







什么是分布式系统
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
分布式系统分为分布式计算(computation)与分布式存储(storage)。计算与存储是相辅相成的,计算需要数据,要么来自实时数据(流数据),要么来自存储的数据;而计算的结果也是需要存储的。在操作系统中,对计算与存储有非常详尽的讨论,分布式系统只不过将这些理论推广到多个节点罢了。
常见的分布式存储系统 : MogileFS、GlusterHS
常见的分布式文件系统有 :GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS
常见追踪系统 : Jaeger、Zipkin等;
分布式是指将不同的业务分布在不同的地方。 而集群指的是将几台服务器集中在一起,实现同一业务。
分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。
分布式系统怎么将任务分发到这些计算机节点 : 分而治之,即分片
存储 ,每个节点存一部分数据就行了。当数据规模变大的时候,Partition是唯一的选择,同时也会带来一些好处:
(1)提升性能和并发,操作被分发到不同的分片,相互独立
(2)提升系统的可用性,即使部分分片不能用,其他分片不会受到影响
分布式系统中有大量的节点,且通过网络通信。单个节点的故障(进程crash、断电、磁盘损坏)是个小概率事件,但整个系统的故障率会随节点的增加而指数级增加。
分布式框架

常见的分布式软件 :
分布式文件存储的数据库 : Mongodb
分布式代码管理工具 : Gitlab
分布式缓存数据结构存储系统 : Redis/Memcached
分布式
分布式
分布式的体系模块
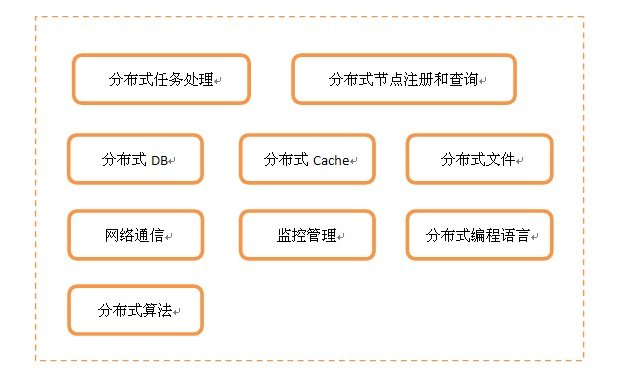
分布式任务处理服务:负责具体的业务逻辑处理
分布式节点注册和查询:负责管理所有分布式节点的命名和物理信息的注册与查询,是节点之间联系的桥梁
分布式DB:分布式结构化数据存取
分布式Cache:分布式缓存数据(非持久化)存取
分布式文件:分布式文件存取
网络通信:节点之间的网络数据通信
监控管理:搜集、监控和诊断所有节点运行状态
分布式编程语言:用于分布式环境下的专有编程语言,比如Elang、Scala
分布式算法:为解决分布式环境下一些特有问题的算法,比如解决一致性问题的Paxos算法
分布式计算系统:
1. 传统基于msg的系统
2. MapReduce-like 系统
3. 图计算系统
4. 基于状态(state)的系统
5. Streaming 系统
主流分布式系统设计分类
1. 分布式存储系统
2. 分布式计算系统
3. 分布式管理系统
分布式存储系统:
1. 结构化存储
2. 非结构化存储
3. 半结构化存储
4. In-memory 存储
分布式存储系统还有一系列的理论、算法、技术作为支撑:例如 Paxos, CAP, ConsistentHash, Timing (时钟), 2PC, 3PC 等等
上述四个子方向概述分类
结构化存储 :典型的场景就是事务处理系统或者关系型数据库(RDBMS)。传统的结构化存储都是从单机做起的,
PostgreSQL 也是近几年来势头非常强劲的一个 RDBMS. 我们发现,传统的结构化存储系统强调的是:(1)结构化的数据(例如关系表)。(2)强一致性 (例如,银行系统,电商系统等场景)(3)随机访问(索引,增删查改,SQL 语言)。
非结构化存储 (no-structed storage systems) : 非结构化存储强调的是高可扩展性,典型的系统就是分布式文件系统。
扩展
大数据组成部分
• HDFS: 分布式存储系统,包含NameNode,DataNode。
NameNode:元数据,DataNode。
DataNode:存数数据。
arn: 可以理解为MapReduce的协调机制,本质就是Hadoop的处理分析机制,分为ResourceManager NodeManager。 • MapReduce: 软件框架,编写程序。
• Hive: 数据仓库 可以用SQL查询,可以运行Map/Reduce程序。用来计算趋势或者网站日志,不应用于实时查询,需要很长时间返回结果。
• HBase: 数据库。非常适合用来做大数据的实时查询。Facebook用Hbase存储消息数据并进行消息实时的分析;
• ZooKeeper: 针对大型分布式的可靠性协调系统。Hadoop的分布式同步等靠Zookeeper实现,例如多个NameNode,active standby切换。
• Sqoop: 数据库相互转移,关系型数据库和HDFS相互转移Mahout: 可扩展的机器学习和数据挖掘库。用来做推荐挖掘,聚集,分类,频繁项集挖掘。
常见问题 :
1. 近些年分布式系统领域都在做些什么。
2. 为什么现在投入分布式系统的学习和研究是值得的。
分布式系统挑战
第一,异构的机器与网络:
分布式系统中的机器,配置不一样,其上运行的服务也可能由不同的语言、架构实现,因此处理能力也不一样;节点间通过网络连接,而不同网络运营商提供的网络的带宽、延时、丢包率又不一样。怎么保证大家齐头并进,共同完成目标,这四个不小的挑战。
第二,普遍的节点故障:
虽然单个节点的故障概率较低,但节点数目达到一定规模,出故障的概率就变高了。分布式系统需要保证故障发生的时候,系统仍然是可用的,这就需要监控节点的状态,在节点故障的情况下将该节点负责的计算、存储任务转移到其他节点
第三,不可靠的网络:
节点间通过网络通信,而网络是不可靠的。可能的网络问题包括:网络分割、延时、丢包、乱序。
相比单机过程调用,网络通信最让人头疼的是超时:节点A向节点B发出请求,在约定的时间内没有收到节点B的响应,那么B是否处理了请求,这个是不确定的,这个不确定会带来诸多问题,最简单的,是否要重试请求,节点B会不会多次处理同一个请求。
分布式系统特性
可扩展性
可用性与可靠性
高性能
一致性
常见的分布式文件系统:
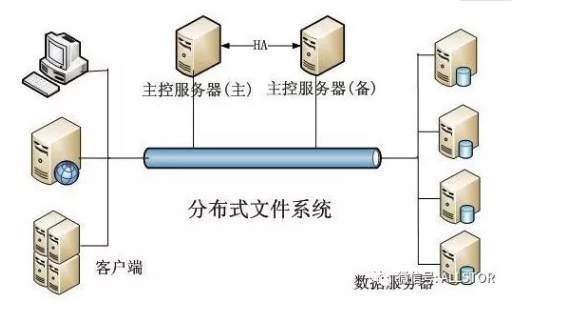
分布式构架图

概念与实现
- 负载均衡:
Nginx:高性能、高并发的web服务器;功能包括负载均衡、反向代理、静态内容缓存、访问控制;工作在应用层
LVS: Linux virtual server,基于集群技术和Linux操作系统实现一个高性能、高可用的服务器;工作在网络层
- webserver:
Java:Tomcat,Apache,Jboss
Python:gunicorn、uwsgi、twisted、webpy、tornado
- service:
SOA、微服务、spring boot,django
- 容器:
docker,kubernetes
- cache:
memcache、redis等
- 协调中心:
zookeeper、etcd等
