







1. Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。ZooKeeper是Hadoop的一个子项目。在分布式应用中,由于工程师不能很好的使用锁机制,以及基于消息的协调机制不适合在某些应用中使用,因此需要一种可靠的、可扩展的、分布式的、可配置的协调机制来统一系统的状态。ZooKeeper目的于此。
ZooKeeper 核心机制包括:恢复模式(选主流程)和广播模式(同步流程)。当服务刚启动、leader 崩溃、follower 不足半数时,系统就进入选主流程,此时不对外提供服务;当 leader被选举出来后,系统就进入同步流程,server 之间完成状态同步,此后对外提供服务。
选 举 策 略 主 要 基 于 paxos 算 法 , 一 种 称 为 LeaderElection 算 法(选举线程向所有server发起一次询问,按照服务器选取规则去比较,选出下一次要询问的server,当被选取的server有一般server支持,则成为leader服务器,不然就一直选举,直到选出了leader) , 一 种 称 为FastLeaderElection 算法(一个server声明自己要做leader,其它server将配合工作,解决zxid和epoch冲突,并向该server发送接收提议的消息),系统默认使用 FastLeaderElection 算法完成。
2. Paxos算法
基本定义
算法中的参与者主要分为三个角色,同时每个参与者又可兼领多个角色:
- proposer 提出提案,提案信息包括提案编号和提议的value;
- acceptor 收到提案后可以接受(accept)提案;
- learner 只能"学习"被批准的提案;
算法保证一致性的基本语义:
- 决议(value)只有在被proposers提出后才能被批准(未经批准的决议称为"提案(proposal)");
- 在一次Paxos算法的执行实例中,只批准(chosen)一个value;
- learners只能获得被批准(chosen)的value;
由上面的三个语义可演化为四个约束:
- P1:一个acceptor必须接受(accept)第一次收到的提案;
- P2a:一旦一个具有value v的提案被批准(chosen),那么之后任何acceptor 再次接受(accept)的提案必须具有value v;
- P2b:一旦一个具有value v的提案被批准(chosen),那么以后任何 proposer 提出的提案必须具有value v;
- P2c:如果一个编号为n的提案具有value v,那么存在一个多数派,要么他们中所有人都没有接受(accept)编号小于n的任何提案,要么他们已经接受(accpet)的所有编号小于n的提案中编号最大的那个提案具有value v;
每个Server在工作过程中有四种状态:
- LOOKING:竞选状态,当前Server不知道leader是谁,正在搜寻。
- LEADING:领导者状态,表明当前服务器角色是leader。
- FOLLOWING:随从状态,表明当前服务器角色是follower,同步leader状态,参与投票。
