







在Linux中,正则表达式可以分为"基本正则表达式"和"扩展正则表达式"
正则表达式元字符
| 元字符 | 功能 |
|---|---|
^ | 以什么开头 |
$ | 以什么结尾 |
. | 匹配一个字符 |
* | 匹配0个或多个 |
[] | 匹配集合中的 |
[x-y] | 匹配集合范围内的 |
[^ ] | 匹配不在集合中的 |
\ | 转义 |
- 特殊的元字符
| 元字符 | 功能 | 实例 | 怎么匹配 |
|---|---|---|---|
\< | 以什么开头 | '\<love' | 匹配以love开头的所有行 |
\> | 以什么结尾 | 'love\>' | 匹配love结尾的所有行 |
\(..\) | 标签匹配以后使用的字符 | '\(love\)able \1er' | 用位置\1\2引导前面做好的标签,最大支持9个 |
x\{m\} or x\{m,\} or x\{m,n\} | 重复字符x,m次,至少m次,至少m且不超过n次 | o\{5,10\} | o字符重复5到10次的行 |
- 扩展的正则表达式
| 元字符 | 说明 |
|---|---|
+ | 重复前一个字符一个或一个以上 |
? | 0个或者一个字符 |
| ` | ` |
() | 分组过滤匹配 |
正则表达式(一)---位置锚定
1、^
^表示锚定行首,可能大家不太明白这个锚定行首是什么意思,没关系,看一个例子就能马上知道怎么回事了。现在我们需要在regular.txt文件中找出行首是guo的行。

可以看出,尽管原始文件的第2、4、8行都含有guo,但是它们都不是出现在行首,因此不会匹配,匹配上行的都是行首为guo的行。这就是前面所说的锚定行首的意思。是不是一下就理解了
- 匹配以love开头的所有行
$ grep '^love' re-file
love, how much I adore you. Do you know- 匹配love结尾的所有行
$ grep 'love$' re-file
clover. Did you see them? I can only hope love.- 匹配以
l开头,中间包含两个字符,结尾是e的所有行
$ grep 'l..e' re-file
I had a lovely time on our little picnic.
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
is forever. I live for you. It's hard to get back in the- 匹配
A-Z的字母,其次是ove
$ grep '[A-Z]ove' re-file
Lovers were all around us. It is springtime. Oh- 匹配不在
A-Z范围内的任何字符行,所有的小写字符
$ grep '[^A-Z]' re-file
I had a lovely time on our little picnic.
Lovers were all around us. It is springtime. Oh
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
is forever. I live for you. It's hard to get back in the
groove.- 匹配空格
$ grep '^$' re-file- 匹配任意字符
$ grep '.*' re-file
I had a lovely time on our little picnic.
Lovers were all around us. It is springtime. Oh
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
is forever. I live for you. It's hard to get back in the
groove.
2、$
$表示锚定行尾, 前面已经知道了锚定行首 ,那么锚定行尾不用说也应该知道怎么回事了吧,对,$表示的出现在此字符前面的内容都必须出现在行尾才会匹配,比如说需要在regular.txt文件中找出行尾是guo的行。

