







最简单容易理解的版本,我觉的是Nico Lomuto 的单向划分, c++ stl 的std::partition 就是用这个来实现的, 就是根据谓词函数的返回值,把返回true的全都调到数组的开头位置,返回false的放在尾部, 形成这两组:
package main
import (
"fmt"
"math/rand"
"time"
)
func makeRandInts(len, n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0, len)
for i := 0; i < len; i++ {
nums = append(nums, rand.Intn(n))
}
return nums
}
func Lomuto(nums []int, predict func(e int) bool) int {
len := len(nums)
m := -1
for i := 0; i < len; i++ {
if predict(nums[i]) {
m++
nums[i], nums[m] = nums[m], nums[i]
}
}
return m
}
func main() {
nums := makeRandInts(10, 100)
fmt.Printf("%+v\n", nums)
i := Lomuto(nums, func(e int) bool {
if e%2 == 0 {
return true
}
return false
})
fmt.Printf("%+v, i=%d\n", nums, i)
}
这个例子就是把所有的偶数调到开头,形成偶奇两组,循环结束时,m 指向最后一个偶数(如果存在偶数)。
快速排序的划分结束后,要达到的效果就是数组左边全是不大于枢纽元素,右边全是不小于枢纽元素,Lomuto 划分可以达到这个目的,只要改下谓词函数:
func lomuto(nums []int) int {
len := len(nums)
pivot := nums[0]
m := 0
for i := 1; i < len; i++ {
if nums[i] < pivot {
m++
nums[i], nums[m] = nums[m], nums[i]
}
}
nums[0], nums[m] = nums[m], nums[0]
return m
}
选取第一元素作为枢纽,从索引1开始扫描到末尾, nums[i] < pivot 充当了谓词函数, 所有小于pivot 的元素调在了开始位置, 结束后m 指向了最后一个小于pivot 的位置, 然后用m 指向的元素与pivot 交换, 达到了quicksort 划分过程的要求。
tony hoare 的划分是双向划分,一个指针i从左往右扫描, 另一个j从右往左扫描, 直到两个指针相遇:
func partition2Way(nums []int) int {
pivot := nums[0]
i := 0
len := len(nums)
j := len
for {
i++
j--
for nums[i] < pivot && i < len-1 {
i++
}
for pivot < nums[j] {
j--
}
if i >= j {
break
}
nums[i], nums[j] = nums[j], nums[i]
}
nums[0], nums[j] = nums[j], nums[0]
return j
}
循环开始之前, i = 0, j = len, i 的背后没有大于枢纽的元素(没有元素),j的背后没有小于枢纽的元素(没有元素), 不变量保持;循环过程中,第一小循环对应i从左往右扫描, 第二个对应j从右往左扫描,i,j 都期望不变量没有被破坏, 一旦被破坏,双方通过互换破坏元素,再次恢复不变量;Robert Sedgewick 说有过证明i, j 在扫描过程中,遇到等于枢纽的元素时, 双方都应该停止,这样划分会更均匀,所以 for 循环的条件是<, 不是<=;需要检查i 是否越界,如降序文件,j 不需要检查,最坏如升序文件, j 会停靠在最左边。
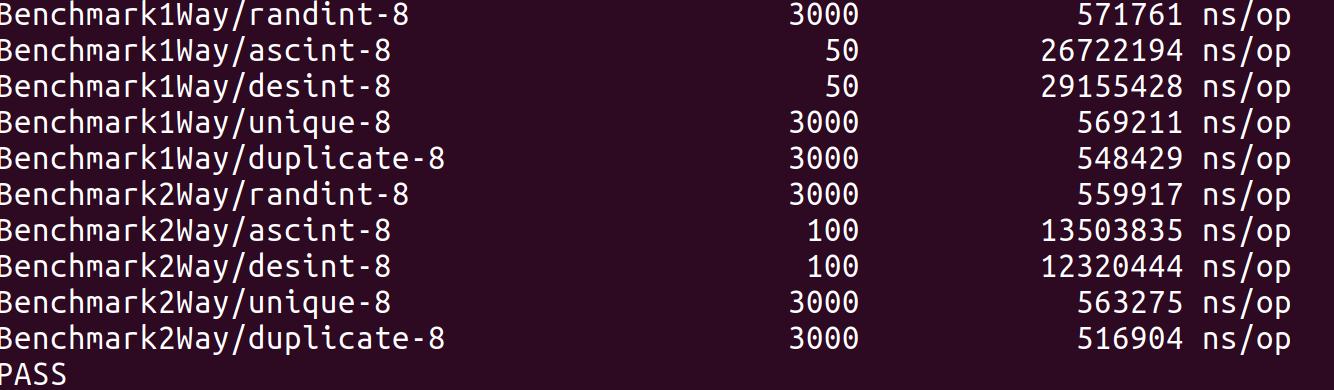
