







上一篇笔记分析到了Binder驱动在调用mmap创建内存映射的过程。但是在分配物理内存的时候,我们只分配了一个页面。当我们需要更多物理内存的时候,Binder驱动才回去继续分配物理内存。
另外,物理内存的分配是以页为单位的,但是在进程中使用内存是却并不是以页为单位,所以binder驱动程序使用结构体binder_buffer来描述进程对内存的使用,表示一块内存。
分配内核缓冲区
当一个进程使用BC_TRANSACTION 或者BC_REPLY向binder驱动发送命令请求和另一个进程通信时需要向另一个进程传递数据(通过结构体binder_transaction_data结构体),binder驱动程序就会将这些数据从用户空间拷贝到内核空间(描述不准确的,应该是从client进程的用户空间拷贝到service进程的内核空间,因为同一个binder_proc的内核空间和用户空间映射的是同一片物理内存,理论上并不需要拷贝的),然后再传递给目标进程。这时候,binder驱动需要在目标进程的内核虚拟地址空间中分配一块地址来存放这些数据。
所以这里涉及到一个关键步骤:分配内核虚拟地址空间,这是通过binder_alloc_buf实现的
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size,
size_t offsets_size, int is_async)
{
.......
}参数就很有讲究,需要理解一下,proc表示的是目标进程。第二第三个参数就是binder_transaction_data数据结构中的data_size和offsets_size(binder结构体说明),最后一个参数表示请求的内核虚拟地址空间用于同步事物还是异步事物。
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size,
size_t offsets_size, int is_async)
{
struct rb_node *n = proc->free_buffers.rb_node;
struct binder_buffer *buffer;
size_t buffer_size;
struct rb_node *best_fit = NULL;
void *has_page_addr;
void *end_page_addr;
size_t size;
if (proc->vma == NULL) {
pr_err("%d: binder_alloc_buf, no vma\n",
proc->pid);
return NULL;
}
//按void指针大小对齐,size表示要分配的虚拟地址空间的大小
size = ALIGN(data_size, sizeof(void *)) +
ALIGN(offsets_size, sizeof(void *));
//溢出检测
if (size < data_size || size < offsets_size) {
binder_user_error("%d: got transaction with invalid size %zd-%zd\n",
proc->pid, data_size, offsets_size);
return NULL;
}
//如果使用异步请求,那么还需要检测需要使用的内核虚拟地址空间大小 是否大于 剩余可用于异步操作的地址大小
//(我们在binder_mmap的时候有看到,初始设置为总虚拟地址空间大小的一半)
if (is_async &&
proc->free_async_space < size + sizeof(struct binder_buffer)) {
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: binder_alloc_buf size %zd failed, no async space left\n",
proc->pid, size);
return NULL;
}
......
}需要注意在我们计算需要的内核虚拟地址空间总大小的时候,还需要加上一个binder_buffer结构体的大小。上文有提到,我们会使用binder_buffer来组织内存中的数据。
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size,
size_t offsets_size, int is_async)
{
.....
//使用最佳匹配算法,在空闲的内核虚拟地址空间树种(proc->buffer_free中)寻找有没有适合大小的空间可用
while (n) {
buffer = rb_entry(n, struct binder_buffer, rb_node);
BUG_ON(!buffer->free);
//相当于binder_buffer.data的长度
buffer_size = binder_buffer_size(proc, buffer);
if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right;
else {
best_fit = n;
break;
}
}
//没有找到,则直接报错退出
if (best_fit == NULL) {
pr_err("%d: binder_alloc_buf size %zd failed, no address space\n",
proc->pid, size);
return NULL;
}
//没有找到大小刚好合适的空间大小,但是找到了一块较大的地址空间,然后计算地址空间大小,并保存在buffer_size变量中
if (n == NULL) {
buffer = rb_entry(best_fit, struct binder_buffer, rb_node);
buffer_size = binder_buffer_size(proc, buffer);
}
......
}以上一段代码的主要作用是寻找空闲的内核虚拟地址空间。
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size,
size_t offsets_size, int is_async)
{
.......