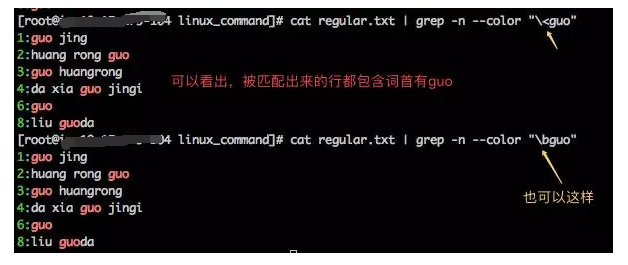
3、\< 或者 \b
\< 或者 \b 用来锚定词首,其后面出现的内容必须作为单词首部出现才会匹配,现在让我们在regular.txt文件中找出词首是guo的行。 我们可以这么做。
- 匹配
love.
$ grep 'love\.' re-file
clover. Did you see them? I can only hope love.- 前面
o字符重复2到4次
$ grep 'o\{2,4\}' re-file
groove.- 重复
o字符至少2次
$ grep 'o\{2,\}' re-file
groove.- 重复
0字符最多2次
$ grep 'o\{,2\}' re-file
I had a lovely time on our little picnic.
Lovers were all around us. It is springtime. Oh
love, how much I adore you. Do you know
the extent of my love? Oh, by the way, I think
I lost my gloves somewhere out in that field of
clover. Did you see them? I can only hope love.
is forever. I live for you. It's hard to get back in the
groove.- 重复前一个字符一个或一个以
$ egrep "go+d" linux.txt
Linux is a good
god assdxw bcvnbvbjk
gooodfs awrerdxxhkl
good- 0个或者一个字符
ansheng@Ubuntu:/tmp$ egrep "go?d" linux.txt
god assdxw bcvnbvbjk
gdsystem awxxxx- 或,查找多个字符串
$ egrep "gd|good" linux.txt
Linux is a good
gdsystem awxxxx
good- 分组过滤匹配
$ egrep "g(la|oo)d" linux.txt
Linux is a good
glad
good
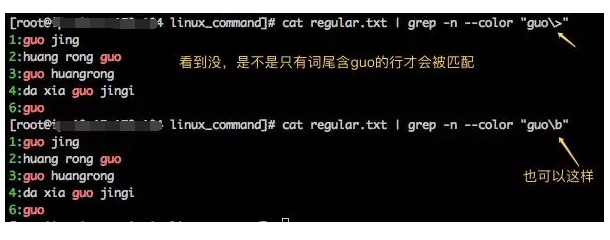
4、\>或者 \b
\> 或者 \b (对,你没看错,\b既能锚定词首 ,也能锚定词尾 )用来锚定词尾,其前面出现的内容必须作为单词尾部出现才会匹配,好了,现在让我们在regular.txt文件中找出词尾部是guo的行。 我们可以这么做。
5、\B
\B 是用来匹配非单词边界的,和\b作用相反,什么意思了,还是用例子来说明一切吧。找出regular文件中 guo不出现在词尾的行,其实这中间包含两个条件:其一是匹配的行要包含guo;其二是guo不能出现在行尾。

正则表达式(二)---匹配次数的正则
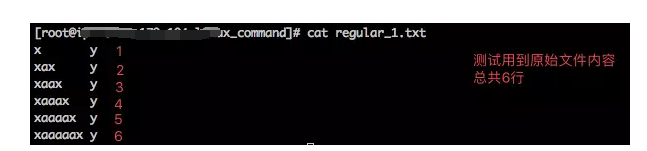
一个regular_1.txt文件,让你找出含有连续2个a的行,应该怎么查找?这还不简单嘛,cat regular_1.txt | grep "aa" ;很好,现在换成另一个问题:找出含有连续100个a的行 。难道在命令中连续写上100个a ?显然太累人了。
原始文件的内容
1、\{m\}
\{m\} 表示匹配前面字符m次,也就是说前面字符出现m次的行会被匹配,好了,实验一把吧,查找regular_1.txt 文件中a连续出现2次的行。

只要是连续出现了2次a以上的行都会被匹配上,这个世界究竟怎么了?我明明只是想要连续出现两次a的行就可以了,干嘛给我返回这么多。其实很简单。连续3个a就已经包含了连续2个a,肯定能匹配上。再看看第5行,连续4个a包含了2次连续2个a,相当于第5行匹配上了2次。
现在我们可以很轻松的写出下面这样的命令来找出文件中含有连续100个a的行 :
cat regular_1.txt | grep "a\{100\}"
2、\{m,\}
\{m,\} 至少匹配前面字符m次,好了, 我们再来查找regular_1.txt 文件中a连续 出现2次以上的行。

仔细看看第4、6行,还是有些许不同的,以第3行为例,\{2\}形式匹配的时候第3行被匹配上是因为连续包含了2个a被匹配上,因此输出中最后的a没有颜色;而\{2,\}形式第3行被匹配上是因为连续包含了3个a才被匹配上。果相同但因却不一样。
3、\{m,n\}
\{m,n\} 匹配前面字符 最少m次,最多m次都可以,好了, 我们再来查找regular_1.txt 文件中a连续 出现2次到3次的行。

