







说到IO,很多人就联想到读写磁盘文件,其实这只是其中一种。对Linux系统而言,所有设备都是文件,其中包括磁盘、内存、网卡、键盘、显示器等等,对所有这些文件的访问都属于IO。针对所有的IO对象,可以将IO分成三类:网络IO、磁盘IO和内存IO。而通常我们说的是前两种。
举个最常见的涉及到IO的例子:当我们要通过浏览器访问网站某张图片,整个过程的数据流向图如下:
浏览器发起请求,请求首先到达服务器网卡,再到达Nginx(这里以Nginx为例),Nginx读取磁盘上的数据,读取成功后再将图片返回给浏览器。这里涉及到2次IO,分别是读IO、写IO。读IO:图片从磁盘被读取到内存;写IO,图片从内存中被写进网卡缓冲区,发回给浏览器。这里涉及到操作系统内存操作的过程,在此先简单介绍下Linux的内存管理。
Linux内存管理
每台计算机运行都需要内存,这些内存是供内核系统和用户进程一起使用。Linux在操作这些物理内存时,不会直接操作物理内存,而是建立一个虚拟地址(可以理解成跟物理内存相对应的映射),即在物理内存跟进程之间增加一个中间层。为什么不直接操作物理内存?原因如下:
1,隔离不同进程使用的内存地址空间;
2,提高内存的使用率;
3,确定程序运行时的地址;
4,扩展内存,即运行所需内层大于物理内存的程序
个人认为最重要的是第一条:Linux运行时需要内存来存放系统内核的数据,用户进程运行也需要内存存放数据;为了系统安全,Linux是防止用户进程直接操作内核空间所占空间的,免得系统被用户进程搞挂掉。为此,系统将虚拟地址分为两部分:一部分专门给系统内核使用,另一部分给用户进程使用。对于32位的系统,虚拟地址范围是0x00000000 ~ 0xFFFFFFFF,即最大虚拟内存为2^32 Bytes = 4GB,系统将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF)分配内核使用,此区域称作内核空间;另外将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。由于虚拟地址是物理内存的映射,相当于系统将物理内存分成两部分单独使用。所以,现在有两个概念:
- 内核空间:系统内核使用的内存空间;当一个进程执行调用系统命令(例如read, write)时,会进入内核代码的执行,进程此时的状态我们称之为内核态。
- 用户空间:用户进程使用的内存空间;当一个进程执行用户自己的代码时,该进程此时的状态为用户态。
再看回获取图片的例子,Nginx读取图片时(原始做法),图片不是一次就复制到用户空间的,结合下图看看:
实际上分为以下四步:
1,数据从磁盘被复制到内核空间的内存中(到了系统内存,还没到Nginx内存);
2,数据从内核空间的内存被复制到用户空间的内存(到了Nginx的内存中);
3,数据从用户空间内存被再复制到内核空间内存(Socket缓冲区);
4,再从内核空间复制到协议引擎(网卡驱动的传输队列);
其中第1、2步是读IO,3、4步是写IO,nginx输出一张图片的数据流向大致是这样。那我们平时经常提到的同步、异步、阻塞、非阻塞,其实是描述上面流程里的其中一个过程。
阻塞和非阻塞:描述是上面的第1步,即在数据被拷贝到内核空间前,用户进程是否等待。如果用户进程是等待的,就是阻塞;如果用户进程是立即返回,就是非阻塞。
同步和异步:描述是上面的第2步,即数据从内核空间复制到用户进程空间,这时用户进程是否处于等待状态,如果是用户进程需要等待,即为同步;否则为异步。
看回Nginx读取磁盘图片这个过程,这里可以分为两个角色:用户进程(Nginx)、系统内核。那读取图片,其实是Nginx叫系统帮他读取图片,下面我们就以两个不同的角度分析这个读取图片的过程。
- 用户进程的角度:用户进程是怎么将IO任务告诉系统的,并且在系统准备数据的过程中,用户进程处于什么状态?我们所说IO模式其实就是描述了这些问题。
- 系统内核的角度:系统接收到用户进程的IO任务之后,实际就是做数据拷贝工作;那系统怎么优化这个拷贝过程?我们所说的零拷贝就是解决这些问题。下面先从用户进程的角度看这个过程。
IO模式(用户进程角度)
1,同步阻塞IO(blocking IO)
这是最简单的IO模型,还是拿读取图片来剖析。