zookeeper使用了Paxos协议Paxos是强一致性,高可用的去中心化分布式。zookeeper的使用场景非常广泛,之后细讲。
- rpc框架:
grpc、dubbo、brpc
dubbo是阿里开源的Java语言开发的高性能RPC框架,在阿里系的诸多架构中,都使用了dubbo + spring boot
- 消息队列:
kafka、rabbitMQ、rocketMQ、QSP
消息队列的应用场景:异步处理、应用解耦、流量削锋和消息通讯
- 实时数据平台:
storm、akka
- 离线数据平台:
hadoop、spark
PS: apark、akka、kafka都是scala语言写的,看到这个语言还是很牛逼的
- dbproxy:
cobar也是阿里开源的,在阿里系中使用也非常广泛,是关系型数据库的sharding + replica 代理
- db:
mysql、oracle、MongoDB、HBase
- 搜索:
elasticsearch、solr
- 日志:
rsyslog、elk、flume
常见的分布式文件系统有,GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS
GFS(Google File System)
--------------------------------------
Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
使用Master->Slave设计,元数据信息主要由Master管理,这样的设计大大降低系统的实现难度。

为防止Master压力过大,限制了数据存储大量,GFS中数据存储单元使用Chunk表示,Chunk支持64M。
Master节点掌握整个集群数据存储核心数据,集群扩展能力受限于master节点内存,比如:大量小文件导致元数据信息爆满。
分布式文件系统多副本,可支持容错的读取数据,根据负载情况,最近副本取数据。
因为集群支持容错,故障自动恢复,所以整个集群可以扩展到很大规模,在传统MPI、MPP中无法支持很大规模。
而今天我们也看到MPP和
下面分布式文件系统都是类 GFS的产品。
热点数据
在分布式非结构化数据存储中,是非常常见的,比如我们某个公共库文件或程序,为使用方便和容错,大家把它存储在HDFS,它被切块存储于100个节点的集群某3个机器中,由于大量业务系统或者程序随机加载引用,导致某3个机器压力特别大,看到监控系统飘红。
我们可以通过增加副本数量,来让更多副本能提供访问服务,解决问题。
早期使用MapReduce/Spark系统,为缩短计算时间,默认3副本,我们提高到6,9个,增加数据本地化计算的几率。
-
元数据
集群扩展Slave受限于Master节点内容,元数据信息都存在Master,并且常驻内存,大量小文件也会造成Master性能下降。
-
快照
使用copy-on-writer实现,基本上不会对现有数据读取有影响。
只读数据存储
[1] 适合追加方式的写入和读取操作
[2] 很少有随机写入操作
目前HDFS,GFS主要用来存储海量的离线数据,提供海量非结构化数据存储场景。
如果需要支持随机写、更新、删除数据,就选其他系统,比如:Kudu
冗余解决方案
容错考虑需要,有三倍冗余,目前主要有Erasure Codes实现,奇偶校验方法,可以缩小大量存储占用。
注意:
[1] 没有在文件系层面提供任何的Cache机制,访问顺序读取加载大量文件,Cache支持意义不大
[2] 单个应用执行时机会不会重复读取数据
[3] GFS/HDFS适合流式读取一个大型数据集
[4] 在大型数据集中随机seek到某个位置,之后每次读取少量数据,提升效率。
[5] GFS/HDFS设计预期是使用大量的不可靠节点组件集群,因此,灾难冗余是此类系统设计的核心。
[6] 存储固定大小的Chunk,容易重新均衡数据。
[7] 原子记录追加,保障系统数据一致性。
[8] 中心Master设计,让复杂的分布式系统实现简单化,不用考虑数据一致性,元数据同步问题。
GFS/HDFS设计初衷,保障有大量并发读写操作时,能够提供很高的合计吞吐量。
通过分离控制流(Master)和数据流(Chunk client)来实现,所以我们经常提起的Edge节点会对整个系统性能有很大的影响。
Master节点负载过高,通过Chunk租约将控制权交给主副本(主Chunk),将Master压力降到最低。
目前类似GFS的开源实现,主流选择HDFS,而且HDFS在实现上,弥补很多GFS中的不足。我也没看到有可替代HDFS的系统,因为有HDFS造就今天繁荣的Hadoop生态系统,数据分析引擎、数据存储引擎百花齐放。
软件系统的设计与实现是为解决现实问题而出现,设计上会有很多权衡,不同的权衡造就不同的系统,各自有擅长的场景。
HDFS
--------------------------------------
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
Ceph
---------------------------------------
是加州大学圣克鲁兹分校的Sage weil攻读博士时开发的分布式文件系统。并使用Ceph完成了他的论文。
说 ceph 性能最高,C++编写的代码,支持Fuse,并且没有单点故障依赖, 于是下载安装, 由于 ceph 使用 btrfs 文件系统, 而btrfs 文件系统需要 Linux 2.6.34 以上的内核才支持。
可是ceph太不成熟了,它基于的btrfs本身就不成熟,它的官方网站上也明确指出不要把ceph用在生产环境中。
Lustre
---------------------------------------
Lustre是一个大规模的、安全可靠的,具备高可用性的集群文件系统,它是由SUN公司开发和维护的。
该项目主要的目的就是开发下一代的集群文件系统,可以支持超过10000个节点,数以PB的数据量存储系统。
目前Lustre已经运用在一些领域,例如HP SFS产品等。
FastDFS
---------------------------------------
是一款类似Google FS的开源分布式文件系统,是纯C语言开发的。
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS 是一个由 C 语言实现的开源轻量级分布式文件系统,
FastDFS is an open source high performance distributed file system (DFS). It's major functions include: file storing, file syncing and file accessing, and design for high capacity and load balance.