至于第6行含有连续5个a为什么能被匹配上,通过前面的分析我想大家应该知道原因吧。
4、*
*表示其前面的字符连续出现任意次,这个任意当然包括0次了,也包括多次,好了,现在我们用*来匹配测试下。
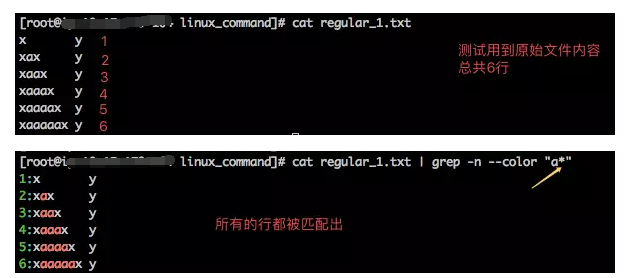
可以看出,原始文件中无论有多少个a都被匹配出,尽管第1行不含a字符,但还是匹配出来了。
5、\?
\?表示其前面的字符连续出现0次或者1次,下面我们用它来匹配regular_1.txt文件中出现0次或者1次的行。
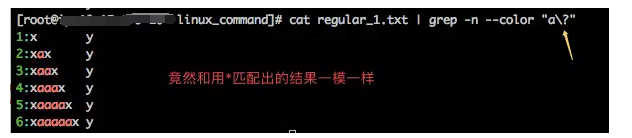
看到上面的结果吗,竟然和*匹配的结果是一样的,尽管结果一样,但是匹配的原理是不同的。以第3行为例,如果使用*匹配,则第3行是以因为其连续含有2个a被匹配上的;而如果是以\?匹配,则第3行被匹配上是因为先匹配了上1个a,再匹配上后面的a,相当于匹配上了2次。所以有时候看事务是不能只看表面的。
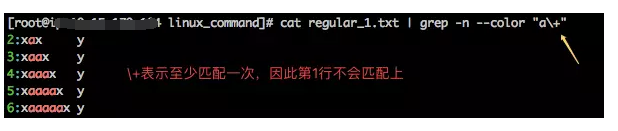
6、\+
\+ 表示其前面的字符连续出现1次或者多次,也就是说,\+前面的字符至少要连续出现一次才能匹配上。如果我们需要查找文件中出现过a字符的行,我们可以使用下面的命令。
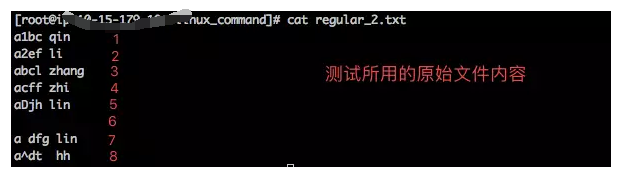
正则表达式(三)---常用符号
实验用的文件
1、[[: :]]系列
这是一组形式相似的正则,主要由以下正则组成

看上面的表格,每个正则所表达的意义已经很清楚了,至于具体怎么用,还是举几个例子来说明。
下图中的命令是查找regular_2.txt文件中a后面是任意数字的行,从输出看,确实只有a后面是数字的行才会被匹配。

再举个例子,这次是查找regular_2.txt文件中a后面是标点符号的行,看到没,用[[:punct:]]就能达到目的了。是不是很简单,还有其它几个正则,大家有兴趣可以自己在环境上试试,这里就不一一举例了

2、[ ]
[]表示匹配指定范围内的任意单个单词。这样说可能还是不太容易理解,还是用实例说明一切吧,现在来找出文件regular_2.txt 中a后面紧跟b或者紧跟c或者紧跟^的行。

[]中还支持用-连接表示匹配一个范围内的一个字符,比如说[A-Z]就等价于[[:upper:]],[0-9]等价于[[:lower:]]等等。
3、^
看过前面文章的同学可能会觉得诧异,^ 在位置锚定那篇文章中不是已经讲过它的作用是用来锚定行首吗?怎么这里又出现了。这是因为^和[ ]结合能表达两种含义。
^放在[]外表示匹配行首出现[]中字符的行,也就是我们前面说的锚定行首;而^放在[]内表示“排除、非”的意思,即表示匹配指定范围外的任意单个单词。
如果这样描述还是有点抽象,还是用例子来说明一切吧,^表示行首锚定的用法前面文章已经说过了这里就不再举例了,这里我们来实验下^放在[ ]中的用法,现在来查找regular_2.txt文件中a后面不含字母(包括大小写字母)的行。

4、.
在正则表达式中,.表示匹配任意单个字符(换行符除外),范例如下:找出文件regular_2.txt 中字符a与字符d之间含有任意一个字符的行。可以看出,只要
a和d之间有一个字符,不管是什么字符都匹配上了。