//计算buffer(上面找到的空闲内核虚拟地址空间起始地址)结束地址所在的页 的起始地址
has_page_addr =
(void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK);
if (n == NULL) {
if (size + sizeof(struct binder_buffer) + 4 >= buffer_size)
buffer_size = size; /* no room for other buffers */
// 表示找到的buffer大小相比 需要的buffer大小 大了挺多,直接用浪费裁剪一下。
else
buffer_size = size + sizeof(struct binder_buffer);
}
end_page_addr =
(void *)PAGE_ALIGN((uintptr_t)buffer->data + buffer_size);
if (end_page_addr > has_page_addr)
end_page_addr = has_page_addr;
if (binder_update_page_range(proc, 1,
(void *)PAGE_ALIGN((uintptr_t)buffer->data), end_page_addr, NULL))
return NULL;
......
}上面这段代码应该说是这个函数,甚至是binder对于内核空间分配和建立物理内存映射最关键的几局代码了。而且更主要的是理解非常困难!!我花了大概一个下午才弄通其中的逻辑。
在理解之前,先给出一个结论,这在理解这段代码的时候非常关键。
我们在上文找到了一个binder_buffer类型的对象buffer,表示一个未被使用的虚拟地址空间段,用图来表示是这样的
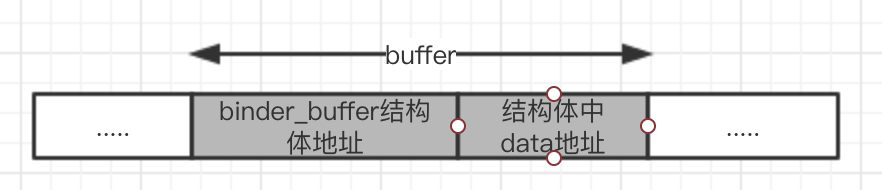
buffer由两部分组成,binder_buffer结构体,以及后面的data数据空间(建议回顾一下binder_buffer的结构)。
根据寻找buffer的代码,我们分两种情况来讨论:
情况 1
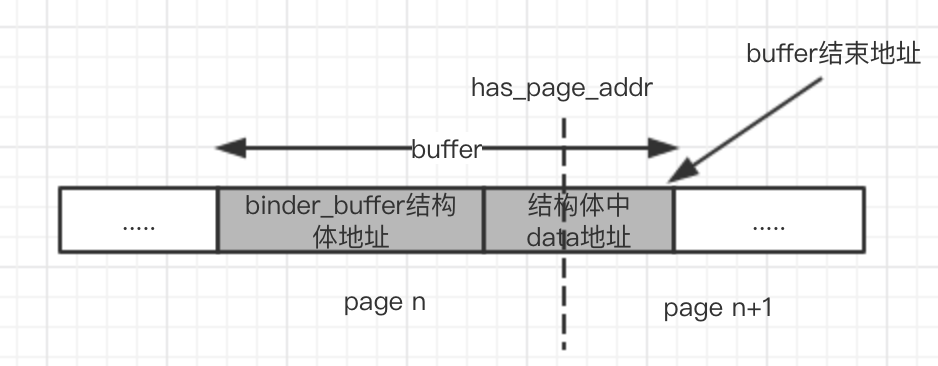
首先是has_page_addr的计算,buffer->data+buffer_size的结果是这个buffer的结束地址。如果不知道为什么……自己再去看看代码吧,buffer_size表示的并不是整个buffer的长度,而是buffer第二部分data的长度。然后获取这个地址所在的页的起始位置,就如下图(虚线表示分页的线)
size + sizeof(struct binder_bufffer)+4 > buffer_size 变换一下 :
buffer_size - size < sizeof(struct binder_bufffer) + 4
表示去掉实际需要的data区域之后,剩下的空间不够分配一个新的binder_buffer内存块的。这种情况下,让buffer_size = size;
复杂的来了,end_page_addr的计算,首先buffer_data + buffer_size,得到一个地址,我们暂且将这个地址命名为 “z地址”!