翻译 : FastDFS 是一个开源的高性能分布式文件系统(DFS)。 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡。
官方论坛 http://bbs.chinaunix.net/forum-240-1.html
FastDfs google Code http://code.google.com/p/fastdfs/
分布式文件系统FastDFS架构剖析 http://www.programmer.com.cn/4380/
TFS
-------------------------------------
TFS(Taobao !FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
官网 : http://code.taobao.org/p/tfs/wiki/index/
GridFS文件系统
-------------------------------------
MongoDB是一种知名的NoSql数据库,GridFS是MongoDB的一个内置功能,它提供一组文件操作的API以利用MongoDB存储文件,GridFS的基本原理是将文件保存在两个Collection中,一个保存文件索引,一个保存文件内容,文件内容按一定大小分成若干块,每一块存在一个Document中,这种方法不仅提供了文件存储,还提供了对文件相关的一些附加属性(比如MD5值,文件名等等)的存储。文件在GridFS中会按4MB为单位进行分块存储。
一、什么是事务
普通数据库事务(简称:事务,Transaction)是指一个单数据库节点执行过程中的一个逻辑单位由一个有限的数据库操作序列构成,这一系列数据库操作序列组成的逻辑单位具有强原子性,或全部执行,或全部不执行。该事务拥有以下四个特性,习惯上被称为 ACID 特性:
-
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
-
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态是指数据库中的数据应满足完整性约束。除此之外,一致性还有另外一层语义,就是事务的中间状态不能被观察到(这层语义也有说应该属于原子性)。
-
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这一个操作在被数据库所执行一样。
-
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,此操作将不可逆转。
普通数据库事务的单节点性,所以也叫本地事务。如下是普通事务的架构形态:

相对于普通数据库事务而言,分布式事务是指会涉及到操作多个数据库节点的事务,事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于分布式的不同数据库节点上,是将对单库事务的概念扩大到了对多个库的事务,分布式事务方案也是为了保证分布式系统中各个数据库节点的数据一致性。 普通数据库事务具有强一致性特点。分布式事务则不同,根据数据一致性的强弱要求,分布式事务分刚事务和柔事务。
-
刚事务:遵从ACID理论,实际中因为考虑用户体验和并发性能,很少有遵从ACID的分布式事务实施方案
-
柔事务:遵从CAP理论或其变种BASE理论的事务,主流分布式事务一致性方案都属于这类
如下是当前常见的分布式事务的架构形态:

二、分布式事务一致性指导方案
为了解决分布式事务一致性问题,前人在性能和数据一致性的权衡过程中总结了许多经典的协议和算法。比较著名的有:XA协议、2PC、3PC、TCC、Paxos、Raft、Zab、ISR、SAGA模型、最大努力型。当然,除了这些之外,业界用的最多的其实是基于MQ实现。本文列举具有代表性的几个方案进行概述讲解。
三、指导方案分析
XA协议:
最早的分布式事务模型是 X/Open 国际联盟提出的 X/Open Distributed Transaction Processing(DTP)模型,也就是大家常说的 X/Open XA 协议,简称XA 协议。
XA模型由2部分组成:全局事务管理(调度)器(TM)和本地资源管理(RM),本地资源管理器往往由数据库实现,事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。XA 协议描述了 TM 与 RM 之间的接口,允许多个资源在同一分布式事务中访问。XA实现分布式事务的原理如下:
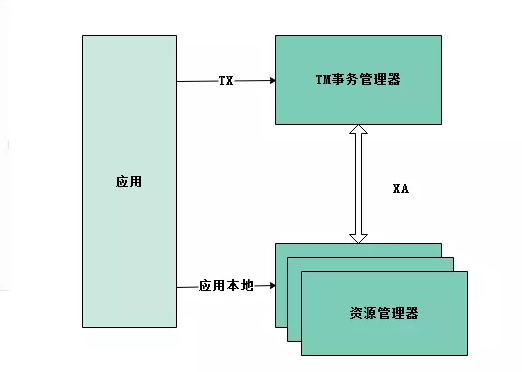
XA使用2PC提交保证原子性:
1. 应用程序(AP,Application)向 TM 申请开始一个全局事务。
2. 针对要操作的 RM,AP 会先向 TM 注册(TM 负责记录 AP 操作过哪些 RM,即分支事务),TM 通过 XA 接口函数通知相应 RM 开启分布式事务的子事务,接着 AP 就可以对该 RM 管理的资源进行操作。
3. 当 AP 对所有 RM 操作完毕后,AP 根据执行情况通知 TM 提交或回滚该全局事务,TM 通过 XA 接口函数通知各 RM 完成操作。TM 会先要求各个 RM 做预提交,所有 RM 返回成功后,再要求各 RM 做正式提交,XA 协议要求,一旦 RM 预提交成功,则后续的正式提交也必须能成功;如果任意一个 RM 预提交失败,则 TM 通知各 RM 回滚。
4. 所有 RM 提交或回滚完成后,全局事务结束。
XA优点:满足原子性、隔离性。
XA缺点:太依赖数据库层事务、锁,影响性能开销,存在数据不一致性(不过所有分布式事务方案都不是强一致性事务)
总的来说,XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
2PC:
XA协议中保证事务原子性的机制就是使用2PC 。
二阶段提交(Two-phaseCommit)是指,在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。通常,二阶段提交也被称为是一种协议(Protocol))。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
所谓的两个阶段是指:第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。
准备阶段:
事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交。
准备阶段细化为如下三件事:
1.协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响应。
2.参与者节点执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志。(注意:若成功这里其实每个参与者已经执行了事务操作)
3.各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返回一个”同意”消息;如果参与者节点的事务操作实际执行失败,则它返回一个”中止”消息。
提交阶段:
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源),下图描述了2pc成功和失败的过程:
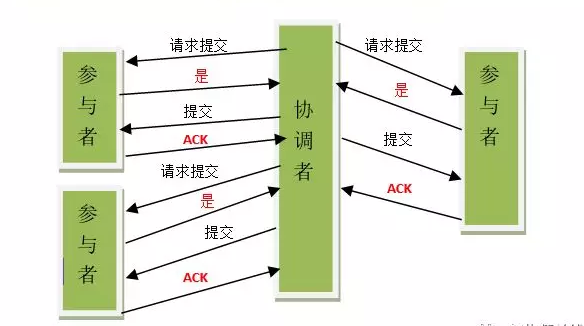

二阶段提交能够提供原子性的操作,但是具有如下几个缺点:
1. 同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2. 单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
3. 数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
4. 二阶段无法解决的问题:协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
由于二阶段提交存在着诸如同步阻塞、单点问题、脑裂等缺陷,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。
3PC:
三阶段提交(Three-phase commit),也叫三阶段提交协议(Three-phase commit protocol),是二阶段提交(2PC)的改进版本。
PC除了引入超时机制外,将事务过程分为3个阶段:CanCommit、PreCommit、DoCommit:
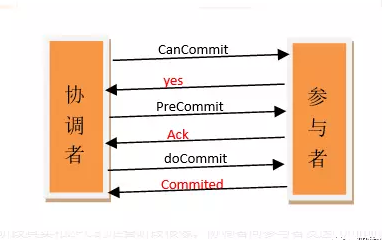
CanCommit:
3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
1. 事务询问:协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
2. 响应反馈:参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No 。
PreCommit:
协调者根据CanCommit阶段参与者的反应情况来决定是否可以继续事务的PreCommit操作。根据响应情况,有以下两种可能。
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
1. 发送预提交请求:协调者向参与者发送PreCommit请求,并进入Prepared阶段。
2. 事务预提交:参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
3. 响应反馈 如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
如CanCommit阶段有任何一个参与者向协调者发送No响应或者PreCommit阶段的任何一个参与者返回操作失败,或者协调者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
