






这几天打算看下安卓的代码,看优秀的源代码也是一种学习过程,看源代码的过程就感觉到,安卓确实是深受linux内核的影响,不少数据结构的使用方法全然一致。花了一中午时间,研究了下init.rc解析过程,做个记录。
init.rc 文件并非普通的配置文件。而是由一种被称为“Android初始化语言”(Android Init Language。这里简称为AIL)的脚本写成的文件。在了解init怎样解析init.rc文件之前,先了解AIL很必要。否则机械地分析 init.c及其相关文件的源码毫无意义。
为了学习AIL,读者能够到自己Android手机的根文件夹寻找init.rc文件。最好下载到本地以便查看,假设有编译好的Android源码。 在<Android源码根文件夹>out/target/product/generic/root文件夹也可找到init.rc文件。
AIL由例如以下4部分组成。
1. 动作(Actions)
2. 命令(Commands)
3. 服务(Services)
4. 选项(Options)
这4部分都是面向行的代码,也就是说用回车换行符作为每一条语句的分隔符。而每一行的代码由多个符号(Tokens)表示。能够使用反斜杠转义符在 Token中插入空格。双引號能够将多个由空格分隔的Tokens合成一个Tokens。假设一行写不下,能够在行尾加上反斜杠。来连接下一行。也就是 说,能够用反斜杠将多行代码连接成一行代码。
AIL的凝视与非常多Shell脚本一行。以#开头。
AIL在编写时须要分成多个部分(Section)。而每一部分的开头须要指定Actions或Services。也就是说。每个Actions或 Services确定一个Section。
而全部的Commands和Options仅仅能属于近期定义的Section。假设Commands和 Options在第一个Section之前被定义,它们将被忽略。
Actions和Services的名称必须唯一。假设有两个或多个Action或Service拥有相同的名称。那么init在运行它们时将抛出错误,并忽略这些Action和Service。
以下来看看Actions、Services、Commands和Options分别应怎样设置。
Actions的语法格式例如以下:
on <trigger>
<command>
<command>
<command>也就是说Actions是以keywordon开头的。然后跟一个触发器,接下来是若干命令。比如。以下就是一个标准的Action。
on boot
ifup lo
hostname localhost
domainname localdomain Services (服务)是一个程序,他在初始化时启动,并在退出时重新启动(可选)。Services (服务)的形式例如以下:
service <name> <pathname> [ <argument> ]*
<option>
<option>比如,以下是一个标准的Service使用方法
service servicemanager /system/bin/servicemanager
class core
user system
group system
critical
onrestart restart zygote
onrestart restart media
onrestart restart surfaceflinger
onrestart restart drm 如今接着分析一下init是怎样解析init.rc的。如今打开system/core/init/init.c文件,找到main函数。
在上一篇文章中 分析了main函数的前一部分(初始化属性、处理内核命令行等),如今找到init_parse_config_file函数,调用代码例如以下:
init_parse_config_file("/init.rc");
这种方法主要负责初始化和分析init.rc文件。init_parse_config_file函数在init_parser.c文件里实现,代码例如以下:
int init_parse_config_file(const char *fn)
{
char *data;
data = read_file(fn, 0);
if (!data) return -1;
/* 实际分析init.rc文件的代码 */
parse_config(fn, data);
DUMP();
return 0;
} 读取文件read_file有个地方须要注意:它把init.rc内容读取到data指向的buffer其中。它会在buffer最后追加两个字符:\n和\0。而且在linux系统须要注意的是,每行的结束唯独一个字符\n。
static void parse_config(const char *fn, char *s)
{
struct parse_state state;
struct listnode import_list;
struct listnode *node;
char *args[INIT_PARSER_MAXARGS];
int nargs;
nargs = 0;
state.filename = fn;
state.line = 0;
state.ptr = s;
state.nexttoken = 0;
state.parse_line = parse_line_no_op;
list_init(&import_list);
state.priv = &import_list;
/* 開始获取每个token,然后分析这些token,每个token就是有空格、字表符和回车符分隔的字符串
*/
for (;;) {
/* next_token函数相当于词法分析器 */
switch (next_token(&state)) {
case T_EOF: /* init.rc文件分析完成 */
state.parse_line(&state, 0, 0);
goto parser_done;
case T_NEWLINE: /* 分析每一行的命令 */
/* 以下的代码相当于语法分析器 */
state.line++;
if (nargs) {
int kw = lookup_keyword(args[0]);
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;
}
break;
case T_TEXT: /* 处理每个token */
if (nargs < INIT_PARSER_MAXARGS) {
args[nargs++] = state.text;
}
break;
}
}
parser_done:
/* 最后处理由import导入的初始化文件 */
list_for_each(node, &import_list) {
struct import *import = node_to_item(node, struct import, list);
int ret;
INFO("importing '%s'", import->filename);
/* 递归调用 */
ret = init_parse_config_file(import->filename);
if (ret)
ERROR("could not import file '%s' from '%s'\n",
import->filename, fn);
}
} parse_config的代码比較复杂了。如今先说说该方法的基本处理流程。首先会调用list_init(&import_list)初始化一个链表。该链表用于存储通过import语句导入的初始化文件名称。
然后開始在for循环中分析init.rc文件里的每一行代码。最后init.rc分析完之后,就会进入parse_done部分,并递归调用init_parse_config_file方法分析通过import导入的初始化文件。
