







本次采用完全分布式系列的hadoop集群,安装配置过程详细参见
Hive在分布式集群上的部署配置参见
检查本地hadoop版本
[hadoop@node222 ~]$ hadoop version
Hadoop 2.6.5
Subversion https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997
Compiled by sjlee on 2016-10-02T23:43Z
Compiled with protoc 2.5.0
From source with checksum f05c9fa095a395faa9db9f7ba5d754
This command was run using /usr/local/hadoop-2.6.5/share/hadoop/common/hadoop-common-2.6.5.jar
下载与hadoop配套Sqoop安装包,本次下载sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz。
在集群环境中,Sqoop只用安装部署在NameNode节点上。
安装部署
解压并修改sqoop目录名
[root@node222 ~]# gtar -xzf /home/hadoop/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/
[root@node222 ~]# mv /usr/local/sqoop-1.4.7.bin__hadoop-2.6.0 /usr/local/sqoop-1.4.7配置环境变量
[root@node222 ~]# vi /etc/profile
# 追加如下内容
export SQOOP_HOME=/usr/local/sqoop-1.4.7
export PATH=%{SQOOP_HOME}/bin:$PATH
# 使配置生效
[root@node222 ~]# source /etc/profile拷贝生成配置文件
[root@node222 ~]# cp /usr/local/sqoop-1.4.7/conf/sqoop-env-template.sh /usr/local/sqoop-1.4.7/conf/sqoop-env.sh
[root@node222 ~]# vi /usr/local/sqoop-1.4.7/conf/sqoop-env.sh
# 追加如下内容
export HADOOP_MAPRED_HOME=/usr/local/hadoop-2.6.5
export HADOOP_MAPRED_HOME=/usr/local/hadoop-2.6.5
export HIVE_HOME=/usr/local/hive-2.1.1测试sqoop,输出sqoop可用的工具
[root@node222 ~]# /usr/local/sqoop-1.4.7/bin/sqoop help
Warning: /usr/local/sqoop-1.4.7/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop-1.4.7/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4.7/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop-1.4.7/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
18/10/12 13:47:49 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
# 查询具体sqoop工具的帮助信息
[root@node222 ~]# /usr/local/sqoop-1.4.7/bin/sqoop help list-databasessqoop连接MySQL,需要将MySQL的驱动包添加至sqoop的${SQOOP_HOME}/lib目录
操作实例
连接mysql列出mysql的数据表,密码通过命令行输入
sqoop list-tables --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --username sakila -P
# 操作示例
# 屏蔽mysql SSL连接错误
useSSL=false
# 执行是输入密码
-P
[root@node222 ~]# sqoop list-tables --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --username sakila -P
Warning: /usr/local/sqoop-1.4.7/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop-1.4.7/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4.7/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop-1.4.7/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
18/10/12 14:15:29 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Enter password:
18/10/12 14:15:35 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
actor
address
category
city
country
customer
film
film_actor
film_category
film_text
inventory
language
payment
rental
staff
store
将sakila的actor表导入hdfs
sqoop import --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --as-textfile --target-dir /tmp/sqoop/actor
# 操作示例
# 集群创建HDFS目录
[hadoop@node224 ~]$ hdfs dfs -mkdir -p /tmp/sqoop
# 指定hdfs文件格式默认即是textfile
--as-textfile
# 指定hdfs目录
--target-dir
[root@node222 ~]# /usr/local/sqoop-1.4.7/bin/sqoop import --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --as-textfile --target-dir /tmp/sqoop/actor
...告警信息
Enter password:
18/10/12 14:32:42 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
...
18/10/12 14:33:17 INFO mapreduce.Job: map 0% reduce 0%
18/10/12 14:33:34 INFO mapreduce.Job: map 25% reduce 0%
18/10/12 14:33:37 INFO mapreduce.Job: map 100% reduce 0%
18/10/12 14:33:37 INFO mapreduce.Job: Job job_1539322140143_0001 completed successfully
18/10/12 14:33:37 INFO mapreduce.Job: Counters: 31
...
