






名称:GetTB
大小:2.90 MB
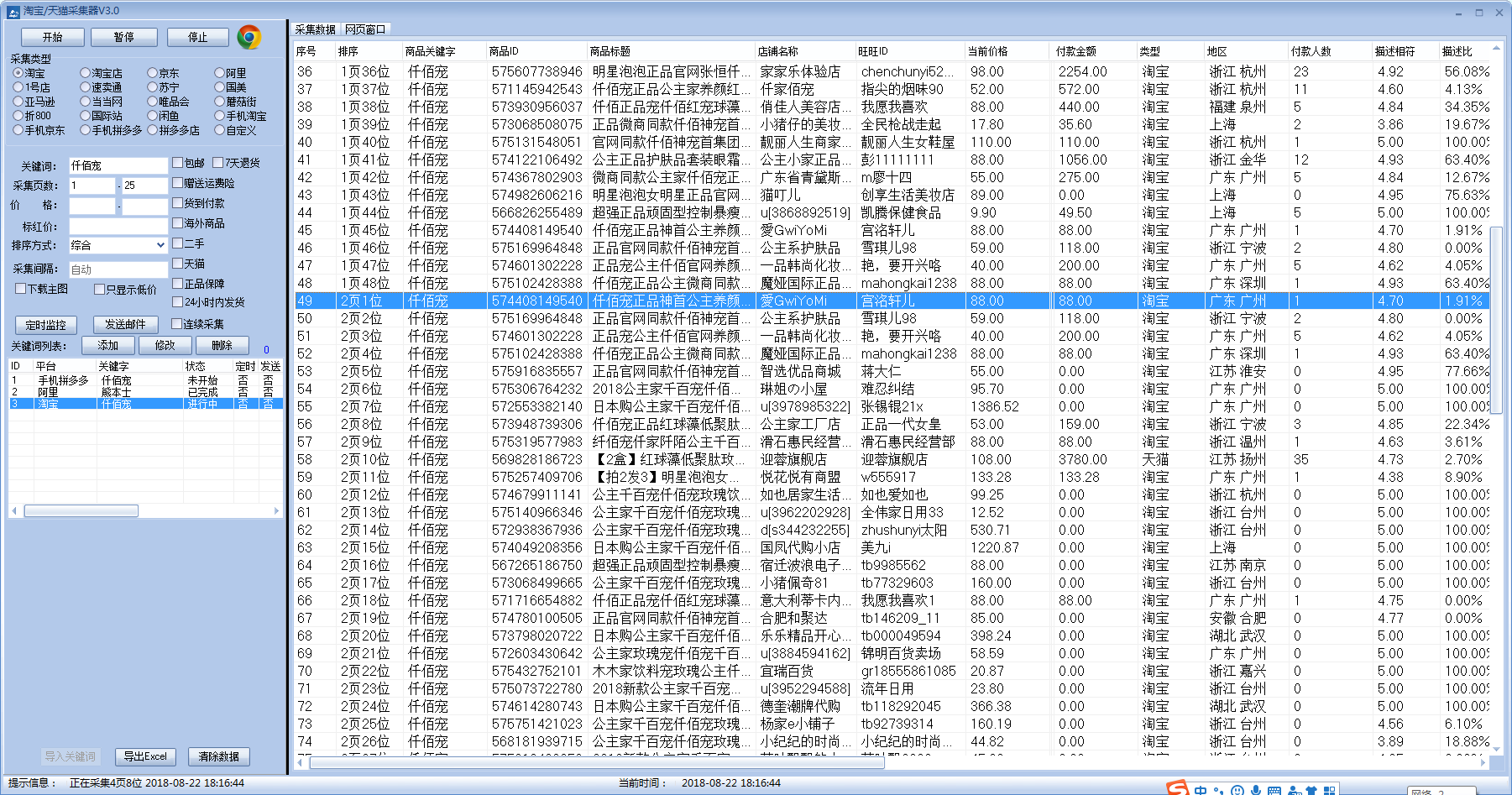
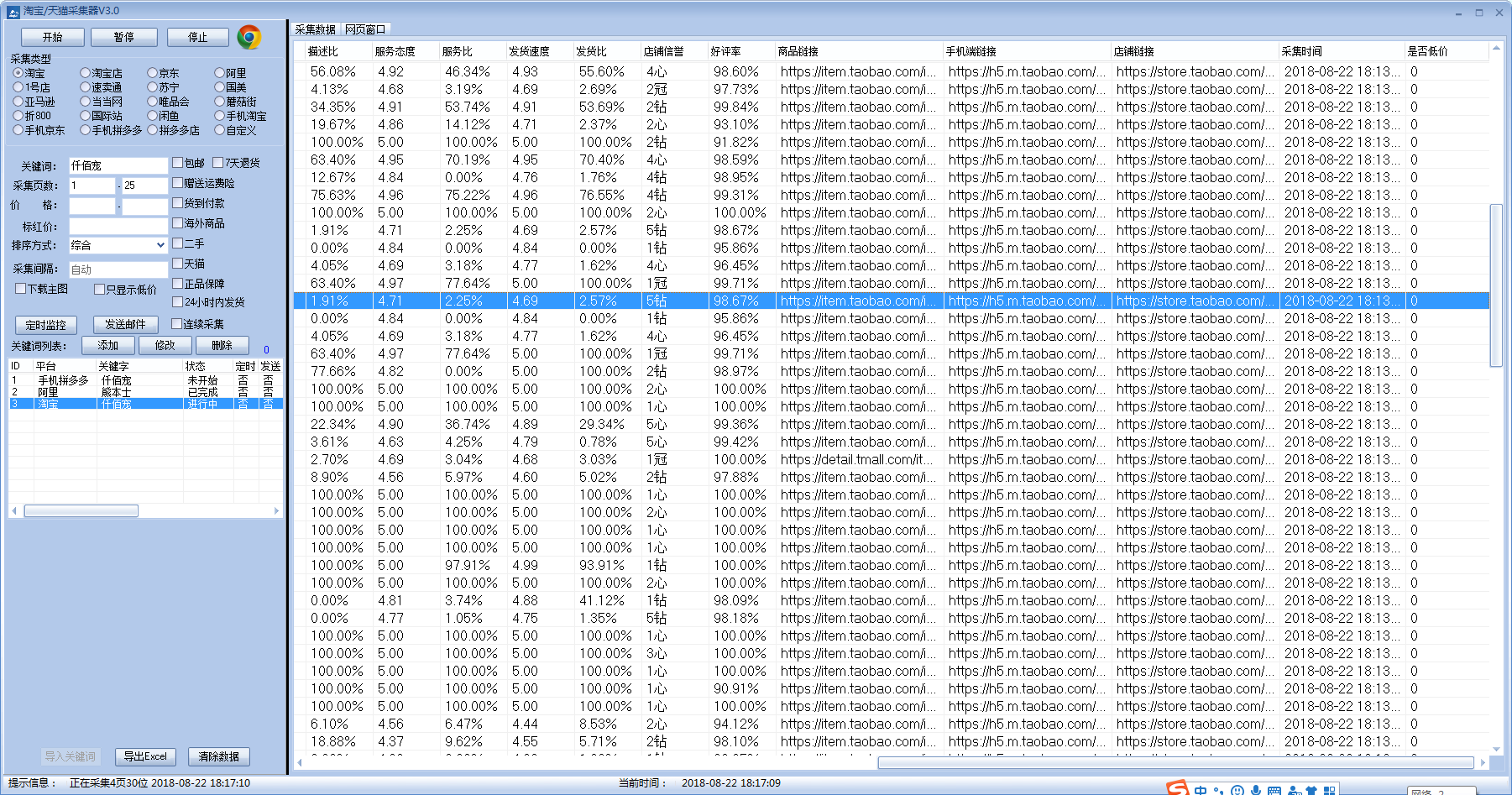
主要功能:采集电商平台数据软件,主要才用Delphi7语言开发,可以采集淘宝,京东,淘宝店,苏宁等电商平台宝贝数据;
1.采集支持平台:[淘宝、天猫、淘宝店、天猫店、咸鱼、京东、阿里、1号店、速卖通、苏宁、国美、贝贝网、亚马逊、当当网、唯品会、蘑菇街、折800、自定义、手机淘宝、拼多多];
2.淘宝天猫可以实现采集店铺信誉、开店时间、上下架时间、月销量、淘宝类目、历史价格、手机端价格等;
3.支持自定义链接采集,直接通过导入EXCEL的链接,实现采集;
4.支持截图为证,把当时宝贝价格、标题等截图保存下来;
使用第三方插件:
1.CoolTrayIcon
2.dcef3.245
3.EhLib 5.65.6.20
4.EmbeddedWB14.67.8改进版
5.Indy10.5.6
6.TMS_6911
7.VCLSkin5.60
版本信息:
[Version]2017.12.8.1[/Version]

















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









