







hdfs federation 联邦集群 概念
1.1 当前HDFS包含两层结构:
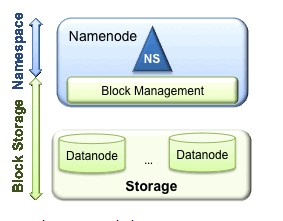
(1) Namespace 管理目录,文件和数据块。它支持常见的文件系统操作,如创建文件,修改文件,删除文件等。
(2) Block Storage有两部分组成:
Block Management维护集群中datanode的基本关系,它支持数据块相关的操作,如:创建数据块,删除数据块等,同时,它也会管理副本的复制和存放。
Physical Storage存储实际的数据块并提供针对数据块的读写服务。
【Block Storage的这两部分分别在namenode和datanode上实现,所以该模块由namenode和datanode分工完成】
1.2 Federation架构
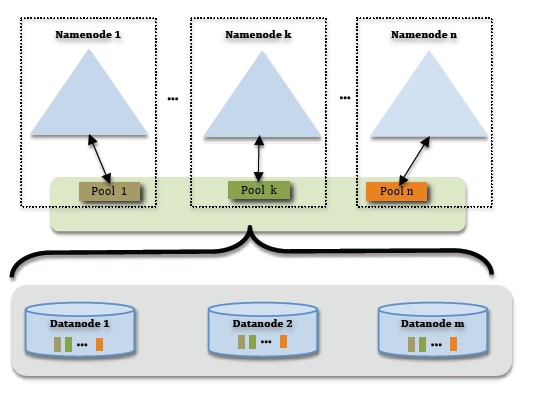
为了水平扩展namenode,federation使用了多个独立的namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
一个block pool由属于同一个namespace的数据块组成,每个datanode可能会存储集群中所有block pool的数据块。
每个block pool内部自治,也就是说各自管理各自的block,不会与其他block pool交流。一个namenode挂掉了,不会影响其他namenode。
某个namenode上的namespace和它对应的block pool一起被称为namespace volume。它是管理的基本单位。当一个namenode/nodespace被删除后,其所有datanode上对应的block pool也会被删除。当集群升级时,每个namespace volume作为一个基本单元进行升级。
1.3 Federation关键技术点
【命名空间管理】
Federation中存在多个命名空间,如何划分和管理这些命名空间非常关键。在Federation中并采用“文件名hash”的方法,因为该方法的locality非常差,比如:查看某个目录下面的文件,如果采用文件名hash的方法存放文件,则这些文件可能被放到不同namespace中,HDFS需要访问所有namespace,代价过大。为了方便管理多个命名空间,HDFS Federation采用了经典的Client Side Mount Table。
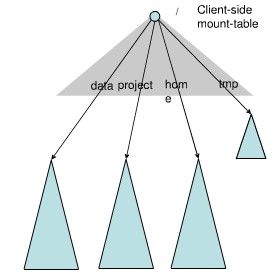
如上图所示,下面四个深色三角形代表一个独立的命名空间,上方浅色的三角形代表从客户角度去访问的子命名空间。各个深色的命名空间Mount到浅色的表中,客户可以访问不同的挂载点来访问不同的命名空间,这就如同在Linux系统中访问不同挂载点一样。这就是HDFS Federation中命名空间管理的基本原理:将各个命名空间挂载到全局mount-table中,就可以做将数据到全局共享;同样的命名空间挂载到个人的mount-table中,这就成为应用程序可见的命名空间视图。
1.4 主要优点
【扩展性和隔离性】
支持多个namenode水平扩展整个文件系统的namespace。可按照应用程序的用户和种类分离namespace volume,进而增强了隔离性。
【通用存储服务】
Block Pool抽象层为HDFS的架构开启了创新之门。分离block storage layer使得:
<1> 新的文件系统(non-HDFS)可以在block storage上构建
<2> 新的应用程序(如HBase)可以直接使用block storage层
<3> 分离的block storage层为将来完全分布式namespace打下基础
【设计简单】
Federation整个核心设计实现大概用了4个月。大部分改变是在Datanode、Config和Tools中,而Namenode本身的改动非常少,这样 Namenode原先的鲁棒性不会受到影响。虽然这种实现的扩展性比起真正的分布式的Namenode要小些,但是可以迅速满足需求,另外Federation具有良好的向后兼容性,已有的单Namenode的部署配置不需要任何改变就可以继续工作
1.5 HDFS Federation不足
【单点故障问题】
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。
【负载均衡问题】
HDFS Federation采用了Client Side Mount Table分摊文件和负载,该方法更多的需要人工介入已达到理想的负载均衡。
Federation Configuration
2.1 配置
Step 1: Add the dfs.nameservices parameter to your configuration and configure it with a list of comma separated NameServiceIDs. This will be used by the Datanodes to determine the Namenodes in the cluster.