18/10/12 14:33:37 INFO mapreduce.ImportJobBase: Transferred 7.6162 KB in 47.558 seconds (163.9894 bytes/sec)
18/10/12 14:33:37 INFO mapreduce.ImportJobBase: Retrieved 200 records.通过Web 50070端口查看HDFS导入文件信息
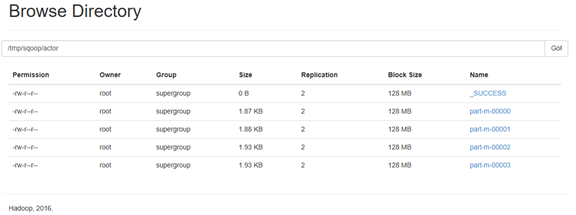
将导入到hdfs的actor表导出至MySQL的sakila数据库
sqoop export --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --export-dir /tmp/sqoop/actor
# 导出
export
# 要导入的表
--table
# 要导出的HDFS目录
--export-dir
#操作示例
[root@node222 ~]# /usr/local/sqoop-1.4.7/bin/sqoop export --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --export-dir /tmp/sqoop/actor
...
18/10/12 14:49:03 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Enter password:
...
18/10/12 14:49:18 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
18/10/12 14:49:20 INFO input.FileInputFormat: Total input paths to process : 4
18/10/12 14:49:20 INFO input.FileInputFormat: Total input paths to process : 4
18/10/12 14:49:20 INFO mapreduce.JobSubmitter: number of splits:3
18/10/12 14:49:20 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
18/10/12 14:49:22 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1539322140143_0002
18/10/12 14:49:23 INFO impl.YarnClientImpl: Submitted application application_1539322140143_0002
18/10/12 14:49:23 INFO mapreduce.Job: The url to track the job: http://node224:8088/proxy/application_1539322140143_0002/
18/10/12 14:49:23 INFO mapreduce.Job: Running job: job_1539322140143_0002
18/10/12 14:49:31 INFO mapreduce.Job: Job job_1539322140143_0002 running in uber mode : false
18/10/12 14:49:31 INFO mapreduce.Job: map 0% reduce 0%
18/10/12 14:49:41 INFO mapreduce.Job: map 100% reduce 0%
18/10/12 14:49:42 INFO mapreduce.Job: Job job_1539322140143_0002 failed with state FAILED due to: Task failed task_1539322140143_0002_m_000001
Job failed as tasks failed. failedMaps:1 failedReduces:0
18/10/12 14:49:42 INFO mapreduce.Job: Counters: 12
Job Counters
Failed map tasks=1
Killed map tasks=2
Launched map tasks=3
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=19777
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=19777
Total vcore-milliseconds taken by all map tasks=19777
Total megabyte-milliseconds taken by all map tasks=20251648
Map-Reduce Framework
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
18/10/12 14:49:42 WARN mapreduce.Counters: Group FileSystemCounters is deprecated. Use org.apache.hadoop.mapreduce.FileSystemCounter instead
18/10/12 14:49:42 INFO mapreduce.ExportJobBase: Transferred 0 bytes in 24.7547 seconds (0 bytes/sec)
18/10/12 14:49:42 INFO mapreduce.ExportJobBase: Exported 0 records.
18/10/12 14:49:42 ERROR mapreduce.ExportJobBase: Export job failed!
18/10/12 14:49:42 ERROR tool.ExportTool: Error during export:
Export job failed!
at org.apache.sqoop.mapreduce.ExportJobBase.runExport(ExportJobBase.java:445)
at org.apache.sqoop.manager.SqlManager.exportTable(SqlManager.java:931)
at org.apache.sqoop.tool.ExportTool.exportTable(ExportTool.java:80)
at org.apache.sqoop.tool.ExportTool.run(ExportTool.java:99)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
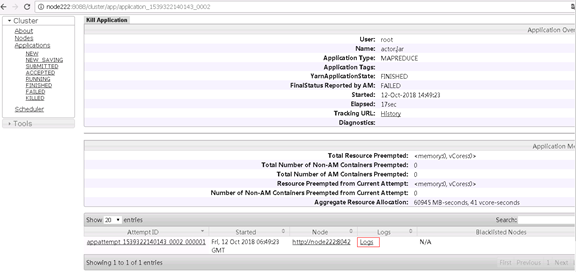
#错误在此处提示的并不清晰,可以通过web访问YARN界面,查询失败的的Logs,第一次查询日志会失败,需要在本地的host文件中将namenode节点的IP地址和机器名配置,因为进入logs默认通过机器名访问,查看syslog : Total file length is 36829 bytes.在选择Showing 4096 bytes. Click here for full log查看全部日志信息。
#以上问题,经分析因主键冲突导致
2018-10-12 14:49:40,036 FATAL [IPC Server handler 4 on 54583] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Task: attempt_1539322140143_0002_m_000001_0 - exited : java.io.IOException: com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Duplicate entry '1' for key 'PRIMARY'
at org.apache.sqoop.mapreduce.AsyncSqlRecordWriter.close(AsyncSqlRecordWriter.java:205)
at org.apache.hadoop.mapred.MapTask$NewDirectOutputCollector.close(MapTask.java:667)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:790)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1692)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Duplicate entry '1' for key 'PRIMARY'
#新建表,去掉主外键限制,测试
CREATE TABLE actor_new (
actor_id SMALLINT(5),
first_name VARCHAR(45),
last_name VARCHAR(45),
last_update TIMESTAMP
);
[root@node222 ~]# /usr/local/sqoop-1.4.7/bin/sqoop export --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor_new --username sakila -P --export-dir /tmp/sqoop/actor
...
