







由于es官网叫停river类的导入插件,因此原始的elasticsearch-jdbc-river变更为elasticsearch-jdbc,成为一个独立的导入工具。官方提到的同类型工具还有logstash,个人觉得logstash在做数据库同步的时候并不是很好用,有太多坑要填。
插件的github地址 https://github.com/jprante/elasticsearch-jdbc/
必须按照es的相应的版本安选择jdbc的版本
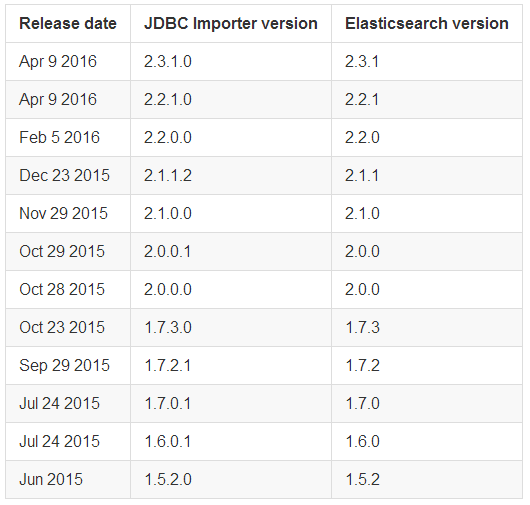
下载时将<version>替换成相应的版本即可。
解压下载的压缩包
修改 bin下面的相应的命令文件,比如 windows有一个mysql-simple-example.bat
启动即可
jdbc本身有个坑是如果mysql中某个字段的值本身就是一个json格式的话就会报错,例如:
org.elasticsearch.index.mapper.MapperParsingException: failed to parse [page]
因此需要使用mysql的拼接函数来解决。
CONCAT('(',HomePage,')') as `page`
报错信息:
java.net.MalformedURLException: unknown protocol: c
目前使用mysql导入数据到elasticsearch的方法常用方法如下:
elasticsearch-jdbc(早期的elasticsearch-river-jdbc)
https://github.com/jprante/elasticsearch-jdbc (推荐)
elasticsearch-river-mysql
https://github.com/scharron/elasticsearch-river-mysql
go-mysql-elasticsearch
https://github.com/siddontang/go-mysql-elasticsearch
logstash导入插件
https://github.com/elastic/logstash
常用配置说明:
{
"schedule" : "0 0/60 0-23 ? * *",
type: "jdbc",
jdbc: {
url: "jdbc:mysql://127.0.0.1:3306/test",
user: "root",
password: "root",
sql : [
{
"statement" : "select id as _id ... from ... where a = ?, b = ?, c = ?",
"parameter" : [ "value for a", "value for b", "value for c" ]
}
],
locale: "zh_CN",
index: "创建的索引名",
type: "创建的type名",
index_settings: {
index: {
number_of_shards: "3"
}
},
type_mapping: {
"type名": {
dynamic: true,
properties: {
"field名": {
type: "string",
analyzer: "ik",
indexAnalyzer: "ik",
searchAnalyzer: "ik"
},
"field名": {
type: "string",
analyzer: "ik",
indexAnalyzer: "ik",
searchAnalyzer: "ik"
},
"field名": {
type: "string",
analyzer: "ik",
indexAnalyzer: "ik",
searchAnalyzer: "ik"
},
"field名": {
type: "string",
analyzer: "ik",
indexAnalyzer: "ik",
searchAnalyzer: "ik"
},
"LOCATIONS": {
type: "geo_point"
}
}
}
}
}
}
常用介绍:
获取一个表,select * from table可以使用查询。 查询从数据库选择数据的简单的变体。 他们转储表成Elasticsearch逐行。 如果没有_id列名,IDs将自动生成。
id as _id 这样的话可以增量同步,_id是es的默认id命名
"interval":"1800", 这里是同步数据的频率 1800s,半小时,可以按需要设成 1s或其它
"schedule" : "0 0/60 0-23 ? * *", 同步数据任务 60分钟一次
"flush_interval" : "5s", 刷新间隔为5S
sql.parameter——绑定SQL语句参数(按顺序)。 可以使用一些特殊的值具有以下含义:
$now——当前时间戳
$state——国家之一:BEFORE_FETCH,取回,AFTER_FETCH,无所事事,例外
$metrics.counter——一个计数器
$lastrowcount——从最后一条语句的行数
$lastexceptiondate- SQL时间戳的例外
$lastexception——完整的堆栈跟踪的例外
$metrics.lastexecutionstart——最后一次执行SQL时间戳的时候开始
$metrics.lastexecutionend- SQL时间戳的时候最后一次执行结束