- OBSERVING,观察状态,表明当前服务器角色是observer,同步leader状态,不参与投票。
基本算法(basic paxos)
算法(决议的提出与批准)主要分为两个阶段:
- prepare阶段:
- 当Porposer希望提出方案V1,首先发出prepare请求至大多数Acceptor。prepare请求内容为序列号<SN1>;
- 当Acceptor接收到prepare请求<SN1>时,检查自身上次回复过的prepare请求<SN2>
- 如果SN2>SN1,则忽略此请求,直接结束本次批准过程;
- 否则检查上次批准的accept请求<SNx,Vx>,并且回复<SNx,Vx>;如果之前没有进行过批准,则简单回复<OK>;
- accept批准阶段:
- 经过一段时间,收到一些Acceptor回复,回复可分为以下几种:
- 回复数量满足多数派,并且所有的回复都是<OK>,则Porposer发出accept请求,请求内容为议案<SN1,V1>;
- 回复数量满足多数派,但有的回复为:<SN2,V2>,<SN3,V3>……则Porposer找到所有回复中超过半数的那个,假设为<SNx,Vx>,则发出accept请求,请求内容为议案<SN1,Vx>;
- 回复数量不满足多数派,Proposer尝试增加序列号为SN1+,转1继续执行;
- 经过一段时间,收到一些Acceptor回复,回复可分为以下几种:
- 回复数量满足多数派,则确认V1被接受;
- 回复数量不满足多数派,V1未被接受,Proposer增加序列号为SN1+,转1继续执行;
- 在不违背自己向其他proposer的承诺的前提下,acceptor收到accept 请求后即接受并回复这个请求。
- 经过一段时间,收到一些Acceptor回复,回复可分为以下几种:
要使Leader获得多数Server的支持,则Server总数必须是奇数2N+1,且存活的Server的数目不得少于N+1。每个Server启动后都会重复以上流程。
算法优化(fast paxos)
Paxos算法在出现竞争的情况下,其收敛速度很慢,甚至可能出现活锁的情况,例如当有三个及三个以上的proposer在发送prepare请求后,很难有一个proposer收到半数以上的回复而不断地执行第一阶段的协议。因此,为了避免竞争,加快收敛的速度,在算法中引入了一个Leader这个角色,在正常情况下同时应该最多只能有一个参与者扮演Leader角色,而其它的参与者则扮演Acceptor的角色,同时所有的人又都扮演Learner的角色。
在这种优化算法中,只有Leader可以提出议案,从而避免了竞争使得算法能够快速地收敛而趋于一致,此时的paxos算法在本质上就退变为两阶段提交协议。但在异常情况下,系统可能会出现多Leader的情况,但这并不会破坏算法对一致性的保证,此时多个Leader都可以提出自己的提案,优化的算法就退化成了原始的paxos算法。
一个Leader的工作流程主要有分为三个阶段:
- 学习阶段 向其它的参与者学习自己不知道的数据(决议);
- 同步阶段 让绝大多数参与者保持数据(决议)的一致性;
- 服务阶段 为客户端服务,提议案;
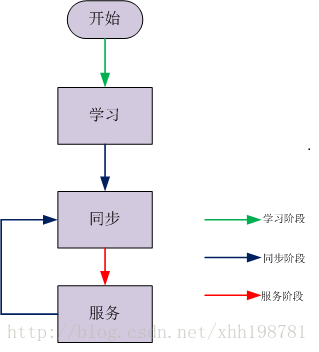
