







1.storm编程实现wordcount的详细流程分析
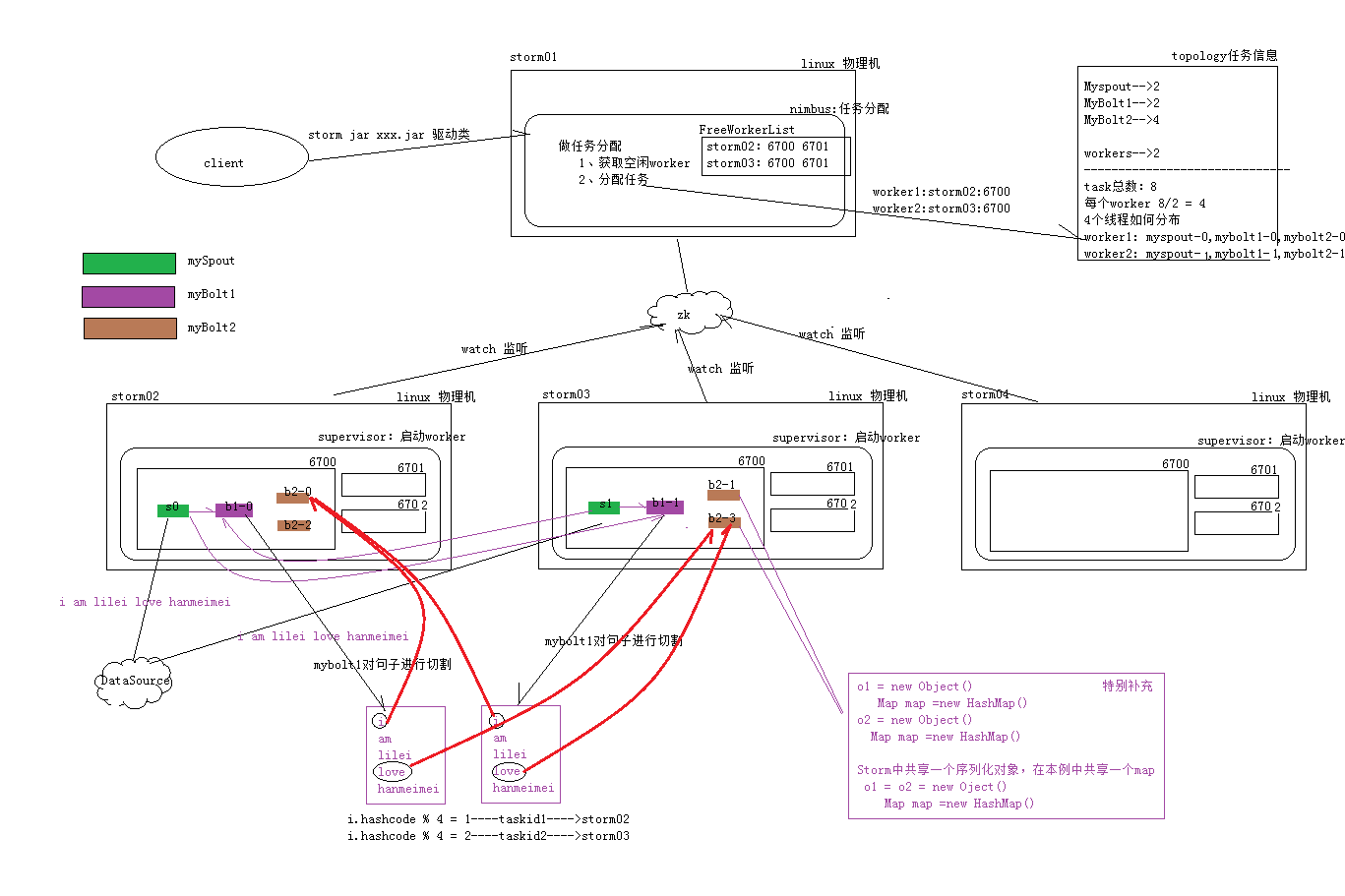
2.代码实现
本例以实现storm版的wordcount
WordCountTopologMain.java
public class WordCountTopologMain
{
public static void main(String[] args)
{
// 1.创建topology
TopologyBuilder topology = new TopologyBuilder();
// 设置spout和bolt以及并发度,myspout只是别名,spout分发数据到bolt
topology.setSpout("mySpout", new MySpout(), 2);
// 此时自设了两个Bolt,
/**
* mybolt1数据分组策略是随机分发数据到介质(下游bolt或者redis等)
*
* mybolt2数据分组策略是分组合并数据,
*/
topology.setBolt("mybolt1", new MySplitBolt(), 2).shuffleGrouping("mySpout");
topology.setBolt("mybolt2", new MyCountBolt(), 4).fieldsGrouping("mybolt1", new Fields("word"));
// 2.创建configuration,指定当前topology 需要的woker数量
Config config = new Config();
config.setNumWorkers(2);
// 3.选择本地模式还是集群模式
try
{
StormSubmitter.submitTopology("storm_wordcount", config, topology.createTopology());
}
catch (AlreadyAliveException | InvalidTopologyException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("storm_wordcount", config, topology.createTopology());
}
}
MySpout.java
/**
* @ClassName MySpout
* @author liukang
* @Description TODO spout是获取外部数据
* @version 1.0.0
*/
public class MySpout extends BaseRichSpout
{
SpoutOutputCollector outputCollector;
/**
* 初始化方法
*/
@Override
public void open(Map conf, TopologyContext arg1, SpoutOutputCollector outputCollector)
{
this.outputCollector = outputCollector;
}
/**
* storm框架内while(true)调用tuple方法,传送数据
*/
@Override
public void nextTuple()
{
/**
* public Values(Object... vals)
* {
* super(vals.length);
* for(Object o: vals)
* {
* add(o);
* }
* }
*/
outputCollector.emit(new Values("you are my apple in my eye"));
}
/**
* 声明tuple单元数据的别名,可以是多个,取决于nexttuple方法设的输出结果
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
declarer.declare(new Fields("word"));
}
}
MySplitBolt.java
/**
* @ClassName MySplitBolt
* @author liukang
* @Description TODO Bolt是逻辑处理节点,相当于Mapreduce中的map阶段功能相同,单词切割