benchmark 显示双向划分好过单向划分, 当前的pivot 选取对应比较随机的文件效果不错, 但是完全升序或者降序文件效果很差, 选取index 0 作为pivot 元素,如果index 0 是最大的或者最小的元素,划分相当不均匀,一边是空文件, 一边是以前的文件大小减1, 完全升序或者降序文件,递归过程中,每次都是如此。有一些针对pivot 选取的改进: 随机抓取一个pivot; 选取一些元素采样,获得一个尽量接近数组中位数的值,作为pivot 。
func randRange(min, max int) int {
return min + myrand.Int()%(max-min+1)
}
func partition2WayRandomPivot(nums []int) int {
{
i := randRange(0, len(nums)-1)
nums[0], nums[i] = nums[i], nums[0]
}
pivot := nums[0]
i := 0
len := len(nums)
j := len
for {
i++
j--
for nums[i] < pivot && i < len-1 {
i++
}
for pivot < nums[j] {
j--
}
if i >= j {
break
}
nums[i], nums[j] = nums[j], nums[i]
}
nums[0], nums[j] = nums[j], nums[0]
return j
}

针对有序或者逆序总体有些改善, median3 对这种情况有大幅提升,选取最左边, 中间位置, 最右边三个数的中位数,交换到index 0, 作为pivot:
func partition2WayMedian3(nums []int, lo, hi int) int {
//median of 3
m := lo + (hi-lo)/2
if nums[m] < nums[lo] {
nums[m], nums[lo] = nums[lo], nums[m]
}
if nums[hi] < nums[lo] {
nums[hi], nums[lo] = nums[lo], nums[hi]
}
if nums[hi] < nums[m] {
nums[hi], nums[m] = nums[m], nums[hi]
}
nums[m], nums[lo] = nums[lo], nums[m]
pivot := nums[lo]
i := lo
j := hi + 1
for {
i++
j--
for nums[i] < pivot {
i++
}
for pivot < nums[j] {
j--
}
if i >= j {
break
}
nums[i], nums[j] = nums[j], nums[i]
}
nums[lo], nums[j] = nums[j], nums[lo]
return j
}

还有median3 的拓展Tukey的中位数的中位数
func median3(nums []int, i, j, k int) int {
if nums[i] < nums[j] {
if nums[j] < nums[k] {
return j
}
if nums[i] < nums[k] {
return k
}
return i
}
// i > j
if nums[k] < nums[j] {
return j
}
//i > j && k > j
if nums[k] < nums[i] {
return k
}
return i
}
func partition2WayMom(nums []int) {
len := len(nums)
if len >= 9 {
lo := 0
hi := len - 1
step := len / 8
mid := len / 2
m1 := median3(nums, lo, lo+step, lo+step+step)
m2 := median3(nums, mid-step, mid, mid+step)
m3 := median3(nums, hi-step-step, hi-step, hi)
mom := median3(nums, m1, m2, m3)
nums[lo], nums[mom] = nums[mom], nums[lo]
.....
.....