图里描述的其实就是上文里提到的第1、2步。用户进程调用read操作之后,开始进入阻塞状态;wait for data阶段是等待系统从磁盘拷贝数据,copy data from kernel to user阶段是等待系统将数据从内核空间拷贝到用户空间。这2个步骤中,一直处于阻塞状态。当数据都拷贝到用户空间后,用户进程才重获自由。
2,同步非阻塞IO(nonblocking IO)

这是在同步阻塞上做了改进,优化点在wait for data阶段。用户进程调用read操作后,如果内核空间的内容还没准备好,会立即返回一个error信号,用户进程收到error之后,不会进入阻塞状态,而是循环发起read操作直到数据就绪。当数据就绪,用户进程此时进入阻塞状态,等待系统将数据从内核空间复制到用户空间,复制完成后再返回。
3,多路复用IO(IO multiplexing)
上面的同步阻塞、同步非阻塞,每次只能处理单个连接IO。当同时要处理很多个耗时短的IO,多路复用IO就擅长干这个,我们所说的select,poll,epoll都属于多路复用IO。多路复用IO主要改进在单个进程就可以同时处理多个IO,下图以select为例。

用户进程一开始就要同时处理多个IO,调用select之后,会将这些IO任务一次性给到系统,并处于阻塞状态。系统接收到IO任务后,开始准备数据;当其中有一个或多个IO任务完成,就会通知用户进程。这时用户进程再调用read,将数据复制到用户空间。poll,epoll工作模式大致一样。
但select有一个缺点:单个进程所能监视的文件描述符的数量存在最大限制,具体的上限值取决于系统参数FD_SIZE,修改此参数需要重新编译内核,比较麻烦。而poll则通过一种新的数据结构向内核传递需要关注的事件,绕开文件描述符数量限制。但select与poll都存在同一个问题:当其中有一个或多个IO任务完成时,会将所有的IO任务返回给用户进程,让用户进程去遍历具体是哪几个任务已经完成;当同时监听大量文件描述符时,这所有的文件描述符会在用户空间与内核空间中多次复制,效率低下。
epoll的出现解决了select和poll的共有问题。epoll初始化时会创建一个文件描述符,并且将用户关系的文件描述符的事件存放到内核的一个事件表中;当有描述符就绪时,只将就绪的描述符返回给用户进程(通过设置callback函数实现)。而且epoll所能管理文件描述符的数量上限取决于系统最大句柄数(ulimit),此参数更改非常快捷。
epoll对文件描述符操作有两种工作模式:水平触发(level trigger)和边缘触发(edge trigger),其中水平出发是默认的工作模式。两者区别如下:
- 水平出发:当系统检测到有就绪的文件描述符并通知给用户进程,用户进程可以暂时不处理;如果用户进程没处理,系统会在下次通知时重复返回。
- 边缘出发:当系统检测到有就绪的文件描述符并通知给用户进程,用户进程必须要处理;如果没处理,系统下次不会再返回;这样处理性能更高,如果也会有消息丢失的可能。
目前,Linux2.6下,epoll是最高效的IO复用方式,也是Nginx的IO实现方式。而在freeBSD下,kqueue是另一种类似于epoll的IO复用方式。Windows下类似epoll的IO复用方式是IOCP。
4,信号驱动IO( signal driven IO)