Step 2: For each Namenode and Secondary Namenode/BackupNode/Checkpointer add the following configuration parameters suffixed with the correspondingNameServiceID into the common configuration file:
| Daemon | Configuration Parameter |
|---|---|
| Namenode | dfs.namenode.rpc-address dfs.namenode.servicerpc-address dfs.namenode.http-address dfs.namenode.https-address dfs.namenode.keytab.file dfs.namenode.name.dir dfs.namenode.edits.dir dfs.namenode.checkpoint.dir dfs.namenode.checkpoint.edits.dir |
| Secondary Namenode | dfs.namenode.secondary.http-address dfs.secondary.namenode.keytab.file |
| BackupNode | dfs.namenode.backup.address dfs.secondary.namenode.keytab.file |
2.2 配置示例
Here is an example configuration with two Namenodes:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>nn-host1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>nn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns1</name>
<value>snn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>nn-host2:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>nn-host2:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns2</name>
<value>snn-host2:http-port</value>
</property>
.... Other common configuration ...
</configuration>
HDFS Federation客户端(viewfs)配置攻略
HDFS客户端配置方法,并通过对客户端配置的讲解让大家深入理解HDFS Federation引入的“client-side mount table”(viewfs)这一概念,这是通过新的文件系统viewfs实现的。
3.1 Hadoop 1.0中的配置
在Hadoop1.0中,只存在一个NameNode,所以,客户端设置NameNode的方式很简单,只需在core-site.xml中进行以下配置:
<property>
<name>fs.default.name</name>
<value>hdfs://host0001:9000</value>
</property>bin/hadoop fs –ls /home设置该参数后,当用户使用以下命令访问hdfs时,目录或者文件路径前面会自动补上“hdfs://host0001:9000”:
其中“/home/”将被自动替换为“hdfs://host0001:9000/home/”
当然,你也可以不在core-site.xml文件中配置fs.default.name参数,这样当你读写一个文件或目录时,需要使用全URI地址,即在前面添加“hdfs://host0001:9000”
3.2 Hadoop 2.0中的配置
在Hadoop 2.0中,由于引入了HDFS Federation,当你启用该功能时,会同时存在多个可用的namenode,为了便于配置“fs.default.name”,你可以规划这些namenode的使用方式,比如图片组使用namenode1,爬虫组使用namenode2等等,这样,爬虫组员工使用的HDFS client端的core-site.xml文件可进行如下配置:
<property>
<name>fs.default.name</name>
<value>hdfs://namenode1:9000</value>
</property>图片组员工使用的HDFS client端的core-site.xml文件可进行如下配置:
<property>
<name>fs.default.name</name>
<value>hdfs://namenode2:9000</value>
</property>从HDFS和HBase使用者角度看,当仅仅使用单NameNode上管理的数据时,是没有问题的。但是,当考虑HDFS之上的计算类应用,比如YARN/MapReduce应用程序,则可能出现问题。因为这类应用可能涉及到跨NameNode数据读写,这样必须显式的指定全URI,即输入输出目录中必须显式的提供类似“hdfs://namenode2:9000”的前缀,以注明目录管理者NameNode的访问地址。
3.3 hdfs federation配置
为了解决这种麻烦,为用户提供统一的全局HDFS访问入口,HDFS Federation借鉴Linux提供了client-side mount table,这是通过一层新的文件系统viewfs实现的,它实际上提供了一种映射关系,将一个全局(逻辑)目录映射到某个具体的namenode(物理)目录上,采用这种方式后,core-site.xml配置如下:
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="mountTable.xml"/>
<property>
<name>fs.default.name</name>
<value>viewfs://ClusterName/</value>
</property>
</configuration>经过以上配置后,你可以像1.0那样,访问HDFS上的文件,比如:其中,“ClusterName”是HDFS整个集群的名称,你可以自己定义一个。mountTable.xml配置了全局(逻辑)目录与具体namenode(物理)目录的映射关系,你可以类比linux挂载点来理解。
假设你的集群中有三个namenode,分别是namenode1,namenode2和namenode3,其中,namenode1管理/usr和/tmp两个目录,namenode2管理/projects/foo目录,namenode3管理/projects/bar目录,则可以创建一个名为“cmt”的client-side mount table,并在mountTable.xml中进行如下配置:
<configuration>
<property>
<name>fs.viewfs.mounttable.cmt.link./user</name>
<value> hdfs://namenode1:9000/user </value>
</property>
<property>
<name>fs.viewfs.mounttable.cmt.link./tmp</name>
<value> hdfs:/ namenode1:9000/tmp </value>
</property>
<property>
<name>fs.viewfs.mounttable.cmt.link./projects/foo</name>
<value> hdfs://namenode2:9000/projects/foo </value>
</property>
<property>
<name>fs.viewfs.mounttable.cmt.link./projects/bar</name>
<value> hdfs://namenode3:9000/projects/bar</value>
</property>
</configuration>中的“/usr/”将被映射成“hdfs://namenode1:9000/user/”。
Client-side mount table的引入为用户使用HDFS带来极大的方便,尤其是跨namenode的数据访问。
参考
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/Federation.html
https://issues.apache.org/jira/secure/attachment/12483795/Viewfs%20Guide.pdf
http://dongxicheng.org/mapreduce/hdfs-federation-introduction/
http://dongxicheng.org/hadoop-hdfs/hdfs-federation-viewfs/















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









