






博主因为工作其中的须要,開始学习 GPU 上面的编程,主要涉及到的是基于 GPU 的深度学习方面的知识。鉴于之前没有接触过 GPU 编程。因此在这里特地学习一下 GPU 上面的编程。
有志同道合的小伙伴,欢迎一起交流和学习。我的邮箱: caijinping220@gmail.com 。使用的是自己的老古董笔记本上面的 Geforce 103m 显卡,尽管显卡相对于如今主流的系列已经很的弱,可是对于学习来说。还是能够用的。本系列博文也遵从由简单到复杂,记录自己学习的过程。
0. 文件夹
- GPU 编程入门到精通(一)之 CUDA 环境安装
- GPU 编程入门到精通(二)之 执行第一个程序
- GPU 编程入门到精通(三)之 第一个 GPU 程序
- GPU 编程入门到精通(四)之 GPU 程序优化
- GPU 编程入门到精通(五)之 GPU 程序优化进阶
1. 数组平方和并行化进阶
GPU 编程入门到精通(四)之 GPU 程序优化 这篇博文中提到了 grid、block、thread 三者之间的关系。知道了他们之间是逐渐包括的关系。我们在上面的程序中通过使用 512 个线程达到了 493 倍左右的性能提升,那么是不是能够继续得到提升呢???
答案是肯定的,这就要进一步考虑 GPU 的并行化处理了。前面的程序仅仅是使用了单个 block 下的 512 个线程,那么。我们可不能够使用多个 block 来实现???
对。就是利用这个思想。达到进一步的并行化。
这里使用 8 个 block * 64 threads = 512 threads 实现。
-
首先,改动主函数宏定义。定义块数量:
// ======== define area ======== #define DATA_SIZE 1048576 // 1M #define BLOCK_NUM 8 // block num #define THREAD_NUM 64 // thread num通过在程序中加入 block 和 threads 的宏定义,这两个定义是我们在后面会用到的。他们决定了计算平方和使用的 CUDA 核心数。 -
接下来,改动内核函数:
_global__ static void squaresSum(int *data, int *sum, clock_t *time) { const int tid = threadIdx.x; const int bid = blockIdx.x; for (int i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) { tmp_sum += data[i] * data[i]; } sum[bid * THREAD_NUM + tid] = tmp_sum; }注意:这里的内存遍历方式和前面讲的是一致的。理解一下。同一时候记录的时间是一个块的開始和结束时间。由于这里我们最后须要计算的是最早開始和最晚结束的两个时间差,即求出最糟糕的时间。 -
然后。就是主函数里面的详细实现了:
// malloc space for datas in GPU cudaMalloc((void**) &sum, sizeof(int) * THREAD_NUM * BLOCK_NUM); // calculate the squares's sum squaresSum<<<BLOCK_NUM, THREAD_NUM, 0>>>(gpuData, sum, time);这里边。sum 数组的长度计算方式变化了,可是大小没有变化。另在在调用 GPU 内核函数的时候,參数发生了变化。须要告诉 GPU block 数 和 thread 数。只是这边共享内存没有使用。 -
最后,在 CPU 中计算部分和
// print result int tmp_result = 0; for (int i = 0; i < THREAD_NUM * BLOCK_NUM; ++i) { tmp_result += result[i]; }
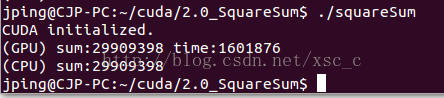
编译执行以后。得到例如以下结果:
性能与直接使用 512 个线程基本一致。由于受到 GPU 内存带宽的限制,GPU 编程入门到精通(四)之 GPU 程序优化 中的优化。已经接近极限,所以通过 block 方式,效果不明显。
2. 线程同步和共享内存
前面的程序。计算求和的工作在 CPU 中完毕。总共须要在 CPU 中做 512 次加法运算。那么有没有办法降低 CPU 中运行加法的次数呢???