for循环中调用next_token不断从init.rc文件里获取token,这里的token,就是一种编程语言的最小单位,也就是不可再分。比如,对于传统的编程语言的if、then等keyword、变量名等标识符都属于一个token。而对于init.rc文件来说,import、on以及触发器的參数值都是属于一个token。一个解析器要进行语法和词法的分析,词法分析就是在文件里找出一个个的token。也就是说,词法分析器的返回值是token,而语法分析器的输入就是词法分析器的输出。也就是说,语法分析器就须要分析一个个的token,而不是一个个的字符。词法分析器就是next_token,而语法分析器就是T_NEWLINE分支中的代码。以下我们来看看next_token是怎么获取一个个的token的。
int next_token(struct parse_state *state)
{
char *x = state->ptr;
char *s;
if (state->nexttoken) {
int t = state->nexttoken;
state->nexttoken = 0;
return t;
}
/* 在这里開始一个字符一个字符地分析 */
for (;;) {
switch (*x) {
case 0:
state->ptr = x;
return T_EOF;
case '\n':
x++;
state->ptr = x;
return T_NEWLINE;
case ' ':
case '\t':
case '\r':
x++;
continue;
case '#':
while (*x && (*x != '\n')) x++;
if (*x == '\n') {
state->ptr = x+1;
return T_NEWLINE;
} else {
state->ptr = x;
return T_EOF;
}
default:
goto text;
}
}
textdone:
state->ptr = x;
*s = 0;
return T_TEXT;
text:
state->text = s = x;
textresume:
for (;;) {
switch (*x) {
case 0:
goto textdone;
case ' ':
case '\t':
case '\r':
x++;
goto textdone;
case '\n':
state->nexttoken = T_NEWLINE;
x++;
goto textdone;
case '"':
x++;
for (;;) {
switch (*x) {
case 0:
/* unterminated quoted thing */
state->ptr = x;
return T_EOF;
case '"':
x++;
goto textresume;
default:
*s++ = *x++;
}
}
break;
case '\\':
x++;
switch (*x) {
case 0:
goto textdone;
case 'n':
*s++ = '\n';
break;
case 'r':
*s++ = '\r';
break;
case 't':
*s++ = '\t';
break;
case '\\':
*s++ = '\\';
break;
case '\r':
/* \ <cr> <lf> -> line continuation */
if (x[1] != '\n') {
x++;
continue;
}
case '\n':
/* \ <lf> -> line continuation */
state->line++;
x++;
/* eat any extra whitespace */
while((*x == ' ') || (*x == '\t')) x++;
continue;
default:
/* unknown escape -- just copy */
*s++ = *x++;
}
continue;
default:
*s++ = *x++;
}
}
return T_EOF;
} 假设一行结束,就返回T_NEWLINE。并開始语法分析,
特别注意:init初始化语言是基于行的,所以语言分析实际上就是分析init.rc的每一行,仅仅是这些行已经被分解成一个个的token并保存在args数组其中。如今回到parse_config函数。先看一下T_TEXT分支。
该分支讲获得每一行的token都存储在args数组中。如今来看T_NEWLINE分支。
该分支的代码涉及到一个state.parse_line函数指针,该函数指针指向的函数负责详细的分析工作。但我们发现,一看是该函数指针指向了一个空函数。实际上一開始该函数什么都不做。
如今来回想一下T_NEWLINE分支的完整代码
case T_NEWLINE:
state.line++;
if (nargs) {
int kw = lookup_keyword(args[0]);
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;
}
break;void parse_new_section(struct parse_state *state, int kw,
int nargs, char **args)
{
printf("[ %s %s ]\n", args[0],
nargs > 1 ? args[1] : "");
switch(kw) {
case K_service: // 处理service
state->context = parse_service(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_service;
return;
}
break;
case K_on: // 处理action
state->context = parse_action(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_action;
return;
}
break;
case K_import: // 单独处理import导入的初始化文件。parse_import(state, nargs, args); break; } state->parse_line = parse_line_no_op; }
我们拿case K_service举例:首先调用parse_service函数,该函数代码例如以下:
static void *parse_service(struct parse_state *state, int nargs, char **args)
{
struct service *svc;
if (nargs < 3) {
parse_error(state, "services must have a name and a program\n");
return 0;
}
if (!valid_name(args[1])) {
parse_error(state, "invalid service name '%s'\n", args[1]);
return 0;
}
svc = service_find_by_name(args[1]);
if (svc) {
parse_error(state, "ignored duplicate definition of service '%s'\n", args[1]);
return 0;
}
nargs -= 2;
svc = calloc(1, sizeof(*svc) + sizeof(char*) * nargs);
if (!svc) {
parse_error(state, "out of memory\n");
return 0;
}
svc->name = args[1];
svc->classname = "default";
memcpy(svc->args, args + 2, sizeof(char*) * nargs);
svc->args[nargs] = 0;
svc->nargs = nargs;
svc->onrestart.name = "onrestart";
list_init(&svc->onrestart.commands);
list_add_tail(&service_list, &svc->slist);
return svc;
}可是svc的args数组仅仅须要保存/system/bin/dumpstate -s这两个參数就好了!!