学习阶段
当一个参与者成为了Leader之后,它应该需要知道绝大多数的paxos实例,因此就会马上启动一个主动学习的过程。假设当前的新Leader早就知道了1-134、138和139的paxos实例,那么它会执行135-137和大于139的paxos实例的第一阶段。如果只检测到135和140的paxos实例有确定的值,那它最后就会知道1-135以及138-140的paxos实例。
同步阶段
此时的Leader已经知道了1-135、138-140的paxos实例,那么它就会重新执行1-135的paxos实例,以保证绝大多数参与者在1-135的paxos实例上是保持一致的。至于139-140的paxos实例,它并不马上执行138-140的paxos实例,而是等到在服务阶段填充了136、137的paxos实例之后再执行。这里之所以要填充间隔,是为了避免以后的Leader总是要学习这些间隔中的paxos实例,而这些paxos实例又没有对应的确定值。
服务阶段
Leader将用户的请求转化为对应的paxos实例,当然,它可以并发的执行多个paxos实例,当这个Leader出现异常之后,就很有可能造成paxos实例出现间断。
问题
(1).Leader的选举原则
(2).Acceptor如何感知当前Leader的失败,客户如何知道当前的Leader
(3).当出现多Leader之后,如何kill掉多余的Leader
(4).如何动态的扩展Acceptor
3. Zookeeper选主实现
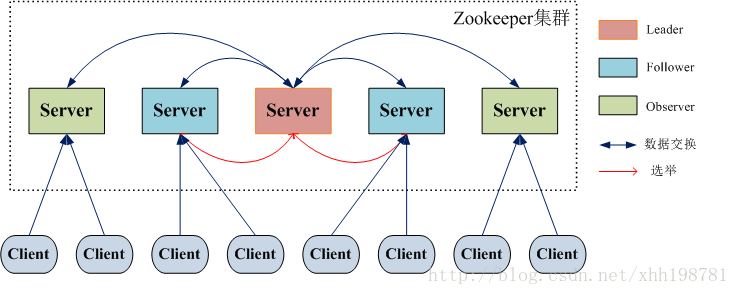
整体架构
在Zookeeper集群中,主要分为三者角色,而每一个节点同时只能扮演一种角色,这三种角色分别是:
- Leader 接受所有Follower的提案请求并统一协调发起提案的投票,负责与所有的Follower进行内部的数据交换(同步);
- Follower 直接为客户端服务并参与提案的投票,同时与Leader进行数据交换(同步);
- Observer 直接为客户端服务但并不参与提案的投票,同时也与Leader进行数据交换(同步);
QuorumPeer的基本设计
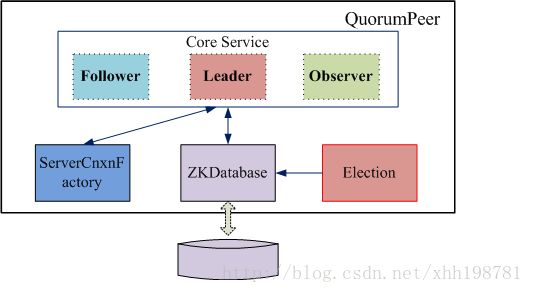
Zookeeper对于每个节点QuorumPeer的设计相当的灵活,QuorumPeer主要包括四个组件:客户端请求接收器(ServerCnxnFactory)、数据引擎(ZKDatabase)、选举器(Election)、核心功能组件(Leader/Follower/Observer)。其中:
- ServerCnxnFactory负责维护与客户端的连接(接收客户端的请求并发送相应的响应);
- ZKDatabase负责存储/加载/查找数据(基于目录树结构的KV+操作日志+客户端Session);
- Election负责选举集群的一个Leader节点;
- Leader/Follower/Observer一个QuorumPeer节点应该完成的核心职责;
QuorumPeer工作流程
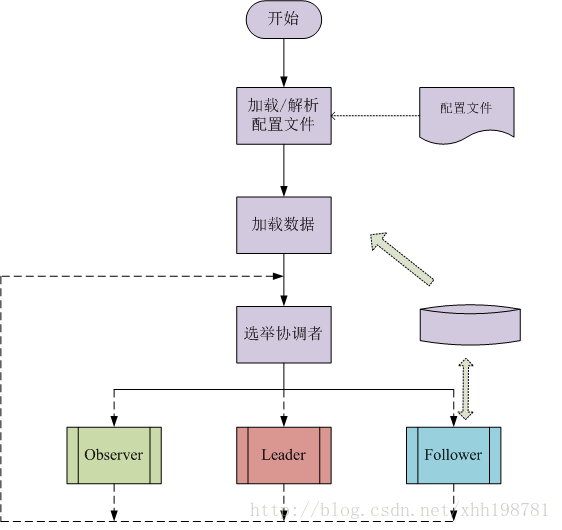
Leader职责

