








我在此分享在“ CCF - 大数据时代的Serverless工作负载预测”这一比赛中的实验过程及心得体会。不足之处,还望批评指正。
一、大赛简介
「背景」云计算时代,Serverless软件架构可根据业务工作负载进行弹性资源调整,这种方式可以有效减少资源在空闲期的浪费以及在繁忙期的业务过载,同时给用户带来极致的性价比服务。但传统的资源控制系统以阈值为决策依据,只关注当前监控点的取值,缺少对历史数据以及工作负载趋势的把控,不能提前做好资源的调整,具有很长的滞后性。所以出题方华为希望选手通过算法对未来用户工作负载做出预测。
「数据」本次赛题数据来自华为云数据湖探索(Data Lake Insight,简称DLI)。选取了43个队列数据。对于测试集,赛题会给定该队列在某时段的性能监控数据(比如9: 35– 10:00),希望参赛者可以预测该点之后的未来五个点的指标(10:00 – 10:25)。预测目标是CPU_USAGE和LAUNCHING_JOB_NUMS。具体字段说明如下所示:
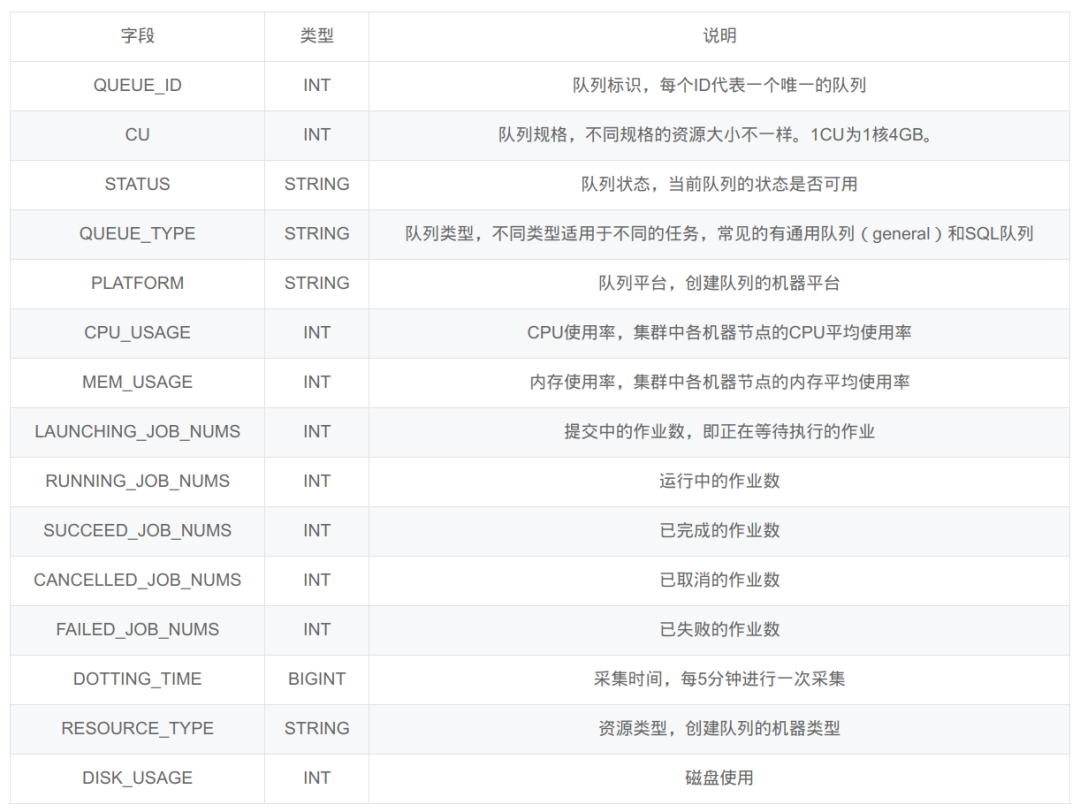
图1:官方字段说明
「评估指标」官方采用绝对误差作为评估指标,评测公式如下(详情可见官网):

图2:官方评测标准
*以上内容均引用于比赛官网 [1]
二、比赛
「时间」2020.11.12 - 2020.12.06
「配置」2080Ti (11G),Ubuntu 16.04, TF
「排名」56(A榜),86(B榜)
1. 数据探索性分析
我主要做了通用的EDA工作并补充了专门针对该业务数据的其他EDA分析:
数据展示
描述性统计
特征相关性分析
异常样本检测
缺失值检测
重复样本检测
其他针对性研究
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