1. 发送中断请求 协调者向所有参与者发送abort请求。
2. 中断事务 参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
doCommit阶段:
该阶段进行真正的事务提交,也可以分为以下两种情况。
执行提交:
1. 发送提交请求:协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。
2. 事务提交:参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
3. 响应反馈:事务提交完之后,向协调者发送Ack响应。
4. 完成事务:协调者接收到所有参与者的ack响应之后,完成事务。
中断事务:
协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
1. 发送中断请求 协调者向所有参与者发送abort请求
2. 事务回滚 参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
3. 反馈结果 参与者完成事务回滚之后,向协调者发送ACK消息
4. 中断事务 协调者接收到参与者反馈的ACK消息之后,执行事务的中断。
2PC与3PC区别:
相对于2PC,3PC主要解决单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
TCC(Try-Confirm-Cancel)方案:
TCC是由支付宝架构师提供的一种柔性解决分布式事务解决方案,TCC(Try-Confirm-Cancel)分布式事务模型相对于 XA 等传统模型,其特征在于它不依赖资源管理器(RM)对分布式事务的支持,而是通过对业务逻辑的分解来实现分布式事务。
支付宝官网提到,TCC 模型认为对于业务系统中一个特定的业务逻辑,其对外提供服务时,必须接受一定不确定性,即对业务逻辑初步操作的调用仅是一个临时性操作,调用它的主业务服务保留了后续的取消权。如果主业务服务认为全局事务应该回滚,它会要求取消之前的临时性操作,这就对应从业务服务的取消操作。而当主业务服务认为全局事务应该提交时,它会放弃之前临时性操作的取消权,这对应从业务服务的确认操作。每一个初步操作,最终都会被确认或取消。
根据具体的业务服务,TCC分布式事务模型需要业务系统提供如下三段业务逻辑:
1. 初步操作 Try:完成所有业务检查,预留必须的业务资源。
2. 确认操作 Confirm:真正执行的业务逻辑,不作任何业务检查,只使用 Try 阶段预留的业务资源。因此,只要 Try 操作成功,Confirm 必须能成功。另外,Confirm 操作需满足幂等性,保证一笔分布式事务有且只能成功一次。
3. 取消操作 Cancel:释放 Try 阶段预留的业务资源。同样的,Cancel 操作也需要满足幂等性。
TCC 分布式事务模型包括三部分:
1. 主业务服务:主业务服务为整个业务活动的发起方,服务的编排者,负责发起并完成整个业务活动。
2. 从业务服务:从业务服务是整个业务活动的参与方,负责提供 TCC 业务操作,实现初步操作(Try)、确认操作(Confirm)、取消操作(Cancel)三个接口,供主业务服务调用。
3. 业务活动管理器:业务活动管理器管理控制整个业务活动,包括记录维护 TCC 全局事务的事务状态和每个从业务服务的子事务状态,并在业务活动提交时调用所有从业务服务的 Confirm 操作,在业务活动取消时调用所有从业务服务的 Cancel 操作。
一个完整的 TCC 分布式事务流程如下:
1. 主业务服务首先开启本地事务;
2. 主业务服务向业务活动管理器申请启动分布式事务主业务活动;
3. 然后针对要调用的从业务服务,主业务活动先向业务活动管理器注册从业务活动,然后调用从业务服务的 Try 接口;
4. 当所有从业务服务的 Try 接口调用成功,主业务服务提交本地事务;若调用失败,主业务服务回滚本地事务;
5. 若主业务服务提交本地事务,则 TCC 模型分别调用所有从业务服务的 Confirm 接口;若主业务服务回滚本地事务,则分别调用 Cancel 接口;
6. 所有从业务服务的 Confirm 或 Cancel 操作完成后,全局事务结束。
TCC 分布式事务模型仅提供两阶段原子提交协议,保证分布式事务原子性。事务的隔离交给业务逻辑来实现。TCC 模型的隔离性思想就是通过业务的改造,在第一阶段结束之后,从底层数据库资源层面的加锁过渡为上层业务层面的加锁,从而释放底层数据库锁资源,放宽分布式事务锁协议,提高业务并发性能。
总之,TCC 分布式事务模型的业务实现特性决定了其可以跨 DB、跨服务实现资源管理,将对不同的 DB 访问、不同的业务操作通过 TCC 模型协调为一个原子操作,解决了分布式应用架构场景下的事务问题。TCC 模型通过 2PC 原子提交协议保证分布式事务的的原子性,把资源层的隔离性上升到业务层,交给业务逻辑来实现。TCC 的每个操作对于资源层来说,就是单个本地事务的使用,操作结束则本地事务结束,规避了资源层在 2PC 和 2PL 下对数据库资源占用导致的性能低下问题。
基于MQ实现:
消息中间件在分布式系统中的主要作用:异步通讯、解耦、并发缓冲。基于MQ实现分布式事务一致性是一种异步确保型的实现方案,将同步阻塞的事务变成异步的,避免对数据库事务的争用。
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功并且对外发消息成功,要么两者都失败,阿里开源的RocketMQ就支持这一特性,具体原理如下:
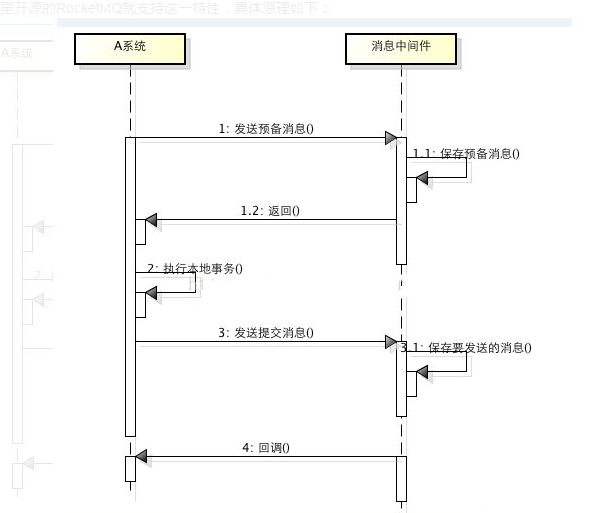
事务过程分为4步:
1. A系统向消息中间件发送一条预备消息
2. 消息中间件保存预备消息并返回成功
3. A执行本地事务
4. A发送提交消息给消息中间件
通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
步骤1出错,则整个事务失败,不会执行A的本地操作
步骤2出错,则整个事务失败,不会执行A的本地操作
步骤3出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
步骤4出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务。
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:
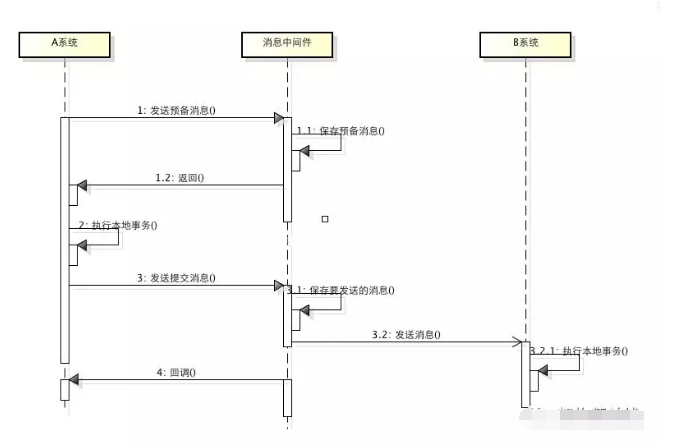
上面的方案能够完成A和B的操作,但A和B并不是严格一致,而是最终一致的,这里牺牲了一致性,换来了性能的大幅度提升。所以这种玩法也是有风的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
总之,基于可靠消息队列的最终一致性这个假设前提,事务消息的MQ方案是目前公认的较为理想的分布式事务解决方案,各大电商都在应用这一方案。这种方式适合的业务场景广泛,而且可靠。不过目前主流的开源MQ(ActiveMQ、RabbitMQ、Kafka)均未实现对可靠消息队列及事务的支持,所以需二次开发或者新造轮子,所以也是成本最大的。
四、结束语
本文一开始讲解了什么是分布式事务及分布式事务的架构场景,然后从 XA 、2PC、3PC、TCC 、基于MQ这些典型方案, 讲述了这些常用的分布式事务模型,介绍了其实现机制和优缺点。后续的文章我们会详细分章节介绍主流分布式事务的技术实施细节及相关中间件。
参考链接:
https://mp.weixin.qq.com/s/dCQKjrURQ2pn1_lqWlorBg
https://blog.csdn.net/m0_37450089/article/details/80215231
转载自Itweet的博客 :文章集合: http://www.itweet.cn/blog/archive
链接:
分布式系统和事务的实现原理 : https://mp.weixin.qq.com/s/vrPby2KwNeFxvpHNzAu7qw
什么是分布式消息中间件? : https://www.cnblogs.com/hzmark/p/mq.html
MQ ( 16篇 ) : https://www.cnblogs.com/hzmark/category/1025980.html

Rabbitmq集群高可用部署详细 : https://www.cnblogs.com/knowledgesea/p/6535766.html
.Net使用RabbitMQ详解 : https://www.cnblogs.com/knowledgesea/p/5296008.html
分布式系统 : https://www.cnblogs.com/hzmark/category/1203121.html

centos 系统下安装配置FastDFS步骤分享 : https://www.jb51.net/os/RedHat/61572.html
分布式文件系统设计,该从哪些方面考虑? : https://mp.weixin.qq.com/s/cZTvaoKHqrjpj9lmbePurA
分布式事务介绍:https://mp.weixin.qq.com/s/WHWNAOK4C8wgd4CjcWviHQ
分布式文件系统:原理、问题与方法 : https://mp.weixin.qq.com/s?src=3×tamp=1535250605&ver=1&signature=vx*N7EvfFqpmUOjwGF9wUIcxy31qP2i1s0ow3-ZGdLH8ashU2glg5Dt8yNC331AbxVfIplgM4Az-jygABJwdRjs*UoMkcbZL4xfLpnB5oRANlSb*EBajphoo0xvvY0oJ8QEDGxAYL9*wZoTLXkJnd7XxmMihBCjg*kfVpzOqEVY=