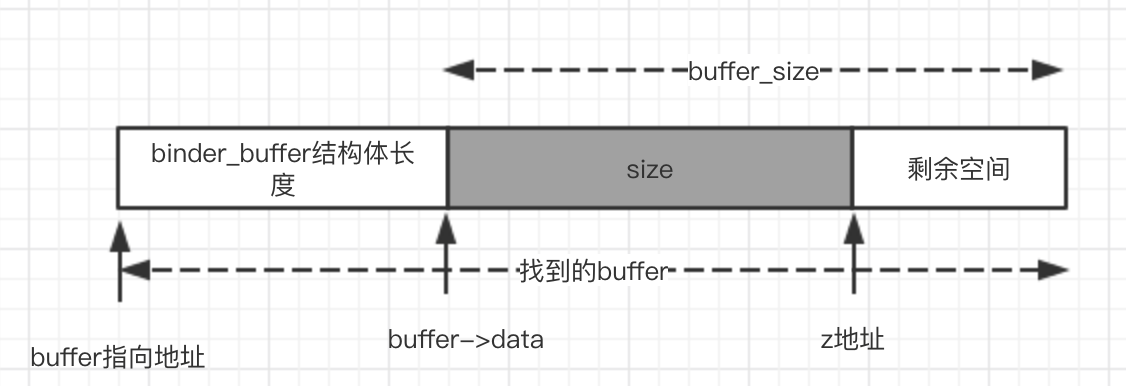
接下去就要讨论end_page_addr和 has_page_addr的关系
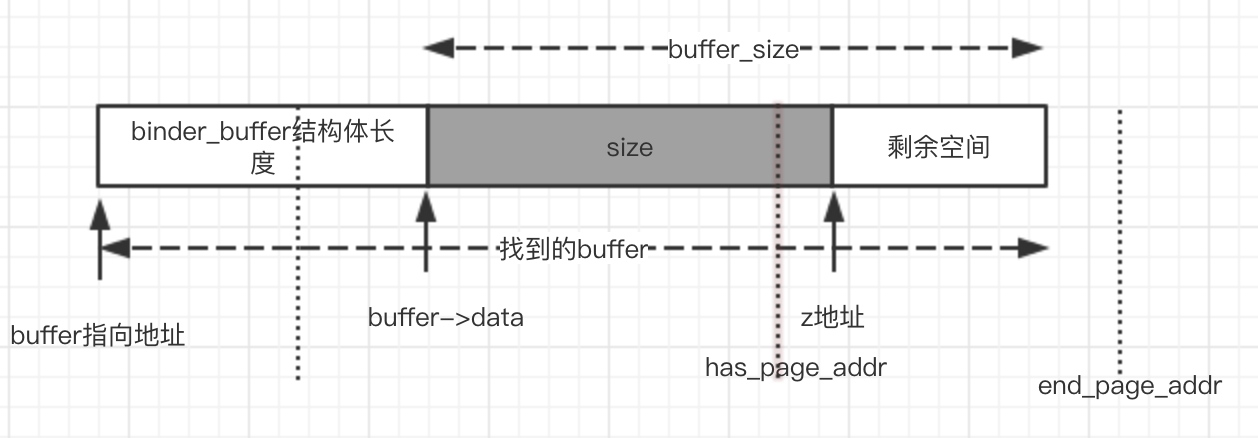
点状虚线表示页分割地址,这两种情况 z地址 和 buffer结束地址 处于同一页,那么end_page_addr >has_pager_addr,然后手动调整成 end_page_addr = has_pager_addr.
