






数据的读取与保存
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.数据读取与保存概述
Spark的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:
Text文件
Json文件
Csv文件
Sequence文件
Object文件
...
文件系统分为:
本地文件系统
HDFS
HBASE
MySQl
...
二.文件类数据读取与保存
1>.Text文件


packagecom.yinzhengjie.bigdata.spark.readerimportorg.apache.spark.rdd.RDDimportorg.apache.spark.{SparkConf, SparkContext}
object TextDemo {
def main(args: Array[String]): Unit={//初始化配置信息及SparkContext
val sparkConf: SparkConf = new SparkConf().setAppName("TextFile").setMaster("local[*]")
val sc= newSparkContext(sparkConf)//读取hdfs上的数据
val passwd:RDD[String] = sc.textFile("hdfs://hadoop101.yinzhengjie.org.cn:9000/yinzhengjie/etc/passwd")//遍历已经读取到的数据
passwd.foreach(println)//释放资源
sc.stop()
}
}
textFile(String)读取文件案例
package com.yinzhengjie.bigdata.spark.transformations.action
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDDobjectSaveAsTextFileOperate {
def main(args: Array[String]): Unit={//创建SparkConf对象
val config:SparkConf = newSparkConf()
config.setMaster("local[*]")
config.setAppName("WordCount")//创建Spark上下文对象
val sc = newSparkContext(config)
val listRDD:RDD[(String,Int)]= sc.parallelize(List(("A",130),("B",121),("A",140),("B",113),("A",127)),2)/**
* 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本*/listRDD.saveAsTextFile("E:\\yinzhengjie\\bigdata\\spark\\text")
}
}
saveAsTextFile(path)保存文件案例
2>.Json文件
{"name":"yinzhengjie","passwd":"2020"}
{"name":"Jason","passwd":"666666"}
{"name":"Liming","passwd":"123"}
{"name":"Jenny","passwd":"456"}
{"name":"Danny","passwd":"789"}
user.json文件内容
packagecom.yinzhengjie.bigdata.spark.readerimportorg.apache.spark.rdd.RDDimportorg.apache.spark.{SparkConf, SparkContext}importscala.util.parsing.json.JSON
object JsonDemo {
def main(args: Array[String]): Unit={//初始化配置信息及SparkContext
val sparkConf: SparkConf = new SparkConf().setAppName("JsonFile").setMaster("local[*]")
val sc= newSparkContext(sparkConf)/*** 如果JSON文件中每一行就是一个JSON记录,那么可以通过将JSON文件当做文本文件来读取,然后利用相关的JSON库对每一条数据进行JSON解析。*/val user:RDD[String]= sc.textFile("E:\\yinzhengjie\\bigdata\\input\\json\\user.json")//解析json数据
val result:RDD[Option[Any]] =user.map(JSON.parseFull)//遍历已经读取到的数据
result.foreach(println)//释放资源
sc.stop()
}
}
读取json文件案例
3>.Sequence文件
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。Spark 有专门用来读取 SequenceFile 的接口。
在SparkContext中,可以调用 sequenceFile[ keyClass, valueClass](path)。
温馨提示:
SequenceFile文件只针对PairRDD
packagecom.yinzhengjie.bigdata.spark.transformations.actionimportorg.apache.spark.{SparkConf, SparkContext}importorg.apache.spark.rdd.RDD
object SaveAsSequenceFileOperate {
def main(args: Array[String]): Unit={//创建SparkConf对象
val config:SparkConf = newSparkConf()