Enter password:
...
18/10/12 15:50:38 INFO mapreduce.Job: map 0% reduce 0%
18/10/12 15:50:46 INFO mapreduce.Job: map 33% reduce 0%
18/10/12 15:50:50 INFO mapreduce.Job: map 67% reduce 0%
18/10/12 15:50:57 INFO mapreduce.Job: map 100% reduce 0%
18/10/12 15:50:58 INFO mapreduce.Job: Job job_1539329749790_0001 completed successfully
18/10/12 15:50:59 INFO mapreduce.Job: Counters: 31
...
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
18/10/12 15:50:59 INFO mapreduce.ExportJobBase: Transferred 10.083 KB in 46.5563 seconds (221.7744 bytes/sec)
18/10/12 15:50:59 INFO mapreduce.ExportJobBase: Exported 200 records.
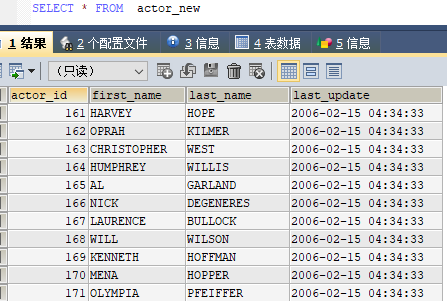
# 查询确认导出结果
SELECT * FROM actor_new日志查询
导出结果
将MySQL中的actor表导入hive
sqoop import --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --hive-import
# 将数据表导入Hive
--hive-import
[root@node222 ~]# /usr/local/sqoop-1.4.7/bin/sqoop import --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --hive-import
...
Enter password:
...
18/10/12 16:30:59 ERROR hive.HiveConfig: Could not load org.apache.hadoop.hive.conf.HiveConf. Make sure HIVE_CONF_DIR is set correctly.
18/10/12 16:30:59 ERROR tool.ImportTool: Import failed: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
at org.apache.sqoop.hive.HiveConfig.getHiveConf(HiveConfig.java:50)
at org.apache.sqoop.hive.HiveImport.getHiveArgs(HiveImport.java:392)
at org.apache.sqoop.hive.HiveImport.executeExternalHiveScript(HiveImport.java:379)
at org.apache.sqoop.hive.HiveImport.executeScript(HiveImport.java:337)
at org.apache.sqoop.hive.HiveImport.importTable(HiveImport.java:241)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:537)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at org.apache.sqoop.hive.HiveConfig.getHiveConf(HiveConfig.java:44)
# 将hive-exec-2.1.1.jar拷贝至sqoop的lib目录解决
[root@node222 ~]# cp /usr/local/hive-2.1.1/lib/hive-exec-2.1.1.jar /usr/local/sqoop-1.4.7/lib/
[root@node222 ~]# ls /usr/local/sqoop-1.4.7/lib/hive-exec-2.1.1.jar
/usr/local/sqoop-1.4.7/lib/hive-exec-2.1.1.jar
# 再次报错,提示HDFS上已经存在该目录
18/10/12 16:40:36 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
18/10/12 16:40:37 ERROR tool.ImportTool: Import failed: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://ns1/user/root/actor already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:267)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:140)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1297)
# 删掉该目录再试
[hadoop@node224 ~]$ hdfs dfs -rm -r /user/root/actor
18/10/12 16:42:05 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /user/root/actor
# 执行成功
[root@node222 ~]# /usr/local/sqoop-1.4.7/bin/sqoop import --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --hive-import
...