信号驱动IO相当于同步非阻塞的升级版。用户进程调用read命令,系统在准备数据时,用户进程不会被阻塞,可以同时做其他任务,不需要循环去问系统数据是否准备就绪;当数据准备好之后,系统通知用户进程。但在数据从内核空间复制到用户空间这阶段,此时用户进程处于阻塞状态。
5,异步非阻塞IO(asynchronous IO)

这种模式最爽了,用户进程发起read操作之后,操作系统立即返回信号,不会阻塞用户进程,用户进程继续干活。当数据都被拷贝到用户空间后,系统再通知用户进程。
上面讨论的IO模式,其实是以用户进程的角度看IO:当用户进程发起IO操作后,用户进程是怎么将任务告知到系统;但数据未就绪时,用户进程处于什么状态。
下面我们再以系统内核的角度看IO:用户进程要求发起IO操作时,系统内核自己属于什么状态,具体在做什么?简单的说,此时的操作系统接就是一个数据的搬运工,实质上是数据拷贝的过程,将数据从一个区域拷贝到另外一个区域。而当涉及到用户空间与内核空间的拷贝,因为占用CPU和内存带宽,Linux也对这部分做了各种优化,也就是平时所说的“零拷贝”。
Linux零拷贝(系统内核角度)
回顾前文图一,无论是读数据还是写数据,数据都要经过文件(外设)- 内核 - 用户空间之间的拷贝。下面对图片读取到发送到网卡的过程再作一个剖析。
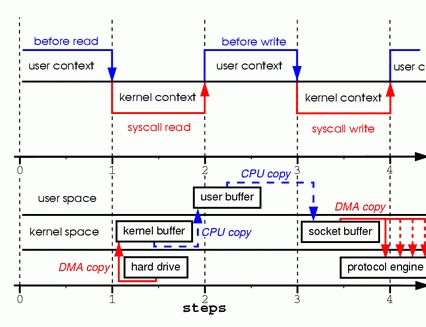
图片上半部分描述的是上下文切换,下半部分描述的是数据拷贝。
- 用户进程调用read命令,从用户空间进入内核空间,发生第一次上下文切换;系统收到命令时,开始读取磁盘文件,将文件数据拷贝到内核空间,发生第一次数据拷贝。
- 数据在系统空间就绪后,再次被复制到用户空间,发生第二次拷贝数据拷贝;都拷贝到用户空间后,系统调用read返回,用户进程从内核空间返回到用户空间,发生第二次上下文切换;
- 用户进程要将数据返回给用户,需要将数据写到网卡缓冲,调用write命令。这里用户进程再次从用户空间进入内核空间,发生第三次上下文切换;数据从用户空间拷贝到socket相关的缓冲区(内核空间),发生第三次拷贝数据拷贝。
- 数据到达socket缓冲区后,系统调用返回,用户进程再次从内核态进入用户态,发生第四次上下文切换;此时系统再调用DMA将数据从socket缓冲区拷贝到网卡协议引擎。
整个过程总共划分成四步骤,共涉及4次上下文切换+4次拷贝动作。
“零拷贝”的目的就是优化这多次数据拷贝的过程,避免CPU将数据从一块存储拷贝到另外一块存储的手段。目前零拷贝的实现方式有很多种,大体可以分为三类:
- 一,应用程序可以直接访问硬件存储
- 二,避免在用户空间与内核空间中拷贝
- 三,对用户空间与内核空间的拷贝进行优化
下面会根据各类列举一些已经实现的方案。
1,直接IO

这是属于第一类,应用程序直接访问硬件存储。如图所示,用户进程直接操作文件,文件数据直接到达用户进程内存,不需要经过系统内核。这样做有2大好处:
1,从两次拷贝减少至一次拷贝。
2,在这个过程中,系统内核只做了简单的虚拟存储配置工作,不参与传输过程,降低对CPU的消耗。
2,MMAP
这种属于第二类优化,避免在用户空间与内核空间中拷贝。MMAP实际上是数据不会到达用户空间内存,只会存在于系统空间的内存,用户空间与系统空间共用同一个缓冲区。再看看通过MMAP读取文件的流程图,其中上下文切换部分没有变化。