* 接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上
* @version 1.0.0
*/
public class MySplitBolt extends BaseRichBolt
{
OutputCollector collector;
/**
* 初始化
*/
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector)
{
this.collector = collector;
}
/*
* 执行线程,执行bolt任务,tuple是最小的数据单元
*/
@Override
public void execute(Tuple tuple)
{
// 在本例中,spout只发送了一组数据过来
/**
* public String getString(int i) { return (String) values.get(i); }
*/
String line = tuple.getString(0);
// 切割
String[] words = line.split(" ");
for (String word : words)
{
// 将数据片tuple输出到下游Bolt继续处理
collector.emit(new Values(word, 1));
}
}
/*
* 告诉下游的bolt此次bolt输出的结果别名
*
* @see backtype.storm.topology.IComponent#declareOutputFields(backtype.storm.topology.OutputFieldsDeclarer)
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
/*
* 可变数组
* public Fields(String... fields) {
* this(Arrays.asList(fields));
* }
*/
declarer.declare(new Fields("wordinfo","number"));
}
}
MyCountBolt.java
public class MyCountBolt extends BaseRichBolt
{
OutputCollector collector;
Map<String, Integer> map = new HashMap<String, Integer>();
/*
* 初始化 :
*
* @see backtype.storm.task.IBolt#prepare(java.util.Map, backtype.storm.task.TopologyContext,
* backtype.storm.task.OutputCollector)
*/
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector)
{
this.collector = collector;
}
/*
* 接受上游的bolt数据,进行逻辑处理 :
*
* @see backtype.storm.task.IBolt#execute(backtype.storm.tuple.Tuple)
*/
@Override
public void execute(Tuple tuple)
{
// 本例中上游mybolt1输出两个结果,别名分别是wordinfo 和number
String wordinfo = tuple.getString(0);
Integer number = tuple.getInteger(1);
// 判断单词
if (map.containsKey(wordinfo))
{
Integer count = map.get(wordinfo);
map.put(wordinfo, number + count);
}
else
{
map.put(wordinfo, number);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0)
{
// Bolt最终,不输出结果
}
}















 2082
2082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