}
}
根据数组大小调整步长,比如使用tukey方法最小数组大小9,步长1,index 0,1,2 之间找出中位数的index m1, 在index 3,4,5 中找到中位数的index m2, 在index 6,7,8中找到中位数的index m3, 三个中位数的中位数的位置mom, 然后交换到最左边作为pivot。
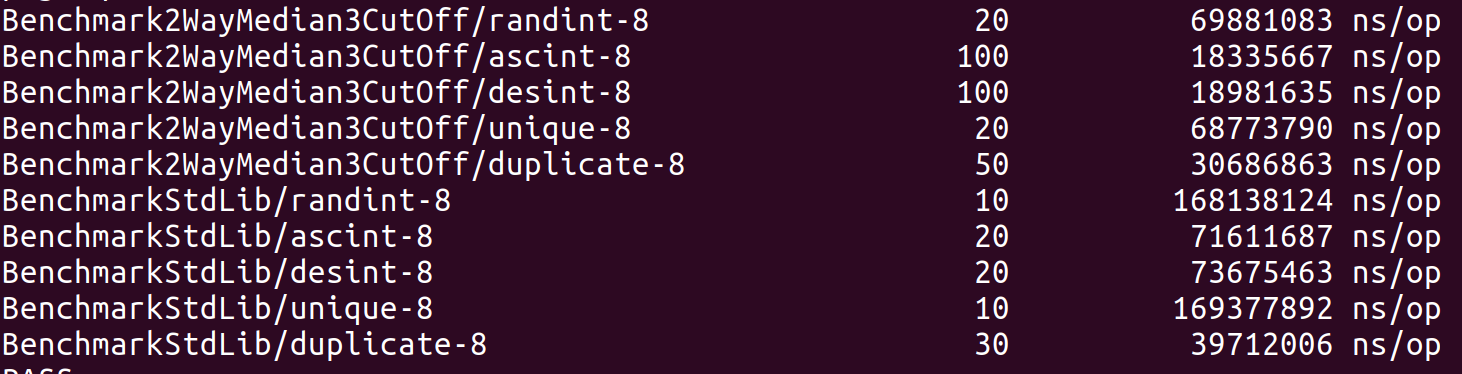
人们观察到复杂的方法在应对小规模数据时往往都不如简单方法,然后就有了小的子文件切断的改进。这是大小是10时,插入排序与快速排序的对比: 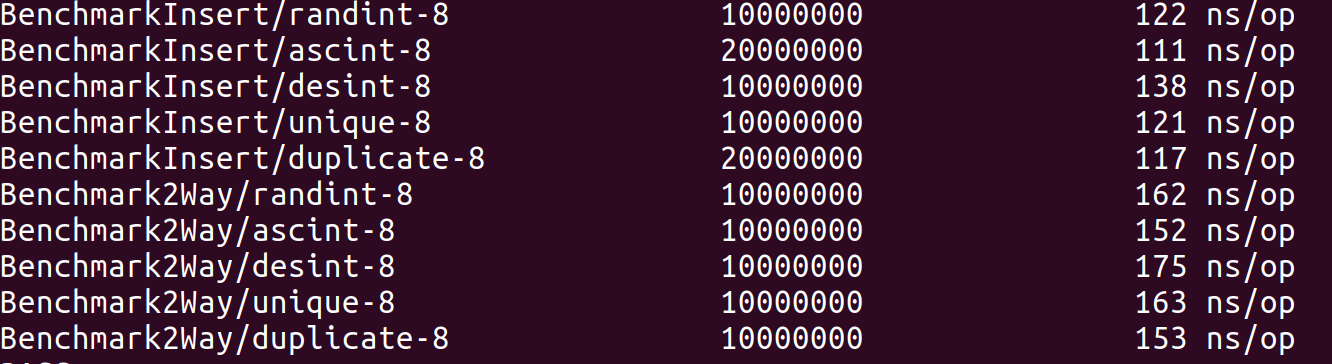
func qsort2WayMedian3CutOff(nums []int) {
size := len(nums)
if size <= cutoff {
insertSort(nums)
return
}
i := partition2WayMedian3(nums, 0, size-1)
qsort2WayMedian3CutOff(nums[0:i])
qsort2WayMedian3CutOff(nums[i+1:])
}
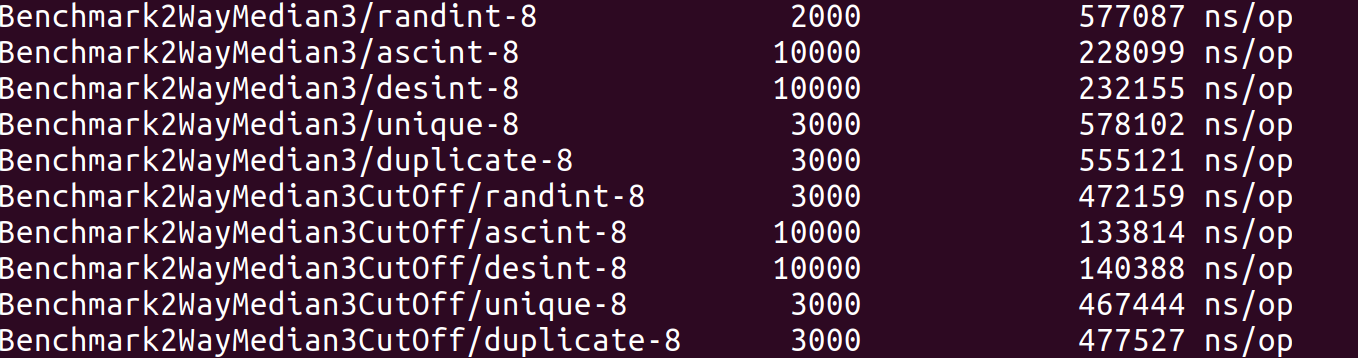
切断后效果:
还有三路划分过程,首先是Dijkstra 版本:
func partition3Way1(nums []int) (int, int) {
lt := 0
i := 1
gt := len(nums) - 1
pivot := nums[0]
const (
LESS = iota
EQUAL
GREAT
)
cmp := func(a, b int) int {
if a == b {
return EQUAL
} else if a < b {
return LESS
} else {
return GREAT
}
}
for i <= gt {
switch cmp(nums[i], pivot) {
case LESS:
nums[lt], nums[i] = nums[i], nums[lt]
i++
lt++
case GREAT:
nums[gt], nums[i] = nums[i], nums[gt]
gt--
case EQUAL:
i++
}
}
return lt - 1, gt + 1
}
func qsort3Way1(nums []int) {
if len(nums) <= 1 {
return
}
lt, gt := partition3Way1(nums)
qsort3Way1(nums[0 : lt+1])
qsort3Way1(nums[gt:])
}
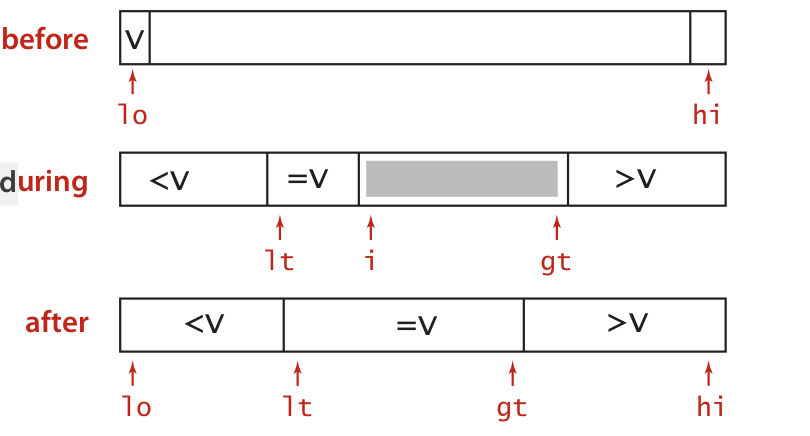
这个版本比较容易理解:有三个指针, lt 用来收集小于pivot 的元素,i 从左往右扫描,检查当前元素跟pivot 的关系, gt 用来收集大于pivot 的元素; 开始时lt定位在index 0, pivot的位置, i 定位在index 1, gt定位在最后一个元素; i 开始检查元素,发现小于pivot 的元素,就往lt 处扔, lt 紧跟上来, i 继续往前; 发现等于pivot 的元素,继续往前; 发现大于pivot 的元素往gt处扔,i 接着检查gt扔过来的元素, gt 往i的位置前进; i 越过gt 后, 所有元素检查完。效果就是:
三路划分对大量重复元素的数组效果比较好:

Jon Bentley和Douglas McIlroy 又折腾出一个快速三路划分方法:把所有跟枢纽元素相等的元素都扔到数组左右两端, 挨着左边相等区间的是所有小于枢纽的元素,挨着右边相等区间的是所有大于枢纽的元素,划分结束后,再把两个相等区间的元素,往中间扔。达到下图的效果:
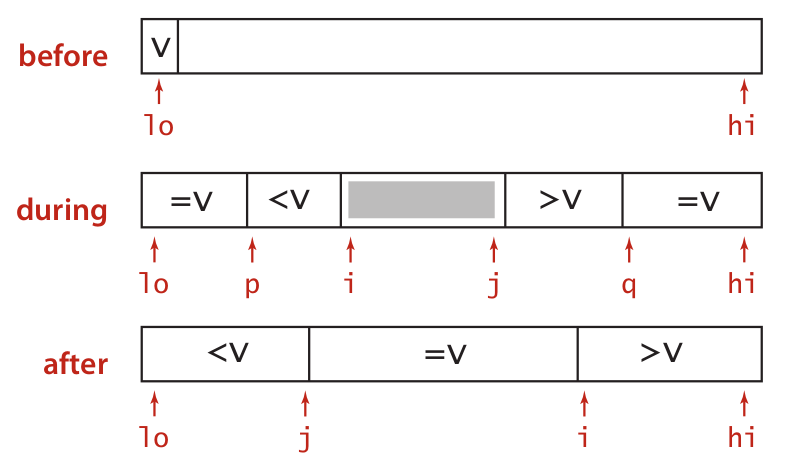
func partition3Way2(nums []int) (int, int) {
pivot := nums[0]
len := len(nums)
i := 0
j := len
p := 0
q := len
for {
i++
j--
for nums[i] < pivot && i < len-1 {
i++
}
for pivot < nums[j] {
j--
}
if i >= j {
break
}
nums[i], nums[j] = nums[j], nums[i]
if nums[i] == pivot {
p++
nums[i], nums[p] = nums[p], nums[i]
}
if nums[j] == pivot {
q--
nums[q], nums[j] = nums[j], nums[q]
}
}
nums[0], nums[j] = nums[j], nums[0]
mlo := j - 1
mhi := j + 1
for k := 1; k <= p; k, mlo = k+1, mlo-1 {
nums[k], nums[mlo] = nums[mlo], nums[k]
}
for k := len - 1; k >= q; k, mhi = k-1, mhi+1 {
nums[k], nums[mhi] = nums[mhi], nums[k]
}
return mlo, mhi
}
func qsort3Way2(nums []int) {
len := len(nums)
if len <= 1 {
return
}
mlo, mhi := partition3Way2(nums)
if mlo > 0 {
qsort3Way2(nums[0 : mlo+1])
}
if mhi < len-1 {
qsort3Way2(nums[mhi:])
}
}
代码主体和两路划分一样,新增指针p,q, p开始初始化为i,q初始化为j,划分循环内部,当i, j 停止后,分别检查i,j 是否因为遇到跟pivot 相等的元素而停止,如果左边遇到,p往i靠近,p, i 互换元素,如果右边遇到,q往j靠近,q,j互换元素, 使用p,q 收集左右两边遇到等于pivot的元素,划分结束后,数组的状态: nums[0]=(some value), nums[1:p+1]=(=pivot), nums[p+1:j]=(<pivot), nums[j]=(pivot), nums[j+1:q]=(>pivot), nums[q:r]=(=pivot) 最后把nums[1..p] 往pivot 位置 j 的左边搬运, nums[q..len-1]往pivot j的右边搬运。三路划分版本2 比版本1 处理随机的情况更好:
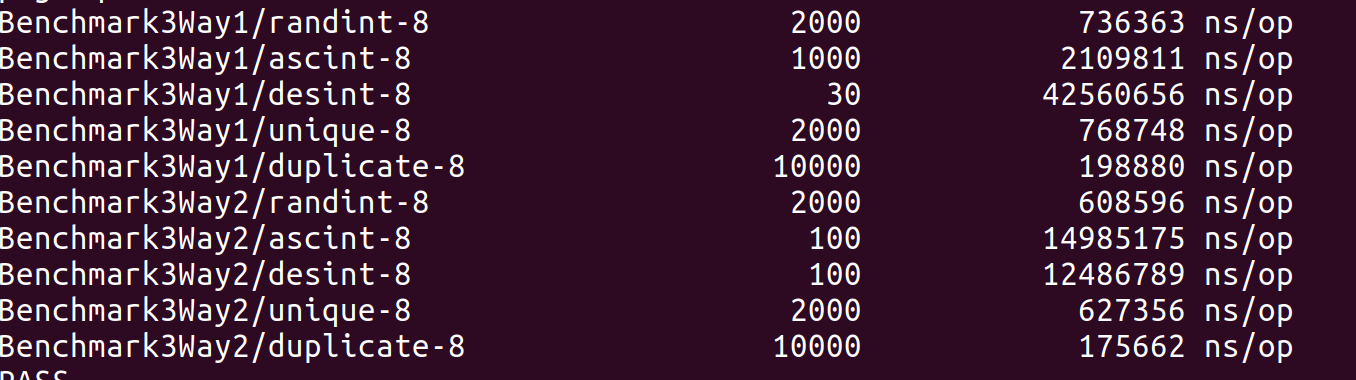
自己手写的版本可能会胜过标准库的性能,猜测可能是因为golang 没有一个编译时泛型的机制,interface 提供了某种程度的运行时"泛型", sort.Sort interface 的Less方法和Swap方法属于排序过程中的高频操作, 它们不能被内联。试验代码
SIZE=1e6 go test -bench '2WayMedian3CutOff$|StdLib'
输出:
还有一些更好的改进,比如pdqsort, rust 标准库已经用上了。
Douglas McIlroy 还介绍了一种攻击quicksort 通用排序库历程的方法,通用的库接口,为了做到足够灵活, 就允许客户端定制比较函数,Douglas 的方法就是在这里做手脚,他说这种方法几乎适用于任何基于quicksort 的通用排序接口,可能是这个原因, 基于quicksort 的通用排序库,最后采用heapsort 作为回退方案。 quicksort killer
package main
import (
"flag"
"fmt"
"math/rand"
"sort"
"strings"
"time"
)
var n = flag.Int("count", 13, "specify size of nums generate")
type killer struct {
data []int // data be sorted
visit []int // record data array visit info, initialized to special gas value and changed by Less
ncmp int // number of comparisons (calls to Less)
nsolid int // number of elements that have been set to non-gas values
candidate int // guess at current pivot
gas int // special value for unset elements, higher than everything else
}
func (k *killer) Len() int { return len(k.data) }
func (k *killer) Swap(i, j int) {
k.data[i], k.data[j] = k.data[j], k.data[i]
}
func (k *killer) Less(i, j int) bool {
x := k.data[i]
y := k.data[j]
k.ncmp++
if k.visit[x] == k.gas && k.visit[y] == k.gas {
if x == k.candidate {
// freeze x
k.visit[x] = k.nsolid
k.nsolid++
} else {
// freeze y
k.visit[y] = k.nsolid
k.nsolid++
}
}
if k.visit[x] == k.gas {
k.candidate = x
} else if k.visit[y] == k.gas {
k.candidate = y
}
return k.visit[x] < k.visit[y]