Enter password:
...
18/10/12 16:43:47 INFO mapreduce.Job: map 0% reduce 0%
18/10/12 16:43:55 INFO mapreduce.Job: map 25% reduce 0%
18/10/12 16:43:56 INFO mapreduce.Job: map 50% reduce 0%
18/10/12 16:44:05 INFO mapreduce.Job: map 100% reduce 0%
18/10/12 16:44:06 INFO mapreduce.Job: Job job_1539329749790_0003 completed successfully
...
18/10/12 16:44:31 INFO hive.HiveImport: OK
18/10/12 16:44:31 INFO hive.HiveImport: Time taken: 3.857 seconds
18/10/12 16:44:32 INFO hive.HiveImport: Loading data to table default.actor
18/10/12 16:44:33 INFO hive.HiveImport: OK
18/10/12 16:44:33 INFO hive.HiveImport: Time taken: 1.652 seconds
18/10/12 16:44:34 INFO hive.HiveImport: Hive import complete.
18/10/12 16:44:34 INFO hive.HiveImport: Export directory is contains the _SUCCESS file only, removing the directory.
# 查询测试
0: jdbc:hive2://node225:10000/default> show tables;
+-----------+--+
| tab_name |
+-----------+--+
| actor |
+-----------+--+
1 row selected (0.172 seconds)
0: jdbc:hive2://node225:10000/default> select * from actor limit 2;
+-----------------+-------------------+------------------+------------------------+--+
| actor.actor_id | actor.first_name | actor.last_name | actor.last_update |
+-----------------+-------------------+------------------+------------------------+--+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33.0 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33.0 |
+-----------------+-------------------+------------------+------------------------+--+
2 rows selected (0.349 seconds)导入指定的hive库下指定hive表
/usr/local/sqoop-1.4.7/bin/sqoop import --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --hive-import --hive-table db01.t_actor
# 导入hive
--hive-import
# 导入指定库和表
--hive-table database.table_name
[root@node222 ~]# /usr/local/sqoop-1.4.7/bin/sqoop import --connect jdbc:mysql://192.168.0.200:3306/sakila?useSSL=false --table actor --username sakila -P --hive-import --hive-table db01.t_actor
...
18/10/12 17:12:47 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Enter password:
...
18/10/12 17:13:10 INFO mapreduce.Job: map 0% reduce 0%
18/10/12 17:13:20 INFO mapreduce.Job: map 25% reduce 0%
18/10/12 17:13:22 INFO mapreduce.Job: map 50% reduce 0%
18/10/12 17:13:26 INFO mapreduce.Job: map 100% reduce 0%
18/10/12 17:13:26 INFO mapreduce.Job: Job job_1539329749790_0006 completed successfully
...
18/10/12 17:13:35 INFO hive.HiveImport:
18/10/12 17:13:35 INFO hive.HiveImport: Logging initialized using configuration in jar:file:/usr/local/hive-2.1.1/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true
18/10/12 17:13:47 INFO hive.HiveImport: OK
18/10/12 17:13:47 INFO hive.HiveImport: Time taken: 3.125 seconds
18/10/12 17:13:48 INFO hive.HiveImport: Loading data to table db01.t_actor
18/10/12 17:13:48 INFO hive.HiveImport: OK
18/10/12 17:13:48 INFO hive.HiveImport: Time taken: 1.529 seconds
18/10/12 17:13:49 INFO hive.HiveImport: Hive import complete.
18/10/12 17:13:49 INFO hive.HiveImport: Export directory is contains the _SUCCESS file only, removing the directory.
# 在db01库中查询确认
0: jdbc:hive2://node225:10000/db01> select * from t_actor limit 5;
+-------------------+---------------------+--------------------+------------------------+--+
| t_actor.actor_id | t_actor.first_name | t_actor.last_name | t_actor.last_update |
+-------------------+---------------------+--------------------+------------------------+--+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33.0 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33.0 |
| 3 | ED | CHASE | 2006-02-15 04:34:33.0 |
| 4 | JENNIFER | DAVIS | 2006-02-15 04:34:33.0 |
| 5 | JOHNNY | LOLLOBRIGIDA | 2006-02-15 04:34:33.0 |
+-------------------+---------------------+--------------------+------------------------+--+
5 rows selected (0.457 seconds)















 1078
1078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