分布式文件系统FastDFS详解 :https://mp.weixin.qq.com/s?src=11×tamp=1535250605&ver=1083&signature=tJEC0IqAT2O5JH80u44PlSET2YirDw41lIAMCTrTgcxeAjgHeyBtOK3Ly9PlRqHM4X4iQ2Qn4AV4wnRf9J2kQeHstn0kfctbBK9F4ToYKUx*it-vx-xR-Fw7tsqAczXm&new=1
架构之路搭建FastDFS分布式文件系统 :https://mp.weixin.qq.com/s?src=11×tamp=1535250605&ver=1083&signature=XSeIInfunYFwfG9vcl7rTSiyJx-VSHqVP83GetVy7CH3-lvGxogfZGKGANleAgamgEBPUZVuwGAbqA-w18hdRh1BZiNqiWLg9qlTch3HAk1ePoarwGJyYk4UyU8U2ym*&new=1
分布式文件系统FastDFS如何做到高可用 : https://mp.weixin.qq.com/s?src=11×tamp=1535250605&ver=1083&signature=RFIh9fGMVdp8HBAViHMf4LKHRgOJvEwQsmxPF-xQFlmxyiCuhgS6LXk-8jck1H9w-HI139t419FdDIH5ghMUltp*jls9LAyzPtSJER5e-pQYrVrcOrpUYHS3QA-W8IN7&new=1
分布式文件系统FastDFS架构剖析 : https://mp.weixin.qq.com/s?src=3×tamp=1535252384&ver=1&signature=rPPUC6IxXtg-sD2Tj*NF89QdXmOOJtvp9x-bO*AcH*TGv7YbB3QOGkrDTysmxxHp3MYyAV*j268PdOjOKTFUzdC9SWoU9nVFpE-XtdrIs446XLn7cfHpApTqXQ*yOKCfcupOenuevak3fKzJG1PAFg==
干货 | 分布式文件系统 - FastDFS(一) : https://mp.weixin.qq.com/s?src=3×tamp=1535252618&ver=1&signature=*kjuZWR9tISwgU4sdz8HLpyAuBYPKIbizZYd8Tb3-I1U9UpdrYgPb5a7QbEdBsUWtUqNynKCQv**M2I1t9IjWSc0Yuggt13xjI2zM-TqsNeSPxLbz3SpjMmw4*Ivhg2YqnpBvCdDwMsp0X4ubQ8hfX0Udpq3qp84GPS1fU3O22w=
FastDFS高性能分布式文件系统 :https://mp.weixin.qq.com/s?src=11×tamp=1535252618&ver=1083&signature=kgl8ktTnJRr4pOzJKXFD7pS*d7aDLXCUuiFpjPQBonmZmR*I-DeSqUv9yiDw5UwiQYQTPFL62PdK*V7*zcpTJrhR1nbRkaIQUyxVev28VBN8674EHg9bHq2pt6v1IREx&new=1
干货 | 分布式文件系统 - FastDFS 配置 Nginx 模块及上传测试(完结篇) :https://mp.weixin.qq.com/s?src=3×tamp=1535252618&ver=1&signature=*kjuZWR9tISwgU4sdz8HLpyAuBYPKIbizZYd8Tb3-I1LoeT0MTN*D6jQMDYLcSEDO-pWGC*m-5bXHud4fWJHjDMseLinSt1sVQ-99IBTKSHiO*4-nK5h9Y-WA1wtdh1xjAZodfn0jOoUh6OyaPzAayEHzsbdTsBO4Dxlhri2V*8=
干货 | 分布式文件系统 - FastDFS 在 CentOS 下配置安装部署 :https://mp.weixin.qq.com/s?src=3×tamp=1535252618&ver=1&signature=*kjuZWR9tISwgU4sdz8HLpyAuBYPKIbizZYd8Tb3-I3szzLAqcQXYlAhjLSRmUeb4YyXsA5gErU*JFC6*Avsa8*aAuimt6LQsQtdAG-bx2lfJbiCub1Veb3FQOXUMByA5qPA-ha8WTvF4kZV2xz4dJiSa5mzEiqddSqxQdATKkk=
项目架构之FastDFS分布式文件系统 : https://mp.weixin.qq.com/s?src=11×tamp=1535267942&ver=1083&signature=qslhqnZEz9zvCjKPlGtWkToFbQ1oAVd0ctTiDBoaIeYTomVToickyVHKpCiMlXSRCJLM0N0FMHltQagMjo1NjhYZehE6*jFaqe28AgTjdoWex6R7lWMhUL8A7uu9UKG3&new=1
FastDFS分布式文件系统 : https://mp.weixin.qq.com/s?src=11×tamp=1535267942&ver=1083&signature=ncBzyxafFAXv-iQUpp83emAbqq0ot0G3DMDBNYhv0IohbCH1qKfKWQt5UvsYUWj8*Olc7W7Z6FFhmqD1JNTNm1AfquRh3Rdl3wIcUmMSidy1OBtaMUB2eSGPZFoTNm8K&new=1
FastDFS 分布式文件系统的安装与使用(单节点) : https://mp.weixin.qq.com/s?src=11×tamp=1535267942&ver=1083&signature=75cVDME8QkLJwTyFRc9sfsmZW0FpgPnEh9fp4bJQlMxRouDi98UN*lke0qbRiBC6qKKXgfqUWv6mLTy*PPr*BJvdePOBTDNO0E3B0Oc7dEDQdCGUuqbz6ITFIMc-kimQ&new=1
分布式文件系统FastDFS介绍及搭建部署完整流程 : https://mp.weixin.qq.com/s?src=11×tamp=1535268195&ver=1083&signature=2SFG3TxTLfbegAfMoHBvmuFB*acd9I6HeQR0TspIeZAwJkqKuwgxsHY4DyVLs*6cLCGb*StyeMP*nbDobNdeX7BI1Em2F6EA-pzq9hw5e3pZYU-rNq7X9BO-3Mbw4P0u&new=1
分布式文件管理系统FastDFS : https://mp.weixin.qq.com/s?src=11×tamp=1535269195&ver=1083&signature=dpgkjQy4jb0hihpDqRmBKtHywEx8yu4w4oLZ75T7sHhZPUySM-bkoszg857a91sV9bJIa3xa-DDdXPuYQpDgZ1wOwOCWMNQAwA8CTVLaEu35ISoTFq1VXndFyUm8WmB*&new=1
分布式 or SAN文件系统、SAS交换为何普及难? : https://mp.weixin.qq.com/s?src=3×tamp=1535269195&ver=1&signature=HAa4AgVAbUJmuheQjSSZGZcnuaSy4vC55F*SKwDMJzxmk-ULk2sRiT9XLoNgFGfQDxuJg0IJWn2uUAGLkdDz7K6fuVw2kLUDwLghPtbC0YqD6aIK2FRgcwgJFr9AMBXaNL25GQKhOi*fwwwjX-RS4A==
案例:HDFS分布式文件系统 : https://www.sogou.com/tx?ie=utf-8&hdq=sogou-addr-cc9657884708170e&query=%E6%A1%88%E4%BE%8B%EF%BC%9AHDFS%E5%88%86%E5%B8%83%E5%BC%8F%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F
GlusterFS分布式文件系统使用简介: https://mp.weixin.qq.com/s?src=3×tamp=1535252384&ver=1&signature=L1C7usG9nhuvVUS9dkoQ4L0C3uwt3mRI*sGWWChs3izzW7cdYuNpkTK2HixU11NmRGlUrsm1K*35IxNR8BaJr561nAgXz0IykwhfoLRZyNhqRZ*-D8iFCP73NxgDnXNR0NELUHpYeKpQcEkjLICPfG1Yb5dJUIqC2yP8zjMFz1w=
Gluster FS分布式文件系统 : https://mp.weixin.qq.com/s?src=3×tamp=1535268195&ver=1&signature=VKBEOhsvHdcT1qUa778fPvxtVbYBJ6IWJS0O9tJvlAwq1MlxQ1cj8YCQtSFYtvUMB-AR-PgOXJpa9rxy0OZTKzTVk7ONpFX-CbFpPBTuqC3b-XivI0aWu7JEaHZcTPVr7BEXbtjV8OKovjZXz8OX6g==
Google分布式文件系统(GFS) : https://mp.weixin.qq.com/s?src=3×tamp=1535268195&ver=1&signature=ZEtptritsk29pYA7lHS-7wjBZnSHIMvaTujfm5i-6CCEYCOaePbdZtRwDFnNpSI4xdBJAKiZTGPiRF4KUEoI*twryqyswxfjk0Tp91CG2nWkAOYs6qyTj8LpNdscOq0EE-boP3IzR1p2u-n5-ptqHQ==