1,用户进程调用MMAP,系统通过DMA将数据复制到系统空间内存,由于用户进程跟系统共用这块内存区,所以不需要额外再将数据拷贝到用户空间,所以只发生一次数据拷贝。
2,应用调用write操作之后,数据从系统空间内存拷贝到socket缓冲区,发生第二次数据拷贝。
3,接着数据从socket缓冲区拷贝到网卡协议引擎,第三次数据拷贝。
整个MMAP过程,发生了4次上下文切换+3次数据拷贝。而且上文提到的epoll模式,也是使用mmap来避免内核与用户空间的消息传递。
3,sendfile
这种属于第二类优化,避免在用户空间与内核空间中拷贝。sendfile的出现简化用户接口,用户进程不需要单独调用read/write,直接调用sendfile,sendfile再帮用户调用read/write操作。

1,用户进程调用sendfile,从用户空间进入内核空间,发生第一次上下文切换。系统收到命令后,通过DMA将数据复制到系统空间内存,然后立即将数据从用户空间拷贝到socket缓冲区,发生2次数据拷贝。
2,系统调用返回,用户进程从内核空间返回到用户空间,发生第二次上下文切换。同时系统再调用DMA将数据从socket缓冲区拷贝到网卡协议引擎,发生第三次数据拷贝。
整个sendfile过程,发生了2次上下文切换+3次数据拷贝。
4,带有DMA收集拷贝功能的sendfile
这种属于第三类优化,避免在用户空间与内核空间中拷贝。这种sendfile由于借助硬件的帮助,再减少一次数据拷贝。

由于上下文切换动作跟普通的sendfile一样,下面只关注数据拷贝操作:
1,系统收到sendfile命令后,通过DMA将数据复制到系统空间内存;然后cpu只将带有文件位置和长度信息的缓冲区描述符传到socket缓冲区中,没有将数据拷贝过去,所以这里只发生一次拷贝。
2,系统再调用带有收集功能DMA模块,将数据从内核空间直接拷贝到网卡协议引擎,发生第二次数据拷贝。
这次只发生2次上下文切换 + 2次数据拷贝。
5,splice
splice流程跟sendfile相似:
1,支持内核空间里的数据拷贝,同时也支持用户空间与内核空间之间的拷贝。
2,splice也需要有两个文件描述符,一个输入源,一个输出源;但splice支持任意两个文件之间互连,而sendfile只支持文件到socket方向的传输。
splice() 可以在操作系统地址空间中整块地移动数据,从而减少大多数数据拷贝操作。
6,写时复制策略
写时复制策略有点像解决并发写数据的场景,跟上面提到的不一样;系统在运行中,不可避免同一块内存区域被多个进程同时应用。对于这同一块内存区域,其中有些进程需要读数据,有些进程需要写。多进程同时读一块数据时,没问题。但如果其中有一个写数据,那就会影响其他正在读取的进程。写时复制策略就是当用户进程有写操作时,将这块共享的内存空间复制一份到其他区域,给写进程专用。
Java的AIO、NIO、BIO
- BIO属于同步阻塞,客户端每发送一个请求,就开一个新的线程来处理。一种优化的方案是用线程池。
- NIO属于同步非阻塞,收到的请求都会先注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。NIO的实现里会根据系统判断选择对应的模式(poll, epoll,kqueue等)。
- AIO属于异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。AIO实现原理也是根据操作系统确定是哪种Provider(SolarisAsynchronousChannelProvider, LinuxAsynchronousChannelProvider...)
参考网上的学习资料,一次性从两个角度学习Linux IO,总算将所有涉及的知识以及它们的关系理清一遍,希望也能对大家也有所帮助。















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









