取方法的不同应用场景
外边缘和内边缘提取的应用场景不同。例如,在工业视觉检测中,外边缘提取可能用于检测零件的轮廓完整性,而内边缘提取则可能用于识别零件的内部结构缺陷。在医疗图像分析中,外边缘可以帮助医生识别肿瘤或器官的大小和形状,而内边缘则可以用于分析细胞结构或血管网络。
5.2 多边缘提取技术的应用
5.2.1 子轮廓的提取和分析
在复杂图像中,对象可能包含多个子轮廓。为了准确分析这些子轮廓,我们需要采用多边缘提取技术。通过子轮廓的提取和分析,我们可以对每个独立区域进行研究,这在图像分割和对象识别中非常重要。例如,在字符识别中,每个字符的封闭轮廓可以作为子轮廓进行分析,以提高识别的准确性。
import cv2
import numpy as np
# 读取图像
image = cv2.imread('complex_image.png')
# 转换为灰度图像并应用二值化处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 使用findContours找到所有子轮廓
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 遍历并分析每个子轮廓
for i, contour in enumerate(contours):
# 计算子轮廓的边界框
x, y, w, h = cv2.boundingRect(contour)
# 标记边界框并显示
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 打印子轮廓的面积
print(f"Sub contour {i} area: {cv2.contourArea(contour)}")
# 显示结果图像
cv2.imshow('Sub Contours', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.2.2 轮廓链的构建和操作
轮廓链(Contour Chain)是一种通过有序排列的点集合来表示对象边界的方法。在OpenCV中,可以通过 findContours 函数获取轮廓链。轮廓链的构建对于理解对象的拓扑结构和几何属性至关重要。通过操作轮廓链,可以进行轮廓平滑、拟合或顶点提取等高级处理。
下面是一个使用轮廓链操作的例子:
import cv2
# 读取图像
image = cv2.imread('object_image.png', cv2.IMREAD_GRAYSCALE)
# 应用Canny边缘检测
edges = cv2.Canny(image, 100, 200)
# 找到边缘轮廓链
contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个空白图像用于绘制
blank_image = np.zeros_like(image)
# 遍历每个轮廓链并绘制
for i, contour in enumerate(contours):
# 使用轮廓链创建掩码
mask = np.zeros_like(image)
cv2.drawContours(mask, [contour], -1, 255, thickness=cv2.FILLED)
# 掩码与原始图像叠加得到高亮轮廓的图像
highlighted_contour = cv2.bitwise_and(image, image, mask=mask)
# 显示当前轮廓链处理结果
cv2.imshow(f'Contour Chain {i}', highlighted_contour)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这段代码中,我们首先读取一张图像,并应用Canny边缘检测来找到边缘轮廓链。然后,我们对每个轮廓链进行迭代,创建一个掩码,使用 drawContours 函数绘制每个轮廓链。最后,我们通过 bitwise_and 函数将掩码应用到原始图像上,以显示每个轮廓链的高亮效果。这有助于我们更清晰地理解图像中每个轮廓的结构和形状。
6. 示例代码实现轮廓提取
6.1 实现轮廓提取的步骤和代码示例
在实际开发中,轮廓提取的实现需要遵循一定的步骤,并且通常会涉及到对图像的预处理操作。以下是一个简单的示例,展示如何使用OpenCV进行轮廓提取的步骤和相应的代码示例。
6.1.1 图像预处理代码逻辑
在调用 findContours 函数之前,我们通常需要对图像进行一些预处理操作,如灰度化、二值化等,以优化轮廓提取的效果。
import cv2
import numpy as np
# 读取图像
image = cv2.imread('path_to_image')
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊,减少噪声和细节
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 二值化图像
_, binary = cv2.threshold(blurred, 127, 255, cv2.THRESH_BINARY)
6.1.2 findContours 函数调用和参数配置
在预处理之后,我们可以调用 findContours 函数来提取图像轮廓。我们需要合理配置函数的参数,以获得最佳的提取效果。
# 查找轮廓
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制轮廓
contour_image = image.copy()
cv2.drawContours(contour_image, contours, -1, (0, 255, 0), 3)
# 展示结果图像
cv2.imshow('Contours', contour_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
6.2 轮廓提取结果的分析和优化
通过上述步骤和代码示例,我们可以实现轮廓提取的基本操作。接下来需要对提取出的轮廓进行分析,并根据分析结果进行优化。
6.2.1 结果展示与分析
执行上述代码后,会弹出一个窗口显示了提取的轮廓。我们可以分析这些轮廓与原图的关系,以及它们是否符合我们的预期。
6.2.2 优化建议和扩展应用
在实际应用中,可能需要对提取结果进行进一步的处理,比如根据轮廓面积过滤噪声、提取特定形状或大小的对象等。
# 过滤小轮廓
min_area = 100
filtered_contours = [cnt for cnt in contours if cv2.contourArea(cnt) > min_area]
# 再次绘制优化后的轮廓
contour_image_optimized = image.copy()
cv2.drawContours(contour_image_optimized, filtered_contours, -1, (0, 0, 255), 3)
# 展示优化后的结果图像
cv2.imshow('Optimized Contours', contour_image_optimized)
cv2.waitKey(0)
cv2.destroyAllWindows()
通过这样的分析和优化,我们可以获得更加精确和有用的轮廓信息,为后续处理或分析奠定良好的基础。
简介:OpenCV是计算机视觉领域中用于图像处理和分析的开源库。在本示例中,我们将深入探讨如何使用OpenCV进行轮廓提取,包括理解轮廓的定义、 findContours 函数的使用、二值化处理、参数设置以及如何选择提取外边缘或内边缘的策略。示例中将通过Python代码展示提取轮廓的过程,并讨论轮廓提取在不同领域的应用实例,如机器人导航、自动驾驶等。















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