分布式文件系统Mogilefs介绍 : https://mp.weixin.qq.com/s?src=3×tamp=1535252384&ver=1&signature=L1C7usG9nhuvVUS9dkoQ4L0C3uwt3mRI*sGWWChs3ix9ur8Uf1*Kp9gNB4agA2U1I5MC1mDnarFJEQR2GEuo2ptOFDHTrIvoqRn2SZ9dpWCMobg*UktDl*VNu*PQ8*sAiX0AWTWa9W6QuD2O2EvtwNZ3lnvttqmMVeW-HwOpMl4=
淘宝分布式文件系统TFS设计 : https://mp.weixin.qq.com/s?src=3×tamp=1535252384&ver=1&signature=rPPUC6IxXtg-sD2Tj*NF89QdXmOOJtvp9x-bO*AcH*Tw6hUV6maokZVrSdQO7XR35iyGbiHENEflmAwsOrdsy7dMJ*mp3o1VX1SqqAnEZJc7as2WZeApDCBzF5FZkJXCd16gRA25TIdx388pwatDfg==
spark
浅谈Spark RDD API中的Map和Reduce : https://www.jb51.net/article/126333.htm
Spark三种属性配置方式详解 : https://www.jb51.net/article/126324.htm
Spark实现K-Means算法代码示例 : https://www.jb51.net/article/126031.htm
Spark运行时产生的临时目录的问题 : https://www.ixdba.net/archives/2018/08/1250.htm
spark client mode和cluster mode的区别 : https://www.ixdba.net/archives/2018/08/1233.htm
Spark多种运行模式以及每种模式的执行方法 : https://www.ixdba.net/archives/2018/08/1192.htm
扫盲:Hadoop分布式文件系统(HDFS)基础概念讲解! :https://mp.weixin.qq.com/s?src=11×tamp=1535252618&ver=1083&signature=i1zSWfI8X*TgJufQD4xkjNdw*ENFDeFKwWIKp4H3Eser3t6q6OhLpgl1CR1tjdbj8tV05FQuLOsGwxqeqoneL9U-kBZc0*gZz8ZtGVBKBVw4gTJB7HN6OrBpIpaH576B&new=1
区块链给我们带来什么-IPFS分布式文件系统 :https://mp.weixin.qq.com/s?src=11×tamp=1535252618&ver=1083&signature=-y0HgciTaSc1dZeKKaZJDZB0DGu3ZObLE*r60JWE3Ce1qnpQxDKBeBSDSLtoulJ39CUQ88KDaLTTme1HMA4rt34Je6E6*-N*-AesmDpzcKpxBLfHcUbeICU3Q*pE3FqZ&new=1
IPFS—点对点的分布式文件系统(三) :https://mp.weixin.qq.com/s?src=11×tamp=1535267655&ver=1083&signature=QSxEFMEKiHFYTzOWfJQf40XNSWkWRAFKqSjV5Qsb5rQk1olMHWPnu4oS4ivoPDFVodPt2ubKGEOHbRK8sOSwzNzQLf44xO8LUiN0ml6yUcL0iYUcyC3MGlDZbFedv3EA&new=1
IPFS—点对点的分布式文件系统(二) :https://mp.weixin.qq.com/s?src=11×tamp=1535267655&ver=1083&signature=QSxEFMEKiHFYTzOWfJQf40XNSWkWRAFKqSjV5Qsb5rQ9TBGYWvxUMYOyO-gOqdiw1SN-Uxe2pdHmf7ZiCoMo4AFiTJnGFwz6zVNAs5UTfGApkUasu*OetC6CzNcyoxrX&new=1
IPFS —— Go 实现的分布式文件系统 : https://mp.weixin.qq.com/s?src=3×tamp=1535268195&ver=1&signature=CpfJpQymWKMovehcjRVjTEhRqVpDyV9*k9OyZXNcFpU9Al2c8UxBcSWuKW8ojJWlK19T40acSVTDLsmcVBw8hdQB5*ohu-3T1ZLw7D0Vm6s2J1g7fiJXureOwEjpET*ORF*mjkeeLdQqxhGdqesGkg==
【焦点】分布式文件系统的备份 : https://mp.weixin.qq.com/s?src=11×tamp=1535268195&ver=1083&signature=f1w746*FM9IBHTdftKDO9ZJjf5EQj5FlHdJ5d2i32eQXnrKqGVygsELs6-pscy7L2csSZOyyo0viNk*z8hPVwOrpyzPypOCflQroodGUp-G9OfyBZ3WDiaOA3KZLQaM0&new=1
常见的分布式文件系统介绍 : http://blog.csdn.net/xyw591238/article/details/51441250
MongoDB GridFS 数据读取效率 benchmark
http://blog.nosqlfan.com/html/730.html
nginx + gridfs 实现图片的分布式存储 安装(一年后出问题了)
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/05/2038285.html
基于MongoDB GridFS的图片存储
http://liut.cc/blog/2010/12/about-imsto_my-first-open-source-project.html
nginx+mongodb-gridfs+squid
http://1008305.blog.51cto.com/998305/885340
分布式锁 : https://mp.weixin.qq.com/s/frT3AlgX1M4bcdIbfMXpNQ
分布式基础学习(1)--分布式文件系统 :https://mp.weixin.qq.com/s?src=3×tamp=1535252384&ver=1&signature=vx*N7EvfFqpmUOjwGF9wUIcxy31qP2i1s0ow3-ZGdLH8ashU2glg5Dt8yNC331Ab0XbKro9HyKPm5KDGTuYe91sjfnkDgORhgGMc7Eqy9BOh51cYMYWZMJEP293D3J3SmQ*mzMZtnbMWP-woPrHSDsvKQce4pDpbAF*UPJHd6CA=
常见分布式文件系统大盘点 :https://mp.weixin.qq.com/s?src=11×tamp=1535267655&ver=1083&signature=0WeQe5IIK7M40bOO4tFi*eX3lgMVGP4GiOa6bVM7YrrkskoLX2iFl3-k*r9c-V5BD2Z*gEIEHQRSjDp9*DhpWKTND7Jgfj*ou5BSm1vEwgdL3PuRgRtyHF7ZQAm8KINB&new=1
轻松搭建分布式文件系统 : https://blog.csdn.net/m0_37450089/article/details/80215231
分布式系统的高效运维要点 : https://blog.csdn.net/chdhust/article/details/78238599
分布式系统failover测试之拔盘插盘操作 : https://blog.csdn.net/chdhust/article/details/53131599
搭建分布式文件系统 : https://ericfu.me/build-distributed-file-system/

大数据 : https://ericfu.me/archives/
HDFS的诞生 : https://mp.weixin.qq.com/s/x73Z-bBXXibbPvmMPxzwwQ
分布式系统之数据分片 : http://www.cnblogs.com/xybaby/p/7076731.html
分布式事务及通用解决方案 : https://mp.weixin.qq.com/s/3juaRe2iqi3iUOWMEkANoQ
大数据之数据采集 : https://mp.weixin.qq.com/s/36UfbwxukYf1FI3LQdpZXw
Cache一致性协议之MESI : https://mp.weixin.qq.com/s/jm8Nd49YIdwYf0jzDlTOXg
百度开源架构-分布式锁dlock : https://mp.weixin.qq.com/s/IZkoh1BY6vLNqtkti7EyIw
Kafka 系列 :
CentOS7上如何安装Kafka?CentOS7上安装Kafka教程 : https://www.jb51.net/os/RedHat/541702.html
CentOS上使用Squid+Stunnel搭建代理服务器教程 : https://www.jb51.net/os/RedHat/415615.html
分离式or超融合,分布式存储建设时的两种部署模式 : https://www.jianshu.com/p/611b7c179df8
分布式应用:
一文详解分布式系统数据分片难题 : https://mp.weixin.qq.com/s/vwshiESDGqrvAtOQaBNKPg难题
分布式系统的架构思路 : http://blog.51cto.com/13904503/2164247
大型分布式网站架构:缓存在分布式系统中的应用 : https://blog.csdn.net/qq_39627461/article/details/81007454
