







XML解析方式有三种:DOM、SAX、StAX
xml文档每个成分都是一个节点,每个xml标签对应一个元素节点:整个文档是一个文档节点,每个xml标签对应一个元素节点,包含早xml标签中是文本节点,注释是注释节点。
DOM解析:
DOM Document Object Model ----- 文档对象模型 基于树形结构的xml解析方式。 会将整个XML载入内存,以树形结构方式存储,易于编程 当xml文档是聚焦大,会造成较大的资源消耗。 即将整个xml 加载内存中,形成文档对象,所有对xml操作都对内存中文档对象进行
SAX解析:
基于事件模型的sax解析方式 当xml 文档非常大,不可能将xml所有数据加载到内存 即一边解析 ,一边处理,一边释放内存资源 ---- 不允许在内存中保留大规模xml 数据 使用推模式如下图所示
即由服务器为主导,向客户端主动发送数据( 推送 ) 推模式(事件由解析器产生并通过回调函数发送给应用程序)
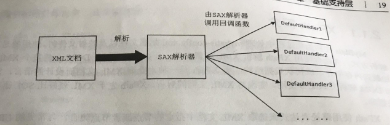
缺点:不存储xml文档结构,开发人员自己维护业务逻辑涉及的多层节点之间关系。
流式处理所以只能向后单向进行,无法像dom那样自由导航到之前处理过得节点上重新处理,也不支持xPath
stax
STAX 是一种 拉模式 XML 解析方式(SAX性能不如STAX,STAX技术较新)
采取如下图所示的模式
即拉模式由客户端为主导,主动向服务器申请数据( 轮询 )(应用程序通过调用解析器推进解析进程)
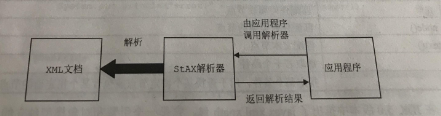
简化了处理xml文档代码,可同时处理多个xml文档,可决定何时停止解析。















 5826
5826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









