







判断一句话中有多少个词——types和token两种不同的计数标准
例句1:I do uh main ‐ mainly business data processing
uh和main ‐ mainly我们不好认为他是否是一个词,于是main被称为一个fragment,main被称为一个filled pause
例句2:Seuss’s cat in the hat is different from other cats!
定义一个term叫做lemma,
Lemma: same stem, part of speech, rough word sense
譬如cat和cats就称为same lemma
再定义一个term叫wordform,即一个词的不同形式,显然这里cat和cats是不同的wordform,然后教授说到:
we are going to use different definition depending on our goals
接下来看一个真正的例句:
they lay back on the San Francisco grass and looked at the stars and their
如果按token的方式来计数的话,就是按部就班一个字一个字地数,所以就是15个,但是如果把San Francisco算成一个词,那就是一共14个
如果按type的方式来数的话,they和their就只算一个,两个the也只算一个,San Francisco的情况和前面一样
所以就是一共13(12)个,如下图:

值得注意的是:
这里的type指的是lemma type,而不是wordform type,接着视频中给出了一个练习题便是wordform type了,这也印证了教授前面说过的话:
we are going to use different definition depending on our goals

答案是10types 11tokens,解释是‘I’出现了两次,所以types只有10个。
典型的corpus
我们将N定义为tokens的个数,将V定义为vocabulary的个数或types的个数。
| tokens=N | types=|V| | |
Switchboard phone conversations | 2.4 million | 20 thousand |
| Shakespeare | 884000 | 31 thousand |
| google N-grams | 1 trillion | 13 million |
这个统计数据其实很有意思,第二行其实就是说,莎士比亚一生写了88万4千字的作品,其中用了3万1千个不同的词。
第一行也就是平时日常对话用到的词汇,只有2万个。
Google的那个之所以上千万,是因为包含了url、email地址这样的词,但是即使除去这些词,英语的总词汇依然上百万。
然后Church and Gale 猜测了这样一个大致的关系:
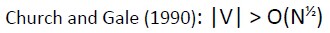
然后教授用一个标准的 unix 文本处理工具进行了演示,接下来的几分钟都是些各种指令下的基本文本统计分析,譬如用的最多的词的词频,a开头的词等等。
譬如这条命令,tr -sc ’A-Za-z’ ’\n’ < shakes.txt | sort | head,大意就是将除 ’A-Za-z’以外的其他字符都替换成换行符,然后排序,取一个head看看。
最大匹配分词法——更适合中文而不适合英文的分词方法
教授提到中文里字和字之间没有间隔符号,中文分词的一个简单方法就是最大匹配分词法,然后进行了示例。
例子1:thecatinthehat
从第一个字母t开始看起,在字典中寻找能够匹配上的最长的一个词,显然这里会匹配到the,因为没有theca这样的词,于是the就被分出来了,然后以此类推。
例子2:thetabledownthere
这个例子里面问题就出来了,因为theta在英语里也是一个单词,最后分词的结果是theta、bled、own、there
例子3:你妈逼你结婚了吗?
分词的结果很可能是:你妈逼、你、结婚、了、吗、?
显然这样是不合适的
值得注意的是,最大匹配分词法用在中文分词里比用在英文分词里效果好得多,因为中文的词语相对长度恒定。

















 4360
4360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