$metrics.totalrows——总获取的行数
$metrics.totalbytes——获取的字节总数
$metrics.failed——失败的SQL执行的总数
$metrics.succeeded
删除river:
curl -XDELETE localhost:9200/_river/_meta
http:// localhost:9200/_river/_meta delete请求
参数名的介绍:
locale默认语言环境(用于解析数值,浮点的性格。 推荐的值是“en_US”)
timezone——JDBC的时区setTimestamp()调用绑定参数时的时间戳值
rounding——舍入模式解析数值。 可能的值“天花板”,“下”,“地板”,“halfdown”、“halfeven”,“halfup”、“不必要的”,“上”
scale——解析数值的精度
autocommit- - - - - -true如果每个语句应该被自动执行。 默认是false
fetchsize——fetchsize大型结果集,大多数司机使用这个控制行缓冲的数量而遍历结果集
max_rows——声明限制获取的行数,其余的行被忽略
max_retries——重试的次数(重新)连接到一个数据库
max_retries_wait——时间价值的时间应重试之间等。
resultset_type- JDBC结果集类型,可以TYPE_FORWARD_ONLY TYPE_SCROLL_SENSITIVE TYPE_SCROLL_INSENSITIVE。 默认是TYPE_FORWARD_ONLY
resultset_concurrency- JDBC结果集并发性,可以CONCUR_READ_ONLY CONCUR_UPDATABLE。 默认是CONCUR_UPDATABLE
ignore_null_values——如果NULL值构建JSON文档时应该被忽略。 默认是false
detect_geo——如果geo多边形/分在SQL列构造时应解析JSON文档。 默认是true
detect_json——如果json结构构建json文档时应该解析SQL列。 默认是true
prepare_database_metadata——如果司机元数据作为参数要准备好。 默认是false
prepare_resultset_metadata——如果结果集元数据应该准备作为参数。 默认是false
column_name_map——地图的别名应该用作替代数据库的列名称。 对于Oracle 30 char列名称限制。 默认是null
query_timeout——第二个价值多长时间允许SQL语句被执行之前被认为是输了。 默认是1800
connection_properties——地图的连接属性用于创建驱动程序连接。 默认是null
schedule——一个单一的或cron表达式列表计划执行。 语法是相当于 石英cron表达式格式语法(见下文)
threadpoolsize——计划执行的线程池的大小schedule参数。 如果设置为1,所有工作将连续执行。 默认是4。
interval——两个运行之间的延迟时间值(默认值:不设置)
elasticsearch.cluster——Elasticsearch集群名称
elasticsearch.host——一系列Elasticsearch主机(主机名或规范host:port)
elasticsearch.port——Elasticsearch主机
elasticsearch.autodiscover——如果true、JDBC进口国将尝试连接到所有集群节点。 默认是false
max_bulk_actions每个批量索引请求提交的长度(默认值:10000)
max_concurrrent_bulk_requests并发大量请求的最大数量(默认值:2 * CPU核的数量)
max_bulk_volume——一个字节大小参数允许的最大体积的大部分请求(默认值:10米)
max_request_wait——时间价值的最大等待时间响应大部分请求
flush_interval——时间价值区间段冲洗索引文档批量操作(默认值:“5 s”)
index——Elasticsearch指数用于索引
type——Elasticsearch用于索引的索引类型
index_settings-可选设置Elasticsearch指数
type_mapping-可选为Elasticsearch指数类型映射
statefile——文件的名称JDBC进口国读写状态信息
metrics.lastexecutionstart——开始的UTC日期/时间的最后一次执行一个获取
metrics.lastexecutionend——最后的UTC日期/时间的最后一次执行一个获取
metrics.counter——一个计数器度量,将每一个获取后增加
metrics.enabled——如果true启用日志记录,指标。 默认是false
metrics.interval——度量日志之间的时间间隔。 默认是30秒。
metrics.logger.plain——如果true纯文本格式的日志消息,写指标。 默认是false
metrics.logger.json——如果true、写度量JSON格式的日志消息。 默认是false
博客地址:http://my.oschina.net/wangnian















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









