







今天遇到一个hive的问题,如下hive sql:
select f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802)
该语句中B表有30亿行记录,A表只有100行记录,而且B表中数据倾斜特别严重,有一个key上有15亿行记录,在运行过程中特别的慢,而且在reduece的过程中遇有内存不够而报错。
为了解决用户的这个问题,考虑使用mapjoin,mapjoin的原理:
MapJoin简单说就是在Map阶段将小表读入内存,顺序扫描大表完成Join。
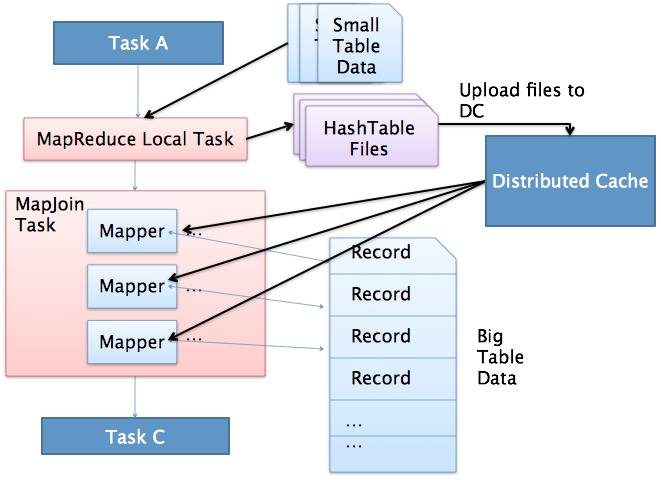
上图是Hive MapJoin的原理图,出自Facebook工程师Liyin Tang的一篇介绍Join优化的slice,从图中可以看出MapJoin分为两个阶段:
通过MapReduce Local Task,将小表读入内存,生成HashTableFiles上传至Distributed Cache中,这里会对HashTableFiles进行压缩。
MapReduce Job在Map阶段,每个Mapper从Distributed Cache读取HashTableFiles到内存中,顺序扫描大表,在Map阶段直接进行Join,将数据传递给下一个MapReduce任务。
MAPJION会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,由于在map是进行了join操作,省去了reduce运行的效率也会高很多
这样就不会由于数据倾斜导致某个reduce上落数据太多而失败。于是原来的sql可以通过使用hint的方式指定join时使用mapjoin。
select /*+ mapjoin(A)*/ f.a,f.b
from A t join B f
on ( f.a=t.a and f.ftime=20110802)
再运行发现执行的效率比以前的写法高了好多。
mapjoin还有一个很大的好处是能够进行不等连接的join操作,这种操作如果直接使用join的话语法不支持不等于操作,hive语法解析会直接抛出错误。如果把不等于写到where里会造成笛卡尔积,数据异常增大,速度会很慢。甚至会任务无法跑成功~。
根据mapjoin的计算原理,MAPJION会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配。这种情况下即使笛卡尔积也不会对任务运行速度造成太大的效率影响。
而且hive的where条件本身就是在map阶段进行的操作,所以在where里写入不等值比对的话,也不会造成额外负担。
如此看来,使用MAPJOIN开发的程序仅仅使用map一个过程就可以完成不等值join操作,效率还会有很大的提升。
例子:
select /*+ MAPJOIN(a) */ a.start_level, b.*
from dim_level a join (select * from test) b
where b.xx>=a.start_level and b.xx<end_level;
简单总结一下,mapjoin的使用场景:
1. 关联操作中有一张表非常小
2.不等值的链接操作















 2703
2703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









