







博文原地址:https://my.oschina.net/zlb1992/blog/918243
项目需要基于Neo4j开发,由于数据量较大(数千万节点),因此对当前数据插入的方法进行了分析和对比。
常见数据插入方式概览
| Neo4j Version | Language Driver |
|---|---|
| Community 3.0.2 | Python neo4j-driver 1.0.0 |
目前主要有以下几种数据插入方式:
- Cypher CREATE 语句,为每一条数据写一个CREATE
- Cypher LOAD CSV 语句,将数据转成CSV格式,通过LOAD CSV读取数据。
- 官方提供的Java API —— Batch Inserter
- 大牛编写的 Batch Import 工具
- 官方提供的 neo4j-import 工具
这些工具有什么不同呢?速度如何?适用的场景分别是什么?我这里根据我个人理解,粗略地给出了一个结果:
| CREATE语句 | LOAD CSV语句 | Batch Inserter | Batch Import | Neo4j-import | |
|---|---|---|---|---|---|
| 适用场景 | 1 ~ 1w nodes | 1w ~ 10 w nodes | 千万以上 nodes | 千万以上 nodes | 千万以上 nodes |
| 速度 | 很慢 (1000 nodes/s) | 一般 (5000 nodes/s) | 非常快 (数万 nodes/s) | 非常快 (数万 nodes/s) | 非常快 (数万 nodes/s) |
| 优点 | 使用方便,可实时插入。 | 使用方便,可以加载本地/远程CSV;可实时插入。 | 速度相比于前两个,有数量级的提升 | 基于Batch Inserter,可以直接运行编译好的jar包;可以在已存在的数据库中导入数据 | 官方出品,比Batch Import占用更少的资源 |
| 缺点 | 速度慢 | 需要将数据转换成CSV | 需要转成CSV;只能在JAVA中使用;且插入时必须停止neo4j | 需要转成CSV;必须停止neo4j | 需要转成CSV;必须停止neo4j;只能生成新的数据库,而不能在已存在的数据库中插入数据。 |
速度测试
下面是我自己做的一些性能测试:
1. CREATE 语句
这里每1000条进行一次Transaction提交
CREATE (:label {property1:value, property2:value, property3:value} )
| 11.5w nodes | 18.5w nodes |
|---|---|
| 100 s | 160 s |
2. LOAD CSV 语句
using periodic commit 1000load csv from "file:///fscapture_screencapture_syscall.csv" as linecreate (:label {a:line[1], b:line[2], c:line[3], d:line[4], e:line[5], f:line[6], g:line[7], h:line[8], i:line[9], j:line[10]})
这里使用了语句USING PERIODIC COMMIT 1000,使得每1000行作为一次Transaction提交。
| 11.5w nodes | 18.5w nodes |
|---|---|
| 21 s | 39 s |
3. Batch Inserter、Batch Import、Neo4j-import
我只测试了Neo4j-import,没有测试Batch Inserter和Batch Import,但是我估计他们的内部实现差不多,速度也处于一个数量级别上,因此这里就一概而论了。
neo4j-import需要在Neo4j所在服务器执行,因此服务器的资源影响数据导入的性能,我这里为JVM分配了16G的heap资源,确保性能达到最好。
sudo ./bin/neo4j-import --into graph.db --nodes:label path_to_csv.csv
| 11.5w nodes | 18.5w nodes | 150w nodes + 1431w edges | 3113w nodes + 7793w edges |
|---|---|---|---|
| 3.4 s | 3.8 s | 26.5 s | 3 m 48 s |
小结
- 如果项目刚开始,想要将大量数据导入数据库,Neo4j-import是最好的选择。
- 如果数据库已经投入使用,并且可以容忍Neo4j关闭一段时间,那么Batch Import是最好的选择,当然如果你想自己实现,那么你应该选择Batch Inserter
- 如果数据库已经投入使用,且不能容忍Neo4j的临时关闭,那么LOAD CSV是最好的选择。
- 最后,如果只是想插入少量的数据,且不怎么在乎实时性,那么请直接看Cypher语言。
Demo
1. Cypher Create语句
其主要过程就是将Cypher语句写在某个文件中,在用Java或者Python代码操作,并用jdbc连接Neo4j服务器并且执行,本方法操作太慢,仅适用于某些插入量很小的场景或者查询场景,代码不具体列出,如有需要可在下面留言。
2. Cypher LOAD CSV
在Neo4j服务器的执行命令行中直接执行如下cypher语句即可:
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/categories.csv" AS row
CREATE (n:Category)
SET n = rowcategories.csv内容为