Follower确认: 等待所有的Follower连接注册,若在规定的时间内收到合法的Follower注册数量,则确认成功;否则,确认失败。
Follower职责
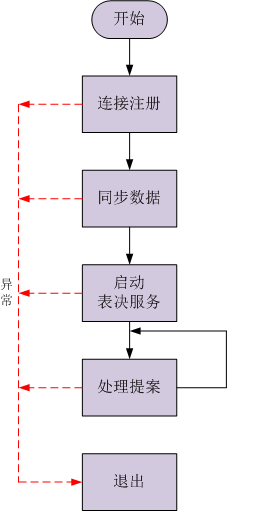
选举算法
LeaderElection选举算法
选举线程由当前Server发起选举的线程担任,他主要的功能对投票结果进行统计,并选出推荐的Server。选举线程首先向所有Server发起一次询问(包括自己),被询问方,根据自己当前的状态作相应的回复,选举线程收到回复后,验证是否是自己发起的询问(验证zxid 是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader 相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中,当向所有Server都询问完以后,对统计结果进行筛选并进行统计,计算出当次询问后获胜的是哪一个Server,并将当前zxid最大的Server 设置为当前Server要推荐的Server(有可能是自己,也有可以是其它的Server,根据投票结果而定,但是每一个Server在第一次投票时都会投自己),如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server。根据获胜的Server相关信息设置自己的状态。每一个Server都重复以上流程直到选举出Leader。
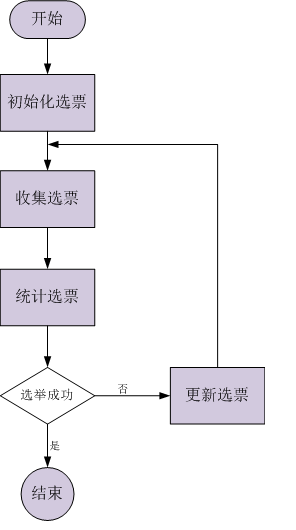
- 初始化选票(第一张选票): 每个quorum节点一开始都投给自己;
- 收集选票: 使用UDP协议尽量收集所有quorum节点当前的选票(单线程/同步方式),超时设置200ms;
- 统计选票: 1).每个quorum节点的票数; 2).为自己产生一张新选票(zxid、myid均最大);
- 选举成功: 某一个quorum节点的票数超过半数;
- 更新选票: 在本轮选举失败的情况下,当前quorum节点会从收集的选票中选取合适的选票(zxid、myid均最大)作为自己下一轮选举的投票;
异常问题的处理
- 选举过程中,Server的加入
- 当一个Server启动时它都会发起一次选举,此时由选举线程发起相关流程,那么每个 Server都会获得当前zxid最大的那个Server是谁,如果当次最大的Server没有获得n/2+1 个票数,那么下一次投票时,它将向zxid最大的Server投票,重复以上流程,最后一定能选举出一个Leader。
- 选举过程中,Server的退出
- 只要保证n/2+1个Server存活就没有任何问题,如果少于n/2+1个Server 存活就没办法选出Leader。
- 选举过程中,Leader死亡
- 当选举出Leader以后,此时每个Server应该是什么状态(FOLLOWING)都已经确定,此时由于Leader已经死亡我们就不管它,其它的Follower按正常的流程继续下去,当完成这个流程以后,所有的Follower都会向Leader发送Ping消息,如果无法ping通,就改变自己的状为(FOLLOWING ==> LOOKING),发起新的一轮选举。
