






# 在平时的爬虫中,如果遇到没有局部刷新,没有字体加密,右键检查也能看到清晰的数据,但是按照已经制定好的解析规则进行解析时,会返回空数据,这是为什么呢,这时可以在网页右键查看一下网页源代码,可以发现,在网页上的源代码中有些部分是正确的,有些标签是不正确的,改了名字或者加了数字,或者不是你在网页上检查看到的标签名,所以如果你按照网页上的解析规则去解析, 是解析不到的,这时就要按照网页源代码的解析规则去解析了,这就是典型的网页懒加载。
# 什么是网页懒加载?
# 网页懒加载是前端为了提高网页访问速度,将页面内没有出现在可视区域内的图片先不做加载,等到手动滑动鼠标滚动到可视区域后再加载。这样对于网页加载性能上会有很大的提升,懒加载的效果就可以提升用户体验。
import requests
from pyquery import PyQuery as pq
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'http://sc.chinaz.com/tupian/fengjingtupian.html'
r = requests.get(url=url,headers = headers)
r.encoding = r.apparent_encoding
demo = r.text
soup = pq(demo)
src = soup('.box.picblock.col3 img')
for i in src:
i = pq(i)
i = i.attr('src2')
print(i)
print(len(src))
选取了站长之家作为目标站点
右键检查看到的标签
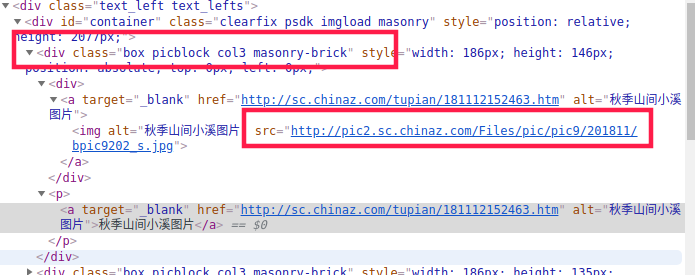
实际爬取下来的网页源代码

按照这个解析规则,一般就能正确的解析出来需要的内容了。















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