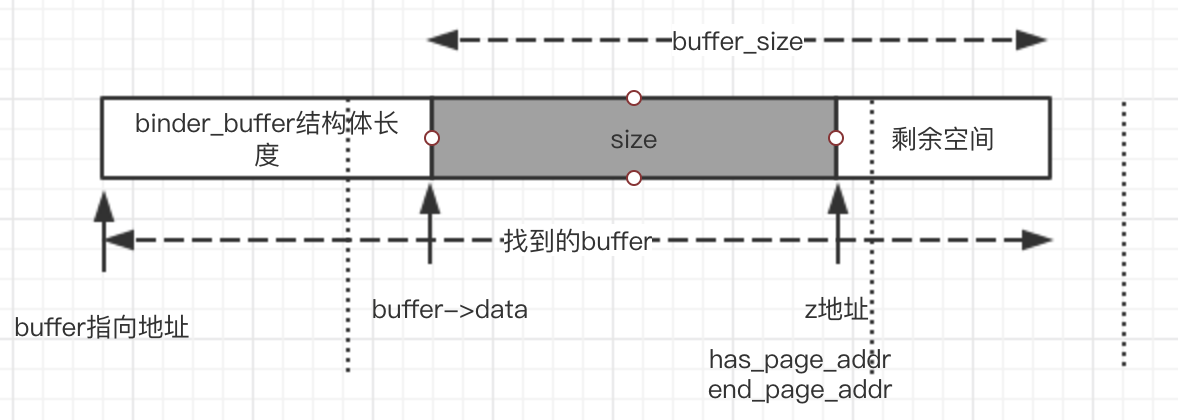
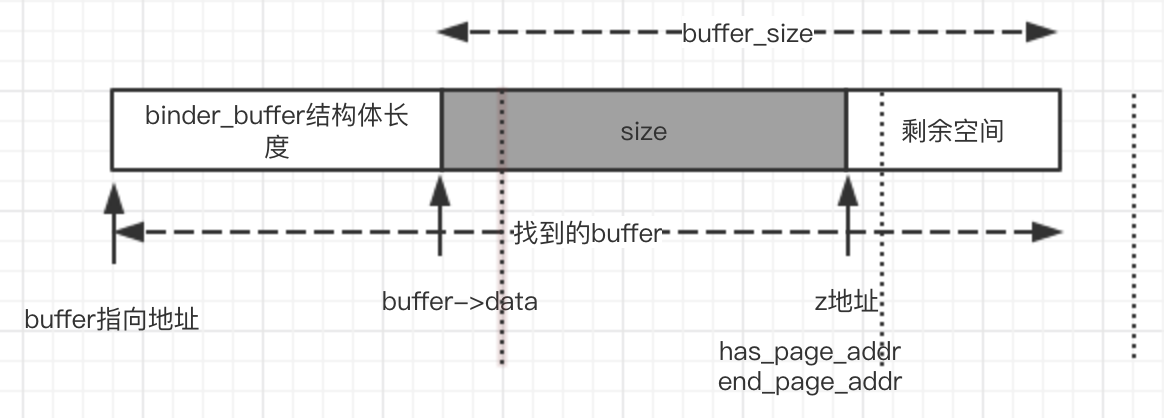
上面这种情况,直接has_page_addr = end_page_addr,之后的处理就和之前一样了。
思考:会出现end_page_addr < has_page_addr吗?不会,因为如果要出现这种情况,那么剩余空间一定需要超过1页大小,这就不符合我们对情况1的定义。
最后调用binder_update_page_range方法来进行物理内存分配(这个函数在binder_mmap建立映射关系的时候讲解过)。关键是传入的 start 和 end两个参数。其实地址是buffer->data按页对齐(将起始地址按页对齐很好理解,因为物理内存的分配是按页分配的,所以每个页面的起始地址和结束地址肯定是按页对齐的),结束地址是end_page_addr。会出现两种情况:
start < end ,这个时候binder_update_page_range 调用和以前一样,分配一页或者多页(size很大,跨了多页)的内存。
对齐后start = end,这个时候binder_update_page_range 并不会分配内存,而是直接返回了。那就很奇怪了,这种情况我们不需要分配物理内存吗?
仔细看上面几幅图,我们发现,第一图size占了三页,但是我们最后只分配了一页,中间那页,左边不需要分配吗?