大型分布式网站架构:缓存在分布式系统中的应用 : http://www.cnblogs.com/AIPAOJIAO/p/9326084.html
阿里分布式服务框架Dubbo的架构总结 : https://www.cnblogs.com/AIPAOJIAO/p/9294215.html
大型网站架构系列:分布式消息队列(一) : https://mp.weixin.qq.com/s/eRpvdD5Udvwdj4mrAfQFBg
大型网站架构系列:消息队列(二) : https://mp.weixin.qq.com/s/BSXP9DEEc7HNQD3kRozSXQ
大型网站架构系列:缓存在分布式系统中的应用(一) : https://mp.weixin.qq.com/s/xp_qZToZAbLnmfo8rq39Vg
大型网站架构系列:缓存在分布式系统中的应用(二) : https://mp.weixin.qq.com/s/CnyMkOMrzLLKDZ2FQRfJ9w
大型网站架构系列:缓存在分布式系统中的应用(三) :https://mp.weixin.qq.com/s/zDRITPG8Qbeg2mRnUfzxaQ
大型网站架构系列:电商网站架构案例(3) : https://mp.weixin.qq.com/s/qgNKu4wOKeTCfIJNgKT2Rw
大型分布式网站架构技术总结 : https://mp.weixin.qq.com/s/ozG0tss4JREx8txLnORQFw
负载均衡详解
大型网站架构系列:负载均衡详解(1) : https://mp.weixin.qq.com/s/xbtLnhT42clXsuiP-C9bDg
大型网站架构系列:负载均衡详解(2) : https://mp.weixin.qq.com/s/ufpGLqCWlE0LlqdlIRB3Eg
大型网站架构系列:负载均衡详解(3) : https://mp.weixin.qq.com/s/uaCykNu4diXpqOPCz4YZJg
大型网站架构系列:负载均衡详解(4) : https://mp.weixin.qq.com/s/vWW5H3sTaSkAieN299a4bw
Glusterfs
CentOS 6.5安装部署Glusterfs : http://blog.51cto.com/zlyang/1690055
换个角度看GlusterFS分布式文件系统 : http://blog.51cto.com/zlyang/1684400
glusterfs——volume管理 : http://blog.51cto.com/zlyang/1684311
分布式文件系统HDFS解读 : https://mp.weixin.qq.com/s/kXRLnOuRCWCEv9Bz-dJ9Ig
FastDFS 系统
CentOS7搭建FastDFS+Nginx : http://blog.51cto.com/ygqygq2/2091651
fastdfs添加新group注意事项 : http://blog.51cto.com/ygqygq2/2136589
VMware下CentOS6.8配置GFS文件系统 : http://blog.51cto.com/ygqygq2/1871300
分布式文件系统FastDFS详解 : https://www.cnblogs.com/ityouknow/p/8240976.html
那一定都是你的错!- 一次FastDFS并发问题的排查经历 : https://www.cnblogs.com/ityouknow/p/8123998.html
FastDFS 集群 安装 配置 : https://www.cnblogs.com/ityouknow/p/7769142.html
分布式文件系统FastDFS架构剖析 : https://www.ixdba.net/archives/2014/04/311.htm
大型网站架构系列:电商网站架构案例(1) : https://mp.weixin.qq.com/s/W8n3tkH6cAT4OyXbxqzw2g
大型网站架构系列:电商网站架构案例(2) : https://mp.weixin.qq.com/s/j5c75ePAIwPmRI9VlCzfhA
大型网站架构系列:电商网站架构案例(3) : https://mp.weixin.qq.com/s/qgNKu4wOKeTCfIJNgKT2Rw
分布式一致性系统的动态替换实现机制
1. Paxos成员组变更
http://oceanbase.org.cn/?p=160
Paxos & Raft 分布一致性算法 Slideshare : https://ericfu.me/paxos-raft-share/
2. 如何完美实现Paxos算法成员组变更
http://www.sohu.com/a/136589596_446710
Openshift Origin
Openshift Origin v1.3.x新增功能部署-Centos7 : http://www.pangxie.space/docker/1182
Openshift Origin版本升级(v1.2.x->v1.3.x)-Centos7 : http://www.pangxie.space/docker/1176
在openshift部署fabric8-Centos7 : http://www.pangxie.space/docker/1154
搭建分布式Openshift Origin-Centos7 : http://www.pangxie.space/docker/989
搭建单机版Openshift Origin-Centos7 ;http://www.pangxie.space/docker/964
分布式与大数据系统 (80篇) : https://blog.csdn.net/chdhust/article/category/2202603
分布式一致性 (43) : https://blog.csdn.net/chdhust/article/category/5650785
分布式存储系统 (22): https://blog.csdn.net/chdhust/article/category/1384021
分布式消息系统 (23) : https://blog.csdn.net/chdhust/article/category/2472965
分布式日志系统 (7) : https://blog.csdn.net/chdhust/article/category/2302509
分布式服务框架 (2) : https://blog.csdn.net/chdhust/article/category/5642291
分布式集群管理 (2) : https://blog.csdn.net/chdhust/article/category/5643953
分布式数据库 (3) : https://blog.csdn.net/chdhust/article/category/2559193
安全技术研究 : https://blog.csdn.net/chdhust/article/category/2289747
大数据:
大数据学习路线 : https://mp.weixin.qq.com/s/P0JFoDo5kTp81_eZOvfnEg
大数据在电竞平台的应用 : https://mp.weixin.qq.com/s/P0JFoDo5kTp81_eZOvfnEg
W3Cschool
Apache Pig教程 : https://www.w3cschool.cn/apache_pig/
Apache Kafka 教程 : https://www.w3cschool.cn/apache_kafka/
Apache Storm教程 : https://www.w3cschool.cn/apache_storm/
Hadoop教程 : https://www.w3cschool.cn/hadoop/
impala教程 : https://www.w3cschool.cn/impala/
Zookeeper教程 : https://www.w3cschool.cn/zookeeper/
RabbitMQ
如何用好消息队列RabbitMQ? : https://www.jianshu.com/p/b39e5edf3e5c
缓存
Memcached (第一篇) : https://www.cnblogs.com/kissdodog/p/3549488.html
缓存概述 : https://www.cnblogs.com/kissdodog/archive/2013/05/23/3094830.html
System.Web.Caching.Cache类 缓存 各种缓存依赖 : https://www.cnblogs.com/kissdodog/archive/2013/05/07/3064895.html
Hibernate
Hibernate 高级教程 : http://www.voidcn.com/course/project/ooabed
Hibernate 教程 (程序园博客): http://www.voidcn.com/course/project/rmpfby
【转载整理】Hibernater的锁机制 : https://www.cnblogs.com/yingsong/p/7646313.html
(Clob的写入和读取-java)更新数据库报错:SQL Error: 1461, SQLState: 72000 ORA-01461: 仅能绑定要插入 LONG 列的 LONG 值 : https://www.cnblogs.com/yingsong/p/5685790.html
Hibernate 操作 oracle数据库,报错总结 : https://www.cnblogs.com/yingsong/p/5283863.html
Hibernate关联关系(二) Cascade级联 : https://www.cnblogs.com/yingsong/p/5197828.html