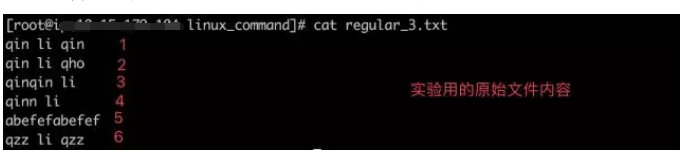
正则表达式(四)---分组、后向引用与转义
实验所用的文件
1、\( \)
在讲分组之前,还是先一起回顾下匹配指定次数的正则,如"\{2\} "表示匹配到其前面的字符连续出现2次的行,比如说,我们可以用"qin\{2\}"将regular_3.txt文件的第4行qinn li匹配到。
但是,如果我们想要匹配连续出现2次qin的行了?单纯的使用"\{2\} " 就无能为力了,这时候就需要用到分组了,在正则表达式中,\( \)表示分组,所谓的分组就是把\( \) 中出现的内容当做一个整体。
好了,现在可以找出regular_3.txt 文件连续出现2次qin的行了 ,没错,\(qin\)\{2\}就是将qin当做一个整体,再和后面的\{2\} 结合起来表示匹配qin两次,就是这么简单。

分组还可以嵌套,这又是什么意思了。看下面的例子。这个表达式看起来很复杂,我们拆开分析相对来说会容易理解些:黄色部分的两侧是\( \),因此需要将其作为一个整体和后面的\{2\} 结合起来就是黄色部分出现2次的行被匹配。
好了,那么黄色部分是又是什么了,可以看出,黄色部分内部的正则为ab\(ef\)\{2\},这个正则应该不难看出它表示的是abefef吧。
因此,可以分析出整个表达式\(ab\(ef\)\{2\}\)\{2\}就是匹配abefef 出现2次的行。

2、\n
我们现在可以介绍后向引用了,后向引用是建立在分组的前提上的,这也是为什么我们先讲分组的原因。
在一个含有分组的正则表达式中,默认情况下,每个分组会自动拥有一个组号(从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推)后向引用用于重复搜索前面某个分组匹配的文本。例如,\1 代表此处需要再次匹配分组1 的内容。
现在有个小任务,是需要将原始文件的第1行和第6行匹配出。也就说匹配出li前后单词相同的两行。

不少人会写出下面的式子,但是从输出看来,结果并不符合要求,因为第二行li 的前后单词不一样,但是也匹配上了。

这时候,后向引用就能派上用途了。看到没,表达式\(...\) li \1含有一个分组\(...\),这个分组表示匹配任意3个字符,那么表达式后面的\1就表示\(...\) 匹配到什么,这里需要再匹配一次。
因此,如果通过\(...\) 匹配上了qin,那么在li后面也需要再匹配到qin才能匹配上该行,因此第2行不会匹配上,第1行能匹配上;如果通过\(...\) 匹配上了qzz,那么在li后面也需要再匹配到qzz才能匹配上 该行,因此第6行能匹配上 。

3、\
\在正则表达式中表示转义,还记得我们前面介绍过的字符 .吗,在正则表达式中,这些字符有特殊含义,比如说 . 表示匹配任意字符。那如果想要正则表达式就匹配文件中的.本身了,这时候就需要转义字符\了。如下所示,注意正则表达式中有无转义字符\所匹配结果的区别。
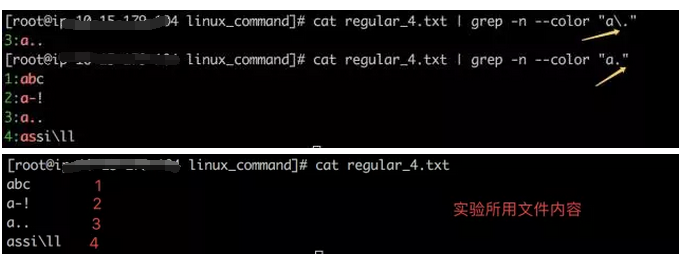
再举个例子,如果要匹配regular_4.txt 文件中含有\的行,应该怎么办了,很简单,只要在前面再加一个\就好了,如下。

正则表达式(五)---扩展正则表达式
实验所用的文件
1、{ }、()、+、?、
其实,扩展正则表达式基本正则表达式90%的用法是一摸一样的,只是有那么几个符号有区别,这几个符号就是{ }、()、+、?,分别对应基本正则表达式中的\{ \}、\(\)、\+、\? ,是不是觉得扩展正则表达式方便多了。
要使得grep将正则表达式中的符号当做扩展表达式去理解,需要用到-E选项,如下示例表达式就是利用扩展正则表达式 {}匹配文件中qi后面出现2次字符n的行,其对应基本表达式:
cat regular_3.txt | grep -n --color "qin\{2\}"

