






https://www.zhihu.com/question/22786302
选择Hadoop的原因最重要的就是这三点:1,可以解决问题; 2,成本低 ; 3,成熟的生态圈。
作者:曹坤
链接:https://www.zhihu.com/question/22786302/answer/22713512
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一,Hadoop帮助我们解决了什么问题
无论国内还是国外的大公司对于数据都有着无穷无尽的渴望,都会想尽一切办法收集一切数据,
因为通过信息的不对称性可以不断变现,而大量的信息是可以通过数据分析得到的。
数据的来源途径非常的多,数据的格式也越来越多越来越复杂,随着时间的推移数据量也越来越大。
因此在数据的存储和基于数据之上的计算上传统数据库很快趋于瓶颈。
而Hadoop正是为了解决了这样的问题而诞生的。其底层的分布式文件系统具有高拓展性,通过数据冗余保证数据不丢失和提交计算效率,同时可以存储各种格式的数据。
同时其还支持多种计算框架,既可以进行离线计算也可以进行在线实时计算。
二,为什么成本可以控制的低
确定可以解决我们遇到的问题之后,那就必须考虑下成本问题了。
1, 硬件成本
Hadoop是架构在廉价的硬件服务器上,不需要非常昂贵的硬件做支撑
2, 软件成本
开源的产品,免费的,基于开源协议,可以自由修改,可控性更大
3,开发成本
因为属于二次开发,同时因为有非常活跃的社区讨论,对开发人员的能力要求相对不高,工程师的学习成本也并不高
4,维护成本
当集群规模非常大时,开发成本和维护成本会凸显出来。但是相对于自研系统来说的话,还是便宜的很多。
某司自研同类系统几百名工程师近4年的投入,烧钱亿计,都尚未替换掉Hadoop。
5,其他成本
如系统的安全性,社区版本升级频繁而现实是无法同步进行升级所引入的其他隐形成本。
三, 成熟的生态圈有什么好处
成熟的生态圈代表的未来的发展方向,代表着美好的市场前景,代表着更有钱途的一份工作(好吧,“三个代表”).
看图(引自:Hadoop Ecosystem Map • myNoSQL)
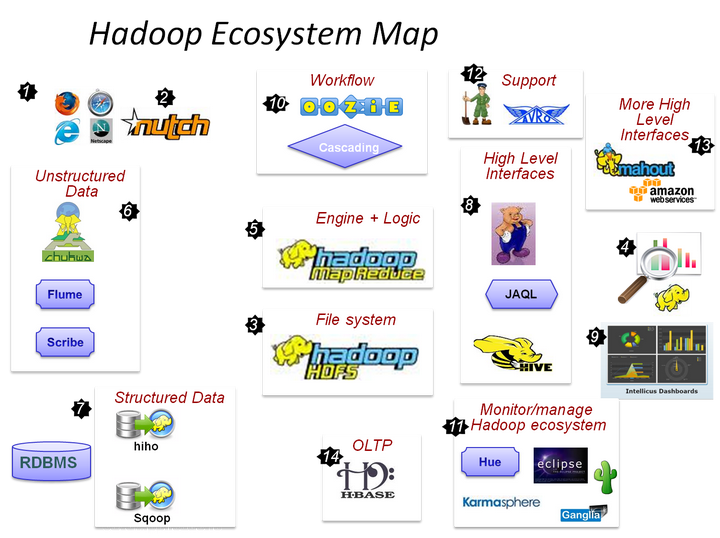
部分系统归类:
部署,配置和监控 Ambari,Whirr
监控管理工具 Hue, karmasphere, eclipse plugin, cacti, ganglia
数据序列化处理与任务调度 Avro, Zookeeper
数据收集 Fuse,Webdav, Chukwa, Flume, Scribe , Nutch
数据存储 HDFS
类SQL查询数据仓库 Hive
流式数据处理 Pig
并行计算框架 MapReduce, Tez
数据挖掘和机器学习 Mahout
列式存储在线数据库 HBase
元数据中心 HCatalog (可以和Pig,Hive ,MapReduce等结合使用)
工作流控制 Oozie,Cascading
数据导入导出到关系数据库 Sqoop,Flume, Hiho
数据可视化 drilldown,Intellicus
使用到的公司也非常的多
(引自: A New Version of the Hadoop Ecosystem Map)
首先,选择Hadoop,其实是选择的的MapReduce,把大块的任务切分为若干份小任务,由集群的每台服务器来计算,最后把结果合并。
这个思想是解决大数据的最直接的方案,一台机器放不下的数据,我用多台机器来解决。这和分治算法的思路是一致的。
那么,为什么选择Hadoop?
因为开源,免费,上万开发者维护了很多年了,资料也很多,使用起来比较容易,出了问题一般之前也有人给你踩过坑写过资料了。
当然了,国内一些实力强的大公司,喜欢自己开发一套MapReduce,其实思想都摆在那里,就是实现而已,有些公司不喜欢用Java,所以就用C、C++自己做。比如腾讯,从Google挖了一批人,来了就先搞一套自己的GFS和MapReduce,实际效果如何呢?开发了一年多,bug很多,只是靠内部关系在推,当初如果直接用Hadoop,也许没这么曲折,据了解搜搜拆分之后,也转到HBase和Hadoop了。
Apache在分布式领域除了Hadoop,还有HBase和Zookeeper这两大杀器。HBase我不太熟,Zookeeper基本是目前分布式一致协作算法里的头牌了,大公司有自己搞MapReduce的,但是自己搞分布式协作算法的不多,基本都直接用zookeeper了,为什么?因为实现起来太难太复杂。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
hadoop 是一种解决方案,Hadoop生态系统发展比较成熟,提供足够多得解决方案或有足够资源帮助解决各种业务问题;同时因为它是大数据概念和行业发展得推广品牌,影响深远而且培养了足够多得人力资源,所以对希望通过大数据来解决问题或提高自身品牌或产品价值得公司来说,就是一个首选得快速进入和低成本选择。
1. 可处理的数据量大。大型互联网公司,单个集群每天要处理的数据量在几十T以上,总容量几百P。这样的数据规模,关系型数据库完全没有能力做。而Hadoop只要机器资源足够就行了,性能基本上线性扩展。集群管理也比较容易。
2. 生态圈完整,海量免费工具。感谢google,facebook等公司的贡献,Hadoop有非常多简单好用的组件。Hive可以让稍微有点数据库经验的人,很快上手开发。FlumeJava让M/R编写和优化也简单了很多。其他不一一列举了。总之就是国外公司已经搞好了一大堆简单好用的东西,免费拿过来用很爽。
3 集群搭建成本低。这个要感谢Cloudera的贡献,想当年搭个hadoop集群还是挺困难的,搞过的同学都懂,无数坑,坑爆卵。而现在搭个几十台的CDH集群,比较容易了,国内大多数集群规模不大的公司,都用的CDH。硬件成本也低,4万1台的服务器,搭个50台的集群,处理能力和容量已经相当不错了,200万如果去买Oracle能买个毛呢。。不过如果要搭上千台的集群,开发成本还是挺高的,国内人也不好招,全被大公司包了。
转载于:https://blog.51cto.com/57388/2106837














 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