思考,我们在mmap的时候分配了第一页的内存,并且创建了一个binder_buffer,如果这时候我找到的buffer就是这个binder_buffer呢?那么第一页已经被分配,所以左边不需要分配。
如果这个buffer不是处于开头,那么说明前面的buffer一定在被使用(未被使用的话,这两个buffer会合并的,在释放物理内存的地方可以找到依据),所以前面那也一定是已经被分配了,所以左边不用再次分配。
左边为什么不分配的原因找到了,再来思考右边:
如果buffer处于整个buffers的末尾,我们需要知道linux规定,内核地址空间的最后必须要留一页当做内存保护,也就是说,buffer的末尾地址不可能和z地址在同一个页中,所以不存在右侧有空间未分配的情况
如果不是处于buffer末尾,那么右侧的buffer一定是已经被使用了的,否则会合并。既然已经被使用,那么右侧的物理内存肯定已经被分配了,所以没问题。
再如图三,size仅仅在一个页面内,但是这个页面也没有分配内存,所以它的内存页一定被分配了吗?是的,如果左侧相邻的binder_buffer和他在同一页,那么这一页已经被分配,如果不是在同一页,那么说明个buffer的binder_buffer结构体跨越了两个页,这种情况下这一页的物理内存早就被分配好了(见下文)。
PS : 我们会发现多了一块剩余空间,我们既没有使用它,也没有给他分配物理内存。这表示,不一定所有binder_buffer都是相邻的,可能中间还会隔着一个大小比较小的空闲区域。
情况2
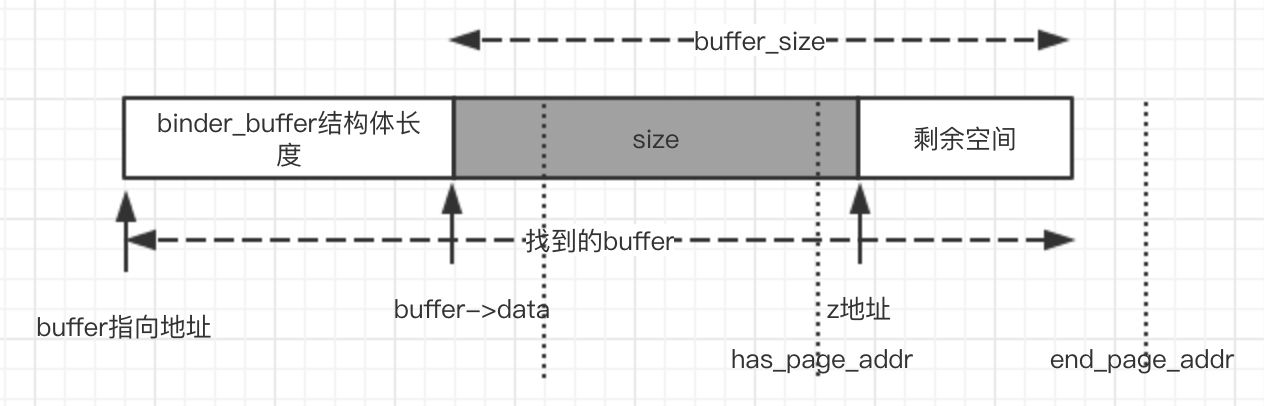
has_page_addr的计算和情况1相同。
关键剩余的空间足够分配下一个binder_buffer,所以需要进行分割。
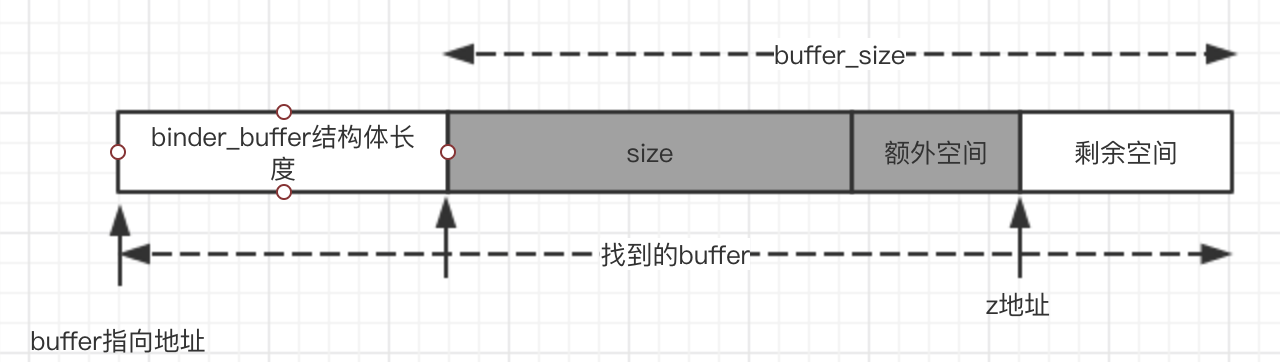
ps:上图中buffer_size还是最开始的buffer_size,不是裁剪后的buffer_size,这个变量的复用真的让代码变得很不清晰,万恶!
end_page_addr的大小和情况1不同,不仅仅包含了实际需要数据的大小size,而且还包含了一个额外空间,这个额外空间大小是binder_buffer结构体的大小。
然后和上面情况1一样分配物理内存。我们为什么要为额外空间分配内存?想想,这个额外空间是什么?他一定会成为下一个binder_buffer的binder_buffer的结构体的内存区域,我们提前为他所在页分配了物理内存。
上面这段文字可能并不是很容易理解,事实上如果不自己思考一些时间,也不可能理解,思考,结合图片才能带来有效的成果。
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size,
size_t offsets_size, int is_async)
{
....
