







本文内容:
LinkedHashMap概述
LinkedHashMap源码分析
LinkedHashMap概述
LinkedHashMap类似 于HashMap,区别在于采用迭代器迭代每个元素时,其顺序是按照插入次序或者是LRU次序。
其继承 关系如下:

LinkedHashMap直接继承了HashMap,实现了Map接口。
LinkedHashMap用Hash存储所有元素,但迭代时却又可以按顺序遍历,这是如何做到的呢?
LinkedHashMap源码分析
看一下LinkedHashMap的属性
/**
* The head of the doubly linked list.
*/
private transient Entry<K,V> header;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
private final boolean accessOrder;其中header列表记录着元素的插入或者LRU次序,所以很明显,LinkedHashMap能够迭代器顺序访问一定和这个header有关。其实确实是的,header是一个循环双向链表!accessOrder则用来标记是按插入顺序还是访问顺序。
构造函数:
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}调用了HashMap的构造函数,在HashMap的构造函数中调用了init()方法
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}init是初始化header链表。header链表是Entry类型,LinkedHashMap的一个内部静态类,继承了HashMap.Entry。
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//省略
}看LinkedHashMap,大部分都是重写(override)父类的一些方法。
/**
* This override differs from addEntry in that it doesn't resize the
* table or remove the eldest entry.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}createEntry不仅把元素添加进了table数组,还通过addBefore将其添加进header链表。
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}在header前面插入该元素。最后形成这样的链表:
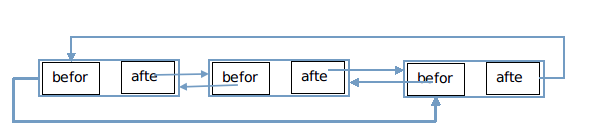
这个链表在迭代器中用。
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}这里,会调用removeEntryForKey去除最老的元素,但removeEldestEntry方法返回的是false,这样不是永远不会执行removeEntryForKey吗?是的。
这样做是为了让LinkedHashMap的行为是符合正常的Map,不会因为增加元素而把旧的元素给去除。
那直接忽略不就行了吗?
看注释,如果我们想实现一个cache,只需要重载LinkedHashMap,然后重写removeEldestEntry就可以完成简单的,限制大小的LRU缓存了。比如实现一个100元素的cache,可以这样写:
private static final int MAX_ENTRIES = 100;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}再看一下transfer
@Override
void transfer(HashMap.Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e = header.after; e != header; e = e.after) {
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}这个方法被父类的resize调用,重写它是为了实现性能优化!为什么呢?因为这里直接用了header链表,而HashMap是遍历所有的table槽。
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}遍历header链表,查看是否包含该value.
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}和HashMap方法相比,多了recordAccess方法的调用。recordAccess方法在Entry中实现。
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
private void remove() {
before.after = after;
after.before = before;
}由代码可知,如果accessOrder被设置成true,就可以有LRU的功能。
最后还剩下iterator方法没看,我们说LinkedHashMap是支持按插入顺序或者LRU顺序的,说的是遍历的时候。它的实现方法就是遍历header链表。
把LinkedHashMap的迭代器全部贴出来,和HashMap差不多:
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
}
// These Overrides alter the behavior of superclass view iterator() methods
Iterator<K> newKeyIterator() { return new KeyIterator(); }
Iterator<V> newValueIterator() { return new ValueIterator(); }
Iterator<Map.Entry<K,V>> newEntryIterator() { return new EntryIterator(); }它们都继承了LinkedHashIterator,LinkedHashIterator是LinkedHashMap的内部抽象类,继承Iterator
private abstract class LinkedHashIterator<T> implements Iterator<T>LinkedHashIterator的属性如下:
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
int expectedModCount = modCount;hasNext方法:
public boolean hasNext() {
return nextEntry != header;
}remove方法
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}nextEntry方法
Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}iterator的实现思路和HashMap很相似,代码找着header链表的结构就很容易理解了。
总结
LinkedHashMap使用hash来存放元素,同时也将该元素存放在header链表中,这样,就可以hash方式get/put元素,List方式迭代元素。














 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