config.setMaster("local[*]")
config.setAppName("WordCount")//创建Spark上下文对象
val sc = newSparkContext(config)
val listRDD:RDD[(String,Int)]= sc.parallelize(List(("A",130),("B",121),("A",140),("B",113),("A",127)),2)/*** 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。*/listRDD.saveAsSequenceFile("E:\\yinzhengjie\\bigdata\\spark\\sequence")
}
}
saveAsSequenceFile(path)案例
4>.对象文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。
可以通过objectFile[k,v](path) 函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile() 实现对对象文件的输出。因为是序列化所以要指定类型。
packagecom.yinzhengjie.bigdata.spark.transformations.actionimportorg.apache.spark.{SparkConf, SparkContext}importorg.apache.spark.rdd.RDD
object SaveAsObjectFileOperate {
def main(args: Array[String]): Unit={//创建SparkConf对象
val config: SparkConf = newSparkConf()
config.setMaster("local[*]")
config.setAppName("WordCount")//创建Spark上下文对象
val sc = newSparkContext(config)
val listRDD: RDD[(String, Int)]= sc.parallelize(List(("A", 130), ("B", 121), ("A", 140), ("B", 113), ("A", 127)), 2)/*** 用于将RDD中的元素序列化成对象,存储到文件中。*/listRDD.saveAsObjectFile("E:\\yinzhengjie\\bigdata\\spark\\object")
}
}
saveAsObjectFile(path)案例
三.文件系统类数据读取与保存
1>.HDFS
Spark的整个生态系统与Hadoop是完全兼容的,所以对于Hadoop所支持的文件类型或者数据库类型,Spark也同样支持。
另外,由于Hadoop的API有新旧两个版本,所以Spark为了能够兼容Hadoop所有的版本,也提供了两套创建操作接口.对于外部存储创建操作而言,hadoopRDD和newHadoopRDD是最为抽象的两个函数接口,主要包含以下四个参数.输入格式(InputFormat):
制定数据输入的类型,如TextInputFormat等,新旧两个版本所引用的版本分别是org.apache.hadoop.mapred.InputFormat和org.apache.hadoop.mapreduce.InputFormat(NewInputFormat)键类型:
指定[K,V]键值对中K的类型值类型:
指定[K,V]键值对中V的类型分区值:
指定由外部存储生成的RDD的partition数量的最小值,如果没有指定,系统会使用默认值defaultMinSplits
温馨提示:
其他创建操作的API接口都是为了方便最终的Spark程序开发者而设置的,是这两个接口的高效实现版本.例如,对于textFile而言,只有path这个指定文件路径的参数,其他参数在系统内部指定了默认值。在Hadoop中以压缩形式存储的数据,不需要指定解压方式就能够进行读取,因为Hadoop本身有一个解压器会根据压缩文件的后缀推断解压算法进行解压. 如果用Spark从Hadoop中读取某种类型的数据不知道怎么读取的时候,上网查找一个使用map-reduce的时候是怎么读取这种这种数据的,然后再将对应的读取方式改写成上面的hadoopRDD和newAPIHadoopRDD两个类就行了.
2>.MySQL
安装MariaDB数据库:[root@hadoop101.yinzhengjie.org.cn ~]# yum -y install mariadb-server
将数据库设置为开机自启动:[root@hadoop101.yinzhengjie.org.cn ~]# systemctl enable mariadb
Created symlinkfrom /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service.[root@hadoop101.yinzhengjie.org.cn ~]#[root@hadoop101.yinzhengjie.org.cn ~]# systemctl start mariadb[root@hadoop101.yinzhengjie.org.cn ~]#
登录数据库,创建spark数据库并授权用户登录:
MariaDB[(none)]> CREATE SCHEMA IF NOT EXISTS spark DEFAULT CHARACTER SET =utf8mb4;
Query OK,1 row affected (0.00sec)
MariaDB[(none)]>MariaDB[(none)]> CREATE USER jason@'172.200.%' IDENTIFIED BY 'yinzhengjie';
Query OK,0 rows affected (0.00sec)
MariaDB[(none)]>MariaDB[(none)]> GRANT ALL ON spark.* TO jason@'172.200.%';