- 选举完成以后,Leader死亡
- 处理过程同上。
- 双主问题
- Leader的选举是保证只产生一个公认的Leader的,而且Follower重新选举与旧Leader恢复并退出基本上是同时发生的,当Follower无法ping同Leader是就认为Leader已经出问题开始重新选举,Leader收到Follower的ping没有达到半数以上则要退出Leader重新选举。
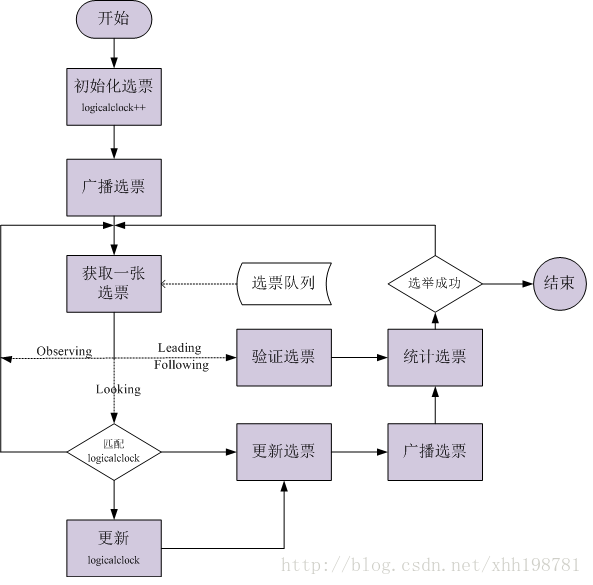
FastLeaderElection选举算法
FastLeaderElection是标准的fast paxos的实现,它首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决 epoch 和 zxid 的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息。
FastLeaderElection算法通过异步的通信方式来收集其它节点的选票,同时在分析选票时又根据投票者的当前状态来作不同的处理,以加快Leader的选举进程。
每个Server都一个接收线程池和一个发送线程池, 在没有发起选举时,这两个线程池处于阻塞状态,直到有消息到来时才解除阻塞并处理消息,同时每个Serve r都有一个选举线程(可以发起选举的线程担任)。
- 主动发起选举端(选举线程)的处理
- 首先自己的 logicalclock加1,然后生成notification消息,并将消息放入发送队列中, 系统中配置有几个Server就生成几条消息,保证每个Server都能收到此消息,如果当前Server 的状态是LOOKING就一直循环检查接收队列是否有消息,如果有消息,根据消息中对方的状态进行相应的处理。
- 主动发送消息端(发送线程池)的处理
- 将要发送的消息由Notification消息转换成ToSend消息,然后发送对方,并等待对方的回复。
- 被动接收消息端(接收线程池)的处理
- 将收到的消息转换成Notification消息放入接收队列中,如果对方Server的epoch小于logicalclock则向其发送一个消息(让其更新epoch);如果对方Server处于Looking状态,自己则处于Following或Leading状态,则也发送一个消息(当前Leader已产生,让其尽快收敛)。
Zookeeper中的请求处理流程
Follower节点处理用户的读写请求
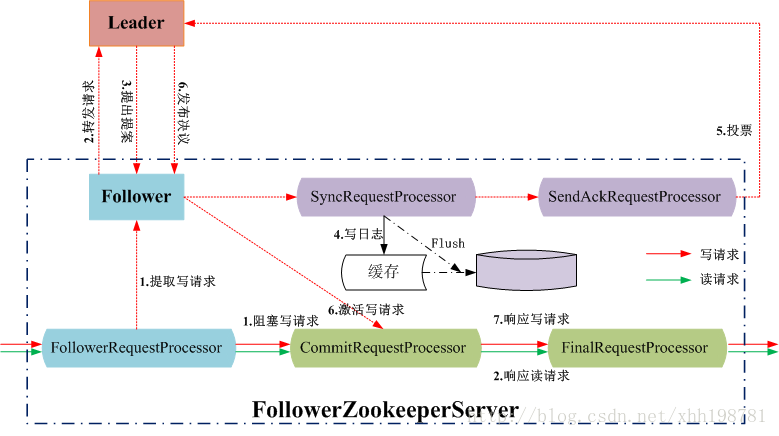
Leader节点处理写请求
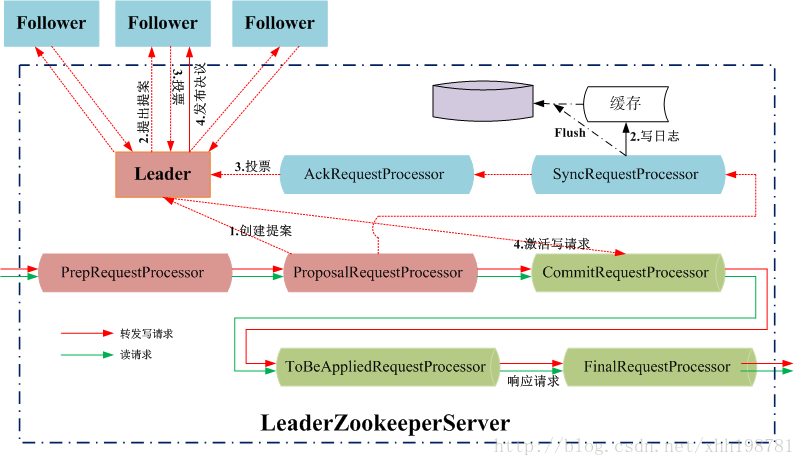
Follower/Leader上的读操作时并行的,读写操作是串行的,当CommitRequestProcessor处理一个写请求时,会阻塞之后所有的读写请求。
参考:ZooKeeper的选主机制 ZooKeeper 选主流程















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









