







上一节讲解了shell脚本运行的本质
这下让我们真正来一探类
org.apache.hadoop.dfs.NameNodePS:这年头不会源码不好混啊,生活所迫!
准备工作:
需要把相应的.xml文件放在正确的目录下
还有源码也要放在跟对应的class文件同一层次下,这样才可以找到源码!
===========================
与c语言对应的gdb对应,java有jdb
启动方法如下:
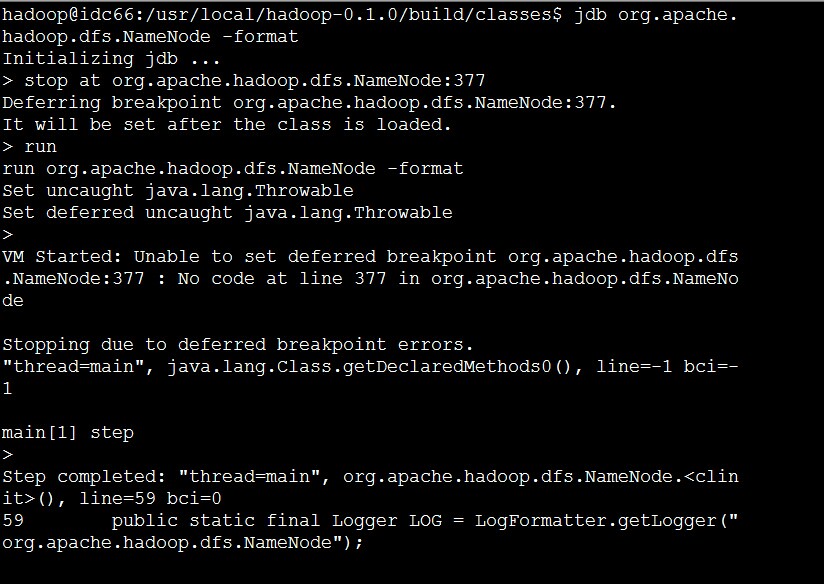
这样就可以开始调试了!
具体的命令请网上搜索!
======================
下面根据我的jdb命令流程来解析./bin/hadoop name -format的执行流程。
首先执行
59 public static final Logger LOG = LogFormatter.getLogger("org.apache.hadoop.dfs.NameNode");
这个不用去关注,毕竟不是核心知识点,获取一个Logger类罢了!下面执行
Step completed: "thread=main", org.apache.hadoop.dfs.NameNode.main(), line=378 bci=7
378 Configuration conf = new Configuration();这个比较简单,核心在于
>
Step completed: "thread=main", org.apache.hadoop.conf.Configuration.<init>(), line=63 bci=36
63 defaultResources.add("hadoop-default.xml");
main[1] next
>
Step completed: "thread=main", org.apache.hadoop.conf.Configuration.<init>(), line=64 bci=46
64 finalResources.add("hadoop-site.xml");所以,务必保证上面这2个文件存在且配置好了,注意,这2个文件可以放在classes目录下即可!
注意,这两个文件加载有先后顺序,先加载hadoop-default.xml
再加载hadoop-site.xml,这样hadoop-site.xml的配置项会覆盖hadoop-default.xml里的配置项
也就是说,hadoop-site.xml里的配置项具有优先级!
---------
Step completed: "thread=main", org.apache.hadoop.dfs.NameNode.main(), line=380 bci=8
380 if (argv.length == 1 && argv[0].equals("-format")) {
这个简单了,就是验证参数,因为 NameNode可以带参数执行也可以不带参数执行。
往下执行
Step completed: "thread=main", org.apache.hadoop.dfs.NameNode.main(), line=381 bci=25
381 File dir = getDir(conf);可以看到这里就是获取文件目录,应该是根据配置文件来获取。
往下跟就知道了!
Step completed: "thread=main", org.apache.hadoop.dfs.NameNode.getDir(), line=95 bci=0
95 return new File(conf.get("dfs.name.dir", "/tmp/hadoop/dfs/name"));
显然这里就是根据你的配置文件的dfs.name.dir来获取对应的目录文件
main[1] print dir
dir = "/tmp/hadoop/dfs/name"
说明配置文件里确实没有设置!
---------------------------------------------------------------------------------------------------
下面就是执行格式化操作:
Step completed: "thread=main", org.apache.hadoop.dfs.NameNode.main(), line=395 bci=30
395 format(conf);这个里面才是核心代码!!!
71 FSDirectory.format(getDir(conf), conf);
调用了静态类的静态方法,跟进去看看!
===
这个静态方法的全部内容就是如下:
/** Create a new dfs name directory. Caution: this destroys all files
* in this filesystem. */
public static void format(File dir, Configuration conf)
throws IOException {
File image = new File(dir, "image");
File edits = new File(dir, "edits");
if (!((!image.exists() || FileUtil.fullyDelete(image, conf)) &&
(!edits.exists() || edits.delete()) &&
image.mkdirs())) {
throw new IOException("Unable to format: "+dir);
}
}
------------------------------
可见先获取2个文件,一个是image,一个是edits.
首先看第一句
!image.exists() || FileUtil.fullyDelete(image, conf)
根据短路原则,表明如果不存在image文件则算了,否则通过FileUtil.fullyDelete全部删除!
这个具体细节就不说了,调用本地文件系统删除,没啥可说的!
最后一行就是说
(!edits.exists() || edits.delete())
&&
image.mkdirs()
如果edits存在就删除,并且最后还要再重新创建文件夹image
-----------
所以两次执行ls的结果如图:
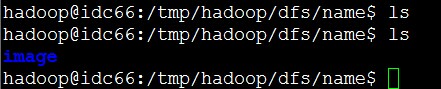
验证了代码!
备注:读者对于文件系统内部的删除等操作不用太关注,这些东西其实都没啥技术含量
都是很简单的封装,JAVA的封装真的没啥意思,还是C的简单粗暴来的痛快!
最后:
>
Step completed: "thread=main", org.apache.hadoop.dfs.NameNode.main(), line=396 bci=34
396 System.err.println("Formatted "+dir);
main[1] next
> Formatted /tmp/hadoop/dfs/name
Step completed: "thread=main", org.apache.hadoop.dfs.NameNode.main(), line=397 bci=59
397 System.exit(0);
main[1] next
>
The application exited
hadoop@idc66:/usr/local/hadoop-0.1.0/build/classes$
这样也就执行完了,我们就很轻松了验证了
./bin/hadoop namenode -format的原理,是不是很痛快?
饕餮大餐后续更精彩!















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