该语句是将url中,的文件以节点的形式导入neo4j中,也可用形如f:/Book1.csv的本地路径。每一行记录均生成一个节点,每个字段对应一个属性
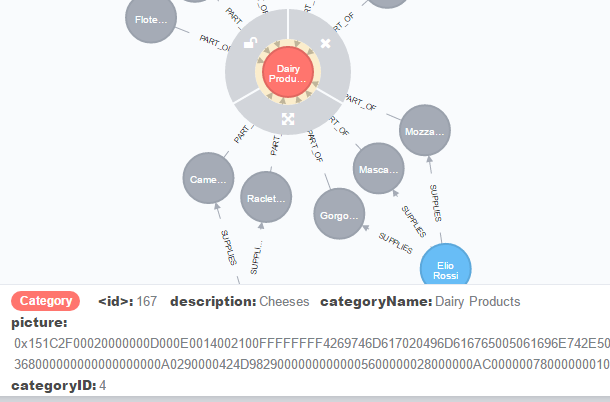
再导入过程中还可以根据实际应用场景处理数据如:
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/products.csv" AS row
CREATE (n:Product)
SET n = row,
n.unitPrice = toFloat(row.unitPrice),
n.unitsInStock = toInteger(row.unitsInStock), n.unitsOnOrder = toInteger(row.unitsOnOrder),
n.reorderLevel = toInteger(row.reorderLevel), n.discontinued = (row.discontinued <> "0")在插入节点后可建立索引,提高后期插入关系的速度,如建立Category类型顶点上categoryID属性的索引
CREATE INDEX ON :Category(categoryID)插入关系 如根据外键关联Prodect和Categroy的关系
MATCH (p:Product),(c:Category)
WHERE p.categoryID = c.categoryID
CREATE (p)-[:PART_OF]->(c)系列过程可查看Neo4j中Example中的northwind-graph。该方法可以完全替代掉直接执行Cypher语句的方法,在小数据量的时候可以用。
3. Neo4j-import
在neo4j-operations-manual中有一个例子:
记录为电影,明星 以及其中存在的一个扮演角色关系。内容为
movies.csv
movieId:ID,title,year:int,:LABEL
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
tt0242653,"The Matrix Revolutions",2003,Movie;Sequel
actors.csv
personId:ID,name,:LABEL
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actor
roles.csv
:START_ID,role,:END_ID,:TYPE
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN
将三个文件传至Neo4j服务器中,
执行%Neo4jHome%/bin/neo4j-import脚本,具体执行命令为:
cd至%Neo4jHome%执行
./bin/neo4j-import --into data/databases/graph.db --nodes /usr/local/lib/neo4j/importFile/expert.csv --nodes /usr/local/lib/neo4j/importFile/paper.csv --relationships /usr/local/lib/neo4j/importFile/expertPaper.csv其中data/databases/graph.db必须不存在,nodes和relationships后面分别根生节点和关系的文件
等待结果即可。
遇到to many entries失败导致添加失败可以再加上 --bad-tolerance=10000修改 默认容错为1000
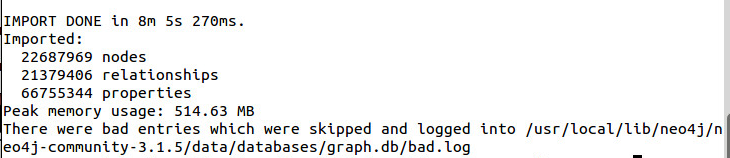
这样表示插入成功,开启neo4j即可使用。
neo4j_home$ ./bin/neo4j start
其它的Tips
- 在LOAD CSV前面加上USING PERIODIC COMMIT 1000,1000表示每1000行的数据进行一次Transaction提交,提升性能。
- 建立index可以使得查询性能得到巨大提升。如果不建立index,则需要对每个node的每一个属性进行遍历,所以比较慢。 并且index建立之后,新加入的数据都会自动编入到index中。 注意index是建立在label上的,不是在node上,所以一个node有多个label,需要对每一个label都建立index。
- 最后所有的困难都应该能在neo4j操作手册上得到官方 解答,点击下载阅读英文版。















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