2、|
在扩展正则表达式中,还有一个很常用的符号 | ,它表示或,这是基本正则表达式所没有的,这个符号通常会和分组结合在一起用,下面的例子很清楚的告诉我们 | 的用法

那么如果 | 不和分组结合用,会有什么区别了?还是看例子
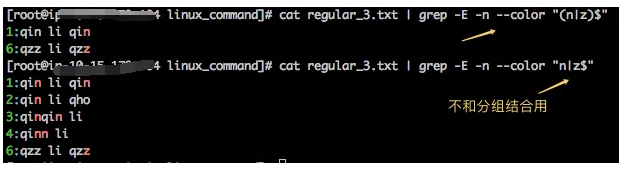
很明显,| 有没有和分组一起用,区别很大,从上面的匹配结果很容易看出,"(n|z)$" 表示匹配以n结尾或者以z结尾的行;而"n|z$"则表示匹配以z结尾或者含有n的行。也就是说,如果不用分组,后面的$不会作用在前面的字符n上。
3、总结
扩展正则表达式就总结完了,多,有了前面基本正则表达式的基础,扩展正则表达式就是这么简单。好了,现在整个正则表达式的总结已经完了,基本上大家在工作中能用到的也就差不多这些了,最后大家一起思考一个综合性的正则表达式问题吧。
给出一个测试文件,找出文件中的邮箱地址,要解决这个问题,首先得知道什么是合法的邮箱地址,在网上搜了个关于合法邮箱地址的条件,懒得打字,就截图过来了。

下面是测试文件以及相应的答案。

20个正则表达式案例
1、校验密码强度
密码的强度必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间
^(?=.\\d)(?=.[a-z])(?=.*[A-Z]).{8,10}$
2、校验中文
字符串只能是中文
^[\\u4e00-\\u9fa5]{0,}$
3、由数字,26个英文字母或下划线组成的字符串
^\\w+$
4、校验E-Mail 地址
[\\w!#$%&'+/=?^_`{|}~-]+(?:\.[\\w!#$%&'+/=?^_`{|}~-]+)@(?:[\\w](?:[\\w-][\\w])?\.)+\\w?
5、校验身份证号码
15位:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18位:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6、校验日期
“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7、校验金额
金额校验,精确到2位小数
^[0-9]+(.[0-9]{2})?$
8、校验手机号
下面是国内 13、15、18开头的手机号正则表达式
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9、判断IE的版本
^.MSIE 5-8?(?!.Trident\\/[5-9]\.0).*$
10、校验IP-v4地址
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11、校验IP-v6地址
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12、检查URL的前缀
if (!s.match(/^[a-zA-Z]+:\\/\\//)){
s = 'http://' + s;}
13、提取URL链接
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14、文件路径及扩展名校验
^([a-zA-Z]\\:|\\\)\\\([^\\\]+\\\)[^\\/:?"<>|]+\.txt(l)?$
15、提取Color Hex Codes
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16、提取网页图片
\\< [img][^\\\\>][src] = [\\"\\']{0,1}([^\\"\\'\\ >]*)
17、提取页面超链接
(<a\\s(?!.\\brel=)[^>])(href="https?:\\/\\/)((?!(?:(?:www\.)?'.implode('|(?:www\.)?', $follow_list).'))[^"]+)"((?!.\\brel=)[^>])(?:[^>])>
18、查找CSS属性
^\\s[a-zA-Z\-]+\\s[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19、抽取注释
<!--(.*?)-->
20、匹配HTML标签
<\\/?\\w+((\\s+\\w+(\\s=\\s(?:".?"|'.?'|[\\^'">\\s]+))?)+\\s|\\s)\\/?>
转载来源 :码农有道
https://mp.weixin.qq.com/s/HGSGtMfepNImuwIwVxlwSw
https://mp.weixin.qq.com/s/ghJGV37LVuDydFMQzOy66w
https://mp.weixin.qq.com/s/DOJJtVTwjcQQAz9Km-YE4Q
https://mp.weixin.qq.com/s/Om7YwN84IgohO-orFPUE6g
https://mp.weixin.qq.com/s/1dXYdlPlx9eC8BKg9FYr4Q
https://blog.ansheng.me/article/examples-of-linux-regular-expressions
https://www.qdfuns.com/article/26351/5cc47c5a56c75e45b148a75f0cca536e.html















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









