







这个题目来自于《编程珠玑》第一章的问题的衍生,简化后的需求是这样的:要求生成小于n且没有重复的n个随机整数。
一般而言,各种编程语言都有库函数来供我们生成随机数,但是库函数所生成的随机数可能有重复,为此,面对这个需求,我需要自己编写无重复随机数生成器。考虑到我使用的是php语言,所以结合这个语言所拥有的库函数,我首先很自然的想到使用shuffle函数,这个函数的作用是打乱数组中元素的顺序重新排列,所以,第一种方法的思路是这样的:首先按照给定的范围生成一个数组,数组中每个位置填上对应的整数,即arr[i] = i ,然后使用shuffle函数打乱这个数组重新输出即可。
//生成特定范围不重复的随机数组
//使用shuffle函数
function createRand_shuffle($min, $max)
{
$store = array();
for($i=$min;$i<=$max;$i++)
{
$store[$i] = $i;
}
shuffle($store);
return $store;
}如果某种编程语言库里没有类似PHP的数组洗牌函数shuffle,那么就采用第二种方法,这个方法利用了去重的思想,即仍然使用库函数的随机数发生器,但是为了避免产生重复的数据,需要对生成的数据进行去重处理,因此这里就需要一个标记表来记录已经生成的数据,以便让新生成的数据对照。思路如下:初始化两个数组,一个数组用来存放最终生成的数据,另一个作为Hash去重对照表,每次生成一个数据,首先到Hash去重数组里检查该数据是否已经存在,如果存在,则重新生成数据,否则存入该数据到第一个数组,同时在Hash去重数组里标记该数据,标记采用位图的思想,即对于数据i,标记数组第i位为1。代码如下:
//生成特定范围不重复随机数组
//hash去重法
function createRand_hash($min, $max)
{
$hash = array();
$out = array();
for($i=$min;$i<=$max;$i++)
{
$randnum = rand($min,$max);
while(@$hash[$randnum]==1)
{
$randnum = rand($min,$max);
}
$out[] = $randnum;
@$hash[$randnum]=1;
}
return $out;
} 针对上面这个方法,它的缺点是每次生成一个随机数,都需要到Hash表内进行对比,当Hash表快满时候,对比失败的次数会越来越多,所以为了解决这个问题,有了第三种方法。
第三种方法很巧妙,尤其是它的改进优化方法,很有意思,来源于eaglet的博客
博客作者eaglet是著名中文分词组件盘古分词的作者,我在网上找寻其他思路的时候发现的。
首先讲下优化前的思路:从集合的角度来讲,这个方法的主要思想我认为还是去重,但是不同于第二种方法,这个方法把去重的步奏放到了源数据集合中来做,即每从源集合里面获取一个数据,则将该数据从源集合内删除,保证下次不会再取到这个数据,具体的思路如下:假设n=5,则初始情况,该数组下标与该下标所“装”的数是对应的,如图:

初始化一个顺序数组(长度为n,则下标范围0到n-1)来作为源集合,每获取一个元素(第一个元素范围从0-n),则将该元素从数组里面删除,则下次获取随机数应当位于0-(n-1)之间。

到经过实际验证,发现这个算法的效率好像不是很高,仔细想想,原来根据数据结构知识,知道顺序表删除一个元素需要进行挪位,而挪位是非常耗费时间的,原来如此,现在仔细想想,怎么对这个地方进行改进。
第三种方法的本质思想和第二种一样,都是保证源数据集合中的唯一性,只不过是在具体的实现上做了改变。通过不断更改范围上界来确保源数据集合的唯一性。
为了说明清楚,这里约定用i表示下标序数,c表示内容即数据,n表示长度,同样的采用上图示例,
(1)n=5,获取0-4之间的随机数,即获取0-(n-1)之间的随机数,假设第一次随机出的数组下标为3,则下标为3的数据c=3,将3取出作为获取的随机数,同时将之前的最后一位的数据,即i=n-1上的数据c=4移动到i=3的位置上。如图:


(2)第二次时,假设随机出的下标序数为1,则将i=1位置上的数取出,即c=1,然后i=(n-1)=3位置上的数据即范围上界上的数据c=4挪动到i=1的位置上。
如图:

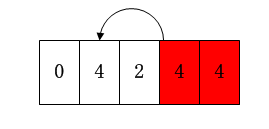
(3)以此类推,直到取出n个数据。
这个方法的具体思路其实就是每次通过挪动范围的上界来将数组划分为两个部分,一个部分是保证唯一性的源数据集合,另一个部分是已经取过的数据集合,只不过是任然在数组中并未删除。
三种方法有各自的特点,具体的性能测试没来得急做,只是将思路罗列出来,日后补充。















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