然后会又一次设置state->parse_line,比方对于service的section解析来说,state->parse_line = parse_line_service;这样就会调用parse_line_service解析services的options。
没有图像的分析总显得不够直观,以下使用详细样例说明在运行完成parse_service和parse_line_service时的组织结构图:
service zygote ....
onrestart write /sys/android..
onrestart write /sys/power..
onrestart restart media
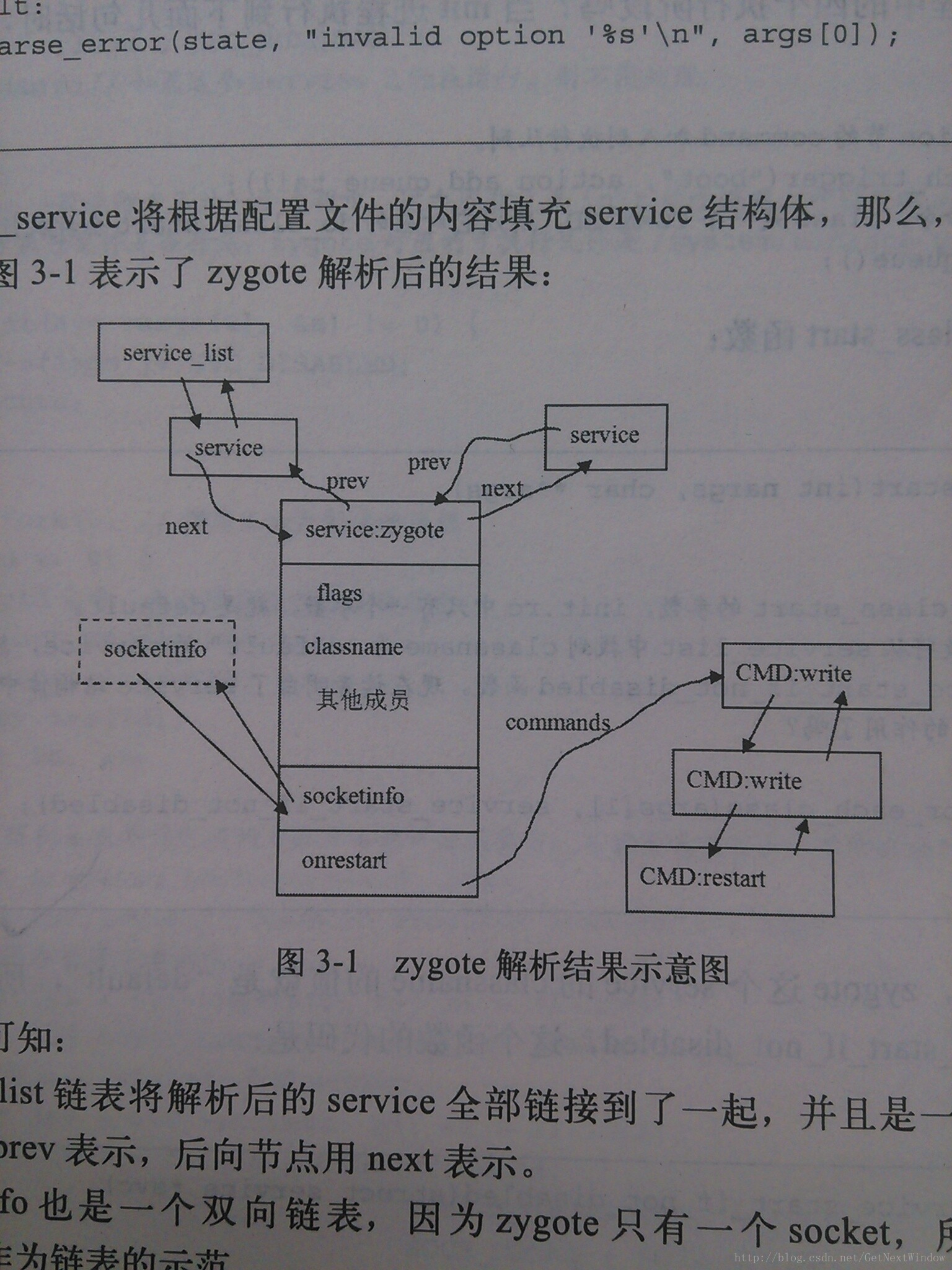
图片取自《深入理解安卓》一书。
从上图可知:
1)service_list链表解说析之后的service所有链接到一起。而且是双向链表
2)onrestart通过commands也构造一个双向链表,假设service以下具有onrestart的option,那么会将选项挂接到onrestart其中的链表其中。
















 4019
4019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