能够通过同步和共享内存技术,实如今 GPU 上的 block 块内求取部分和。这样最后仅仅须要在 CPU 计算 16 个和就能够了。
详细实现方法例如以下:
-
首先,在改动内核函数,定义一块共享内存,用
__shared__指示:__global__ static void squaresSum(int *data, int *sum, clock_t *time) { // define of shared memory __shared__ int shared[BLOCK_NUM]; const int tid = threadIdx.x; const int bid = blockIdx.x; if (tid == 0) time[bid] = clock(); shared[tid] = 0; // 把部分和结果放入共享内存中 for (int i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) { shared[tid] += data[i] * data[i]; } // 同步操作。必须等之前的线程都执行结束,才干继续后面的程序 __syncthreads(); // 同步完毕之后。将部分和加到 shared[0] 上面。这里全都在一个线程内完毕 if (tid == 0) { for (int i = 1; i < THREAD_NUM; i++) { shared[0] += shared[i]; } sum[bid] = shared[0]; } if (tid == 0) time[bid + BLOCK_NUM] = clock(); }利用 __shared__ 声明的变量是 shared memory。每一个 block 中。各个 thread 之间对于共享内存是共享的。利用的是 GPU 上的内存,所以速度非常快。不必操心 latency 的问题。 __syncthreads() 函数是 CUDA 的内部函数,表示全部 threads 都必须同步到这个点。才会运行接下来的代码。我们要做的就是等待每一个 thread 计算结束以后。再来计算部分和,所以同步是不可缺少的环节。把每一个 block 的部分和计算到 shared[0] 里面。 -
接下来,改动 main 函数:
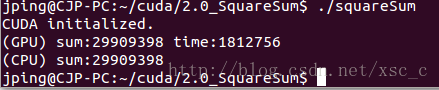
// calculate the squares's sum squaresSum<<<BLOCK_NUM, THREAD_NUM, THREAD_NUM * sizeof(int)>>>(gpuData, sum, time);编译执行后结果例如以下:
事实上和前一版程序相比,时间上没有什么优势,原因在于,我们须要在 GPU 中额外执行求和的这部分代码。导致了执行周期的变长,只是对应的,在 CPU 中的执行时间会降低。
3. 加法树
我们在这个程序中,仅仅当每一个 block 的 thread0 的时候,计算求和的工作,这样做影响了运行的效率,事实上求和能够并行化处理的,也就是通过加法树来实现并行化。举个样例,要计算 8 个数的和。我们不是必需用一个 for 循环。逐个相加。而是能够通过第一级流水线实现两两相加。变成 4 个数,第二级流水实现两两相加,变成 2 个数。第三级流水实现两两相加,求得最后的和。
以下通过加法树的方法,实现最后的求和,改动内核函数例如以下:
__global__ static void squaresSum(int *data, int *sum, clock_t *time)
{
__shared__ int shared[BLOCK_NUM];
const int tid = threadIdx.x;
const int bid = blockIdx.x;
int offset = THREAD_NUM / 2;
if (tid == 0) time[bid] = clock();
shared[tid] = 0;
for (int i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) {
shared[tid] += data[i] * data[i];
}
__syncthreads();
while (offset > 0) {
if (tid < offset) {
shared[tid] += shared[tid + offset];
}
offset >>= 1;
__syncthreads();
}
if (tid == 0) {
sum[bid] = shared[0];
time[bid + BLOCK_NUM] = clock();
}
}
此程序实现的就是上诉描写叙述的加法树的结构。注意这里第二个 __syncthreads() 的使用,也就是说,要进行下一级流水线的计算。必须建立在前一级必须已经计算完成的情况下。
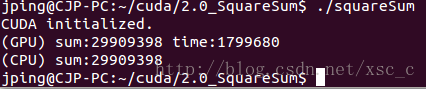
主函数部分不许要改动,最后编译执行结果例如以下:
性能有一部分的改善。
通过使用 GPU 的并行化编程。确实对性能会有非常大程度上的提升。因为受限于 Geforce 103m 的内存带宽,程序仅仅能优化到这一步,关于是否还有其它的方式优化,有待进一步学习。
4. 总结
通过这几篇博文的讨论,数组平方和的代码优化到这一阶段。
从但线程到多线程,再到共享内存,通过使用这几种 GPU 上面的结构,做到了程序的优化。例如以下给出数组平方和的完整代码:
/* *******************************************************************
##### File Name: squareSum.cu
##### File Func: calculate the sum of inputs's square
##### Author: Caijinping
##### E-mail: caijinping220@gmail.com
##### Create Time: 2014-5-7
* ********************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
// ======== define area ========
#define DATA_SIZE 1048576 // 1M
#define BLOCK_NUM 8 // block num
#define THREAD_NUM 64 // thread num
// ======== global area ========
int data[DATA_SIZE];
void printDeviceProp(const cudaDeviceProp &prop);
bool InitCUDA();
void generateData(int *data, int size);