// buffer已经被重新使用,所以从原来空闲列表中去除
rb_erase(best_fit, &proc->free_buffers);
buffer->free = 0;
//插入buffer列表中
binder_insert_allocated_buffer(proc, buffer);
//进行了切割才会出现这个情况
if (buffer_size != size) {
//将不使用的内核虚拟地址空间新建一个binder_buffer对象
struct binder_buffer *new_buffer = (void *)buffer->data + size;
//插入到buffer列表中
list_add(&new_buffer->entry, &buffer->entry);
new_buffer->free = 1;
//同时插入到free_buffer列表中
binder_insert_free_buffer(proc, new_buffer);
}
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: binder_alloc_buf size %zd got %p\n",
proc->pid, size, buffer);
//设置buffer的属性
buffer->data_size = data_size;
buffer->offsets_size = offsets_size;
buffer->async_transaction = is_async;
//如果是异步操作,还要将可用于异步操作的空间上减去这次用掉的空间
if (is_async) {
proc->free_async_space -= size + sizeof(struct binder_buffer);
binder_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC,
"%d: binder_alloc_buf size %zd async free %zd\n",
proc->pid, size, proc->free_async_space);
}
return buffer;
}最后剩下的代码就相对容易理解很多了。
释放内核缓冲区
当进程处理完Binder驱动发给他的BR_TRANSACTION或者BR_REPLY之后,就会使用BC_FREE_BUFFER来通知Binder驱动程序释放相应的内核缓冲区,以免浪费空间。
释放内存通过函数binder_free_buf实现
static void binder_free_buf(struct binder_proc *proc,
struct binder_buffer *buffer)
{
size_t size, buffer_size;
//
buffer_size = binder_buffer_size(proc, buffer);
size = ALIGN(buffer->data_size, sizeof(void *)) +
ALIGN(buffer->offsets_size, sizeof(void *));
......
//如果是异步事物,二话不说,先把异步事物空间让出来再说!
if (buffer->async_transaction) {
proc->free_async_space += size + sizeof(struct binder_buffer);
binder_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC,
"%d: binder_free_buf size %zd async free %zd\n",
proc->pid, size, proc->free_async_space);
}
//释放当前buffer数据区所占用的虚拟地址空间所对应的物理内存。
binder_update_page_range(proc, 0,
(void *)PAGE_ALIGN((uintptr_t)buffer->data),
(void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK),
NULL);
//将他从正在使用的buffer列表中删除
rb_erase(&buffer->rb_node, &proc->allocated_buffers);
buffer->free = 1;
//查找该buffer的下一个binder_buffer是否为空buffer,如果是,那么需要删除下一个buffer(和当前buffer合并)
if (!list_is_last(&buffer->entry, &proc->buffers)) {
struct binder_buffer *next = list_entry(buffer->entry.next,
struct binder_buffer, entry);
if (next->free) {
rb_erase(&next->rb_node, &proc->free_buffers);
binder_delete_free_buffer(proc, next);
}
}
//查找该buffer的上一个binder_buffer是否为空,如果是,那么删除当前buffer(合并到上一个buffer)
if (proc->buffers.next != &buffer->entry) {
struct binder_buffer *prev = list_entry(buffer->entry.prev,
struct binder_buffer, entry);
if (prev->free) {
binder_delete_free_buffer(proc, buffer);
rb_erase(&prev->rb_node, &proc->free_buffers);
buffer = prev;
}
}
//将合并后的buffer插入到空buffer列表中
binder_insert_free_buffer(proc, buffer);
}关于删除物理内存的地方,如果想要详细追究,还是可以使用和分配相同的方式去理解。
static void *buffer_start_page(struct binder_buffer *buffer)
{
return (void *)((uintptr_t)buffer & PAGE_MASK);
}
static void *buffer_end_page(struct binder_buffer *buffer)
{