Query OK,0 rows affected (0.00sec)
MariaDB[(none)]>
登录数据库,创建spark数据库并授权用户登录(详细步骤戳这里)
mysql
mysql-connector-java
5.1.27
往pom.xml添加依赖关系
packagecom.yinzhengjie.bigdata.spark.readerimportjava.sql.DriverManagerimportorg.apache.spark.rdd.JdbcRDDimportorg.apache.spark.{SparkConf, SparkContext}
object MySQLDemo {
def main(args: Array[String]): Unit={//1.创建spark配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("JdbcRDD")//2.创建SparkContext
val sc = newSparkContext(sparkConf)//3.定义连接mysql的参数
val driver = "com.mysql.jdbc.Driver"val url= "jdbc:mysql://hadoop101.yinzhengjie.org.cn:3306/spark"val username= "jason"val passwd= "yinzhengjie"val sql= "select name,passwd from user where id >= ? and id <= ?;"val lowerBound= 1val upperBound= 3val numPartitions= 2
//创建JdbcRDD,访问咱们的数据库(当然你得自定义数据库的表信息哟)
val jdbcRDD = newJdbcRDD(//指定SparkContext
sc,//创建MySQL数据库连接对象(指定一个无参函数,其返回值是一个连接对象)
() =>{
Class.forName(driver)//指定数据库的连接驱动
DriverManager.getConnection(url, username, passwd) //获取连接
},//定义要执行的SQL语句
sql,//指定查询的下限
lowerBound,//指定查询的上限
upperBound,//指定分区数
numPartitions,//对查询的结果进行操作
(resultSet) =>{
println(resultSet.getString(1) + ", " + resultSet.getString(2)) //我就查询了2个字段,每个字段都是varchar类型,因此均用"getString"方法取对应列的数据
}
)
jdbcRDD.collect()//打印最后查询结果的条数
println(jdbcRDD.count())//释放资源
sc.stop()
}
}
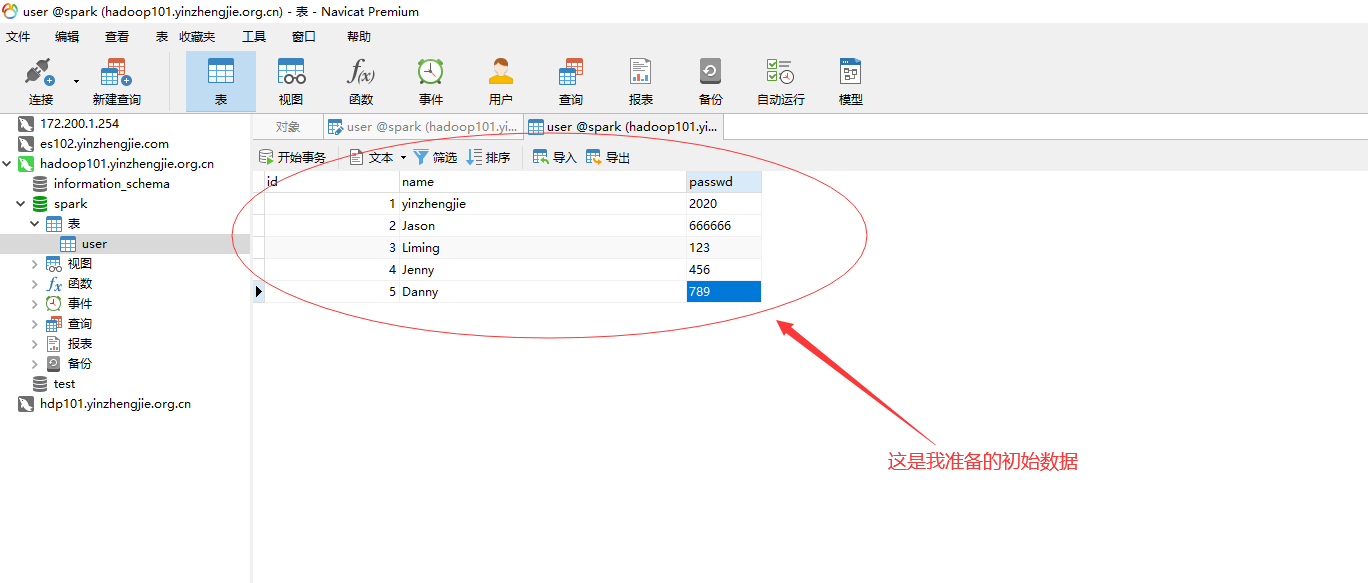
从MySQL中读取的数据
packagecom.yinzhengjie.bigdata.spark.writerimportjava.sql.{Connection, DriverManager, PreparedStatement}importorg.apache.spark.{SparkConf, SparkContext}importorg.apache.spark.rdd.{JdbcRDD, RDD}
object MySQLDemo {
def main(args: Array[String]): Unit={//1.创建spark配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("JdbcRDD")//2.创建SparkContext
val sc = newSparkContext(sparkConf)//3.定义连接mysql的参数
val driver = "com.mysql.jdbc.Driver"val url= "jdbc:mysql://hadoop101.yinzhengjie.org.cn:3306/spark"val username= "jason"val password= "yinzhengjie"
//4.准备要写入的数据
val dataRDD:RDD[(String,String)] = sc.makeRDD(List(("zhangsan","2020"),("lisi","2020"),("wangwu","2020"),("zhaoliu","2020")))/*** 5.保存数据
*
* 温馨提示:
* foreach是行动算子,上面的dataRDD数据可能会发送到不同的Executor中,因此写入数据库的顺序可能和我们定义List的顺序不同哟~*/dataRDD.foreachPartition(datas=>{
Class.forName(driver)//指定数据库的连接驱动
val conn:Connection = DriverManager.getConnection(url, username, password) //获取连接
datas.foreach{case (name,passwd) =>{
val sql= "insert into user (name,passwd) values (?,?);"//定义SQL
val statment:PreparedStatement = conn.prepareStatement(sql)//解析SQL语句
statment.setString(1,name)
statment.setString(2,passwd)
statment.executeUpdate()
statment.close()
}
}
conn.close()//释放连接
})//释放资源
sc.stop()
}
}
往MySQL中写入数据














 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









