







本文介绍使用java.util.*包中的HashMap 和 LinkedList 以及 ArrayList类快速实现一个有向图,并实现有向图的深度优先遍历算法。
如何构造图?
本文根据字符串数组来构造一个图。图的顶点标识用字符串来表示,如果某个字符串A的第一个字符与另一个字符串B的最后一个字符相同,则它们之间构造一条有向边。比如,字符串数组{”hap”,”peg”,”pmg”,”god”}对应的有向图如下:
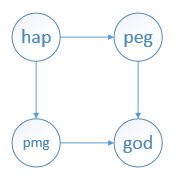
采用图的邻接表 表示法 来实现图。使用Map来代表图的邻接表。
Key 表示顶点的标识,如,”hap”,”peg”….
Value 表示顶点的邻接表。如,顶点”hap”的邻接表是
因此,这里就用一个简单的Map来实现了图。而不是像这篇文章:数据结构–图 的JAVA实现(上) 中那样,定义顶点类Vertex.java,边类Edge.java。
构造图的具体代码思路如下:先初始化整个图,将每个顶点添加到图中,并初始化它们的邻接表。
Map> graph = new HashMap>(arr.length);//根据字符串数组arr构造图
for (String str : arr) {
graph.put(str, new ArrayList());
}
对字符串数组中的每个字符串,遍历数组中的其他字符串,判断:某个字符串A的第一个字符与另一个字符串B的最后一个字符 是否相同。若相同,则将字符串B添加到字符串A的邻接表中去。
if(start.charAt(startLen-1) == end.charAt(0))//start-->end
{
adjs = graph.get(start);
if(!adjs.contains(end))
adjs.add(end);
graph.put(start, adjs);
}else if(start.charAt(0) == end.charAt(endLen-1)){//end-->start
adjs = graph.get(end);
if(!adjs.contains(start))
adjs.add(start);
graph.put(end, adjs);
}
图的深度优先遍历算法实现
这里实现非递归DFS遍历。用一个LinkedListstack 来模拟递归DFS时用到的栈。用一个HashSet来标记某个顶点是否访问了,如果该顶点被访问了,则添加到HashSet中。用一个ArrayList来保存DFS遍历时经过的顶点路径,最终函数返回该ArrayList表示本次调用DFS遍历得到的访问路径。
ArrayList paths = new ArrayList<>(graph.size());//保存访问路径
HashSet visited = new HashSet<>(graph.size());//用来判断某个顶点是否已经访问了
LinkedList stack = new
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