__global__ static void squaresSum(int *data, int *sum, clock_t *time);
int main(int argc, char const *argv[])
{
// init CUDA device
if (!InitCUDA()) {
return 0;
}
printf("CUDA initialized.\n");
// generate rand datas
generateData(data, DATA_SIZE);
// malloc space for datas in GPU
int *gpuData, *sum;
clock_t *time;
cudaMalloc((void**) &gpuData, sizeof(int) * DATA_SIZE);
cudaMalloc((void**) &sum, sizeof(int) * BLOCK_NUM);
cudaMalloc((void**) &time, sizeof(clock_t) * BLOCK_NUM * 2);
cudaMemcpy(gpuData, data, sizeof(int) * DATA_SIZE, cudaMemcpyHostToDevice);
// calculate the squares's sum
squaresSum<<<BLOCK_NUM, THREAD_NUM, THREAD_NUM * sizeof(int)>>>(gpuData, sum, time);
// copy the result from GPU to HOST
int result[BLOCK_NUM];
clock_t time_used[BLOCK_NUM * 2];
cudaMemcpy(&result, sum, sizeof(int) * BLOCK_NUM, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_used, time, sizeof(clock_t) * BLOCK_NUM * 2, cudaMemcpyDeviceToHost);
// free GPU spaces
cudaFree(gpuData);
cudaFree(sum);
cudaFree(time);
// print result
int tmp_result = 0;
for (int i = 0; i < BLOCK_NUM; ++i) {
tmp_result += result[i];
}
clock_t min_start, max_end;
min_start = time_used[0];
max_end = time_used[BLOCK_NUM];
for (int i = 1; i < BLOCK_NUM; ++i) {
if (min_start > time_used[i]) min_start = time_used[i];
if (max_end < time_used[i + BLOCK_NUM]) max_end = time_used[i + BLOCK_NUM];
}
printf("(GPU) sum:%d time:%ld\n", tmp_result, max_end - min_start);
// CPU calculate
tmp_result = 0;
for (int i = 0; i < DATA_SIZE; ++i) {
tmp_result += data[i] * data[i];
}
printf("(CPU) sum:%d\n", tmp_result);
return 0;
}
__global__ static void squaresSum(int *data, int *sum, clock_t *time)
{
__shared__ int shared[BLOCK_NUM];
const int tid = threadIdx.x;
const int bid = blockIdx.x;
int offset = THREAD_NUM / 2;
if (tid == 0) time[bid] = clock();
shared[tid] = 0;
for (int i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) {
shared[tid] += data[i] * data[i];
}
__syncthreads();
while (offset > 0) {
if (tid < offset) {
shared[tid] += shared[tid + offset];
}
offset >>= 1;
__syncthreads();
}
if (tid == 0) {
sum[bid] = shared[0];
time[bid + BLOCK_NUM] = clock();
}
}
// ======== used to generate rand datas ========
void generateData(int *data, int size)
{
for (int i = 0; i < size; ++i) {
data[i] = rand() % 10;
}
}
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
bool InitCUDA()
{
//used to count the device numbers
int count;
// get the cuda device count
cudaGetDeviceCount(&count);
if (count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
// find the device >= 1.X
int i;
for (i = 0; i < count; ++i) {
cudaDeviceProp prop;
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= 1) {
//printDeviceProp(prop);
break;
}
}
}
// if can't find the device
if (i == count) {
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
// set cuda device
cudaSetDevice(i);
return true;
}
欢迎大家和我一起讨论和学习 GPU 编程。
caijinping220@gmail.com
http://blog.csdn.net/xsc_c
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