return (void *)(((uintptr_t)(buffer + 1) - 1) & PAGE_MASK);
}这里有两个方法,分别用来计算buffer起始位置所在的页的地址和buffer结束位置所在的页的地址。
这个函数就是上面用来删除空闲buffer的,在调用这个函数之前我们已经保证了它不是proc得第一个buffer,而且它前面的binder_buffer一定是空的。
static void binder_delete_free_buffer(struct binder_proc *proc,
struct binder_buffer *buffer)
{
struct binder_buffer *prev, *next = NULL;
int free_page_end = 1;
int free_page_start = 1;
BUG_ON(proc->buffers.next == &buffer->entry);
prev = list_entry(buffer->entry.prev, struct binder_buffer, entry);
BUG_ON(!prev->free);
//如果前一个buffer的结束地址和当前buffer的开始地址在同一个页面上(两个buffer不一定相邻的)
if (buffer_end_page(prev) == buffer_start_page(buffer)) {
free_page_start = 0;
//如果前一个buffer的结束地址和当前页面的结束地址在同一个页面上
if (buffer_end_page(prev) == buffer_end_page(buffer))
free_page_end = 0;
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: merge free, buffer %p share page with %p\n",
proc->pid, buffer, prev);
}
//如果当前buffer不是最后一个buffer
if (!list_is_last(&buffer->entry, &proc->buffers)) {
next = list_entry(buffer->entry.next,
struct binder_buffer, entry);
//如果下一个buffer的起始地址和当前buffer的结束地址在同一个页面上
if (buffer_start_page(next) == buffer_end_page(buffer)) {
free_page_end = 0;
//如果下一个buffer起始地址和当前buffer的起始地址在同一个buffer上
if (buffer_start_page(next) ==
buffer_start_page(buffer))
free_page_start = 0;
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: merge free, buffer %p share page with %p\n",
proc->pid, buffer, prev);
}
}
//将当前buffer从buffer列表中删除
list_del(&buffer->entry);
if (free_page_start || free_page_end) {
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: merge free, buffer %p do not share page%s%s with %p or %p\n",
proc->pid, buffer, free_page_start ? "" : " end",
free_page_end ? "" : " start", prev, next);
binder_update_page_range(proc, 0, free_page_start ?
buffer_start_page(buffer) : buffer_end_page(buffer),
(free_page_end ? buffer_end_page(buffer) :
buffer_start_page(buffer)) + PAGE_SIZE, NULL);
}
}这一段在罗老师的书中还是介绍的比较详细的,说到底这里进行那么多if的判断都是防止内存的错误释放,只有当前一整页的内存都不再被使用,才回去释放物理内存,否则不会释放物理内存。
情况虽然很多,但是通过画图和代码还是比较容易理解的,这里就不分析了。
查询内存缓冲区
作为一个用户进程,在通知Binder驱动程序表示我要释放内存的时候,带上了一个地址参数,但是这个地址参数肯定是用户空间的虚拟地址空间的地址,不可能是内核空间的地址,所以,驱动程序还需要通过用户空间地址来寻找内核空间对应的地址,通过函数binder_buffer_lookup
// user_ptr就是用户进程传给binder驱动程序的参数
// 表示用户空间binder_buffer的data所指向的地址。
static struct binder_buffer *binder_buffer_lookup(struct binder_proc *proc,
uintptr_t user_ptr)
{
struct rb_node *n = proc->allocated_buffers.rb_node;
struct binder_buffer *buffer;
struct binder_buffer *kern_ptr;
//计算内核缓冲区中对应的binder_buffer的地址
kern_ptr = (struct binder_buffer *)(user_ptr - proc->user_buffer_offset
- offsetof(struct binder_buffer, data));
//循环,通过这个buffer地址,找到对应的buffer节点。
while (n) {
buffer = rb_entry(n, struct binder_buffer, rb_node);
BUG_ON(buffer->free);
if (kern_ptr < buffer)
n = n->rb_left;
else if (kern_ptr > buffer)
n = n->rb_right;
else
return buffer;
}
return NULL;
}















 4193
4193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