}
func GenKillerSeq(size int) []int {
killer := newKiller(*n)
sort.Sort(killer)
return killer.visit
}
func (k *killer) Verify() bool {
for i := 1; i < len(k.data); i++ {
if k.visit[k.data[i]] != k.visit[k.data[i-1]]+1 {
return false
}
}
return true
}
func (k *killer) String() string {
var b strings.Builder
len := len(k.visit)
b.WriteString(fmt.Sprintf("n=%d, ncmp=%d\n", len, k.ncmp))
for i := 0; i < len; i++ {
b.WriteString(fmt.Sprintf("%d\n", k.visit[i]))
}
return b.String()
}
func newKiller(size int) *killer {
k := &killer{}
k.data = make([]int, size)
k.visit = make([]int, size)
k.gas = size - 1
for i := 0; i < size; i++ {
k.data[i] = i
k.visit[i] = k.gas
}
return k
}
func makeRandInts(len, max int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0, len)
for i := 0; i < len; i++ {
nums = append(nums, rand.Intn(max))
}
return nums
}
func main() {
flag.Parse()
ns := makeRandInts(*n, *n)
s := time.Now()
sort.Slice(ns, func(i, j int) bool { return ns[i] < ns[j] })
e := time.Now()
fmt.Printf("rand time: %v\n", e.Sub(s))
killer := newKiller(*n)
s = time.Now()
sort.Sort(killer)
e = time.Now()
fmt.Printf("killer time: %v\n", e.Sub(s))
}
为了观察到killer 的效果,需要把标准库的heapsort 回退关掉:
func quickSort(data Interface, a, b, maxDepth int) {
/*
if maxDepth == 0 {
heapSort(data, a, b)
return
}
*/
}
运行killer:
./killer -count 10000

./killer -count 1000000
时间退化的厉害:















 3427
3427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