【转载】Hibernate 关联关系 : https://www.cnblogs.com/yingsong/p/5197826.html
Hibernate JPA实体继承的映射(一) 概述 : https://www.cnblogs.com/yingsong/p/5179975.html
Hibernate JPA实体继承的映射(二) @MappedSuperclass : https://www.cnblogs.com/yingsong/p/5179961.html
Mycat
Mycat学习实战-Mycat读写分离 : http://blog.51cto.com/ygqygq2/1981542
Mycat学习实战-Mycat分片 : http://blog.51cto.com/ygqygq2/1981540
Mycat学习实战-Mycat全局主键 : http://blog.51cto.com/ygqygq2/1976279
Mycat学习实战-Mycat的zookeeper集群模式 : http://blog.51cto.com/ygqygq2/1974592
Mycat学习实战-Mycat基本功能 : http://blog.51cto.com/ygqygq2/1974299
Mycat学习实战-Mycat初识 : http://blog.51cto.com/ygqygq2/1973653
MyBatis 文档 : http://www.voidcn.com/course/project/ejatyd
Apache
原 Kafka安全认证SASL下附带工具的配置使用 : https://blog.csdn.net/u012842205/article/details/73648170
原 Apache Kafka0.10.0.0集群部署 : https://blog.csdn.net/u012842205/article/details/73250288
原 集群Kafka配置SASL用户名密码认证 : https://blog.csdn.net/u012842205/article/details/73188684
原 单机节点Kafka配置SASL用户名密码认证 : https://blog.csdn.net/u012842205/article/details/73188534
原 Apache Cassandra3.10集群安装部署 : https://blog.csdn.net/u012842205/article/details/72781463
原 Apache Hive2.1.1安装部署 : https://blog.csdn.net/u012842205/article/details/71713842
HBase
原 HBase概述 : https://blog.csdn.net/u012842205/article/details/52267263
原 HBase使用总结 : https://blog.csdn.net/u012842205/article/details/52267291
原 Hbase增删改查、关联查询、关系型数据库转化 : https://blog.csdn.net/ioy84737634/article/details/52554605
hbase分布式集群搭建 : https://www.cnblogs.com/ityouknow/p/7343996.html
HBase shell 命令介绍 : https://www.cnblogs.com/ityouknow/p/7344001.html
HBase高可用原理与实践 : https://mp.weixin.qq.com/s/BlG7qYL12Hbjl4nYSr8_nA
原 Sqoop1.4.6安装与使用(一) : https://blog.csdn.net/u012842205/article/details/53377103
原 Sqoop1.4.6安装与使用(二) : https://blog.csdn.net/u012842205/article/details/53378703
GPFS分布式文件系统在云计算环境中的实践 : http://www.talkwithtrend.com/Article/218939
Mfs分布式文件系统总结 : http://blog.51cto.com/11638832/1969271
MFS分布式文件系统 : http://blog.51cto.com/11638832/1873980
分布式文件系统之MooseFS----管理优化 荐 : http://blog.51cto.com/nolinux/1602616
分布式文件系统之MooseFS----部署 : http://blog.51cto.com/nolinux/1601385
分布式文件系统之MooseFS----介绍 荐 : http://blog.51cto.com/nolinux/1600890
分布式文件系统--MogileFS 荐 : http://blog.51cto.com/guoting/1561354
分布式存储系统MogileFS(一)之基本概念 : http://blog.51cto.com/cuchadanfan/1699333
分布式存储系统MogileFS(二)之简单配置 : http://blog.51cto.com/cuchadanfan/1699335
GalaCloud分布式加密存储网络 : https://mp.weixin.qq.com/s/eXQYQh3Zi3bclJwdoTxYSQ
Kafka
Kafka简明教程 : https://www.jianshu.com/p/3d178a233bfa
kafka丢数据问题分析 : https://www.jianshu.com/p/954d3c75500d
kafka 无消息丢失配置 转 : https://www.jianshu.com/p/0898406ccbae
KAFKA 删除 topic : https://www.jianshu.com/p/f55136b86adb
spark向kafka写入数据(转) : https://www.jianshu.com/p/cea421e72dec
Flume+Kafka收集Docker容器内分布式日志应用实践 : https://mp.weixin.qq.com/s/DWD6N6q4ECCuB-wrCjk0OA
kafka权威指南 第二章第6节 Kafka集群配置与调优 : https://mp.weixin.qq.com/s/MbFMnU_r9lFvLnA2bJuSsQ
kafka 数据可靠性深度解读 :https://mp.weixin.qq.com/s/in4qytXdE7GwHrE2JNYbDw
Spark
Spark入门基础教程 : https://www.jianshu.com/p/05d64ec96781
https://www.cnblogs.com/atomicbomb/tag/Spark/
Spark sql读取数据库和ES数据进行处理代码 : https://www.cnblogs.com/atomicbomb/p/6678531.html
spark streaming的理解和应用 : https://www.cnblogs.com/atomicbomb/p/6834447.html
Spark on Yarn with Hive实战案例与常见问题解决 荐 : http://blog.51cto.com/xpleaf/2296151
Spark on Yarn作业运行架构原理解析 : http://blog.51cto.com/xpleaf/2294303
Spark作业运行架构原理解析 : http://blog.51cto.com/xpleaf/2293921
日志分析实战之清洗日志小实例1:使用spark&Scala分析Apache日志 : https://mp.weixin.qq.com/s/8Hnhk9HbB4T5byvWLQSOmg
Spark笔记整理(四):Spark RDD算子实战 : http://blog.51cto.com/xpleaf/2108481
Spark笔记整理(五):Spark RDD持久化、广播变量和累加器 : http://blog.51cto.com/xpleaf/2108614
Spark笔记整理(六):Spark高级排序与TopN问题揭密 : http://blog.51cto.com/xpleaf/2108763
Spark笔记整理(十三):RDD持久化性能测试(图文并茂) : http://blog.51cto.com/xpleaf/2288316
分布式唯一ID的几种生成方案 : https://mp.weixin.qq.com/s/Klmyffj5oVejHjg81vSe5w
常用的分布式事务解决方案 : https://mp.weixin.qq.com/s/_Tz9z1tGxcrICsXqH8gDhQ
分布式数据库在商业银行设计与实践相关的20个问题 : https://mp.weixin.qq.com/s/ByD1PSdxayVDFA_c1LZ4Pw
分布式数据库TiDB在商业银行的设计与实践
http://www.talkwithtrend.com/Document/detail/tid/419235
TiDB集群安装
http://www.talkwithtrend.com/Document/detail/tid/419205
postgresql分布式数据库架构
http://www.talkwithtrend.com/Document/detail/tid/418759
Greenplum数据库最佳实践
http://www.talkwithtrend.com/Document/detail/tid/418755
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









