







 本文介绍了支持向量机SVM的基本思想,包括寻找最优分类面以最大化间隔,以及通过非线性变换解决线性不可分问题。支持向量机的关键在于参数选择,文中提到了libSVM库的使用,包括参数检查、多类分类、模型保存与预测等功能。建议的使用步骤涉及数据预处理、选择核函数和参数调整。推荐首选径向基核函数,并通过交叉验证来优化参数C和r。libSVM提供了c/c++接口,支持多种核函数,适用于非专业人士使用。
本文介绍了支持向量机SVM的基本思想,包括寻找最优分类面以最大化间隔,以及通过非线性变换解决线性不可分问题。支持向量机的关键在于参数选择,文中提到了libSVM库的使用,包括参数检查、多类分类、模型保存与预测等功能。建议的使用步骤涉及数据预处理、选择核函数和参数调整。推荐首选径向基核函数,并通过交叉验证来优化参数C和r。libSVM提供了c/c++接口,支持多种核函数,适用于非专业人士使用。
http://ju.outofmemory.cn/entry/119152
http://www.cnblogs.com/zhizhan/p/4412343.html
支持向量机SVM是从线性可分情况下的最优分类面提出的。所谓最优分类,就是要求分类线不但能够将两类无错误的分开,而且两类之间的分类间隔最大,前者是保证经验风险最小(为0),而通过后面的讨论我们看到,使分类间隔最大实际上就是使得推广性中的置信范围最小。推广到高维空间,最优分类线就成为最优分类面。
支持向量机是利用分类间隔的思想进行训练的,它依赖于对数据的预处理,即,在更高维的空间表达原始模式。通过适当的到一个足够高维的非线性映射  ,分别属于两类的原始数据就能够被一个超平面来分隔。如下图所示:
,分别属于两类的原始数据就能够被一个超平面来分隔。如下图所示:

空心点和实心点分别代表两个不同的类,H为将两类没有错误的区分开的分类面,同时,它也是一个最优的分类面。原因正如前面所述,当以H为分类面时,分类间隔最大,误差最小。而这里的  之间的距离margin就是两类之间的分类间隔。支持向量机将数据从原始空间映射到高维空间的目的就是找到一个最优的分类面从而使得分类间隔margin最大。而那些定义最优分类超平面的训练样本,也就是上图中过 的空心点和实心点,就是支持向量机理论中所说的支持向量。显然,所谓支持向量其实就是最难被分类的那些向量,然而,从另一个角度来看,它们同时也是对求解分类任务最有价值的模式。
之间的距离margin就是两类之间的分类间隔。支持向量机将数据从原始空间映射到高维空间的目的就是找到一个最优的分类面从而使得分类间隔margin最大。而那些定义最优分类超平面的训练样本,也就是上图中过 的空心点和实心点,就是支持向量机理论中所说的支持向量。显然,所谓支持向量其实就是最难被分类的那些向量,然而,从另一个角度来看,它们同时也是对求解分类任务最有价值的模式。
支持向量机的基本思想可以概括为:首先通过非线性变换将输入空间变换到一个高维空间,然后在这个新空间中求取最优线性分类面,而这种非线性变换是通过定义适当的内积函数来实现的。支持向量机求得的分类函数形式上类似于一个神经网络,其输出是若干中间层节点的线性组合,而每一个中间层节点对应于输入样本与一个支持向量的内积,因此也被叫做支持向量网络。如下图所示:

由于最终的判别函数中实际只包含于支持向量的内积和求和,因此判别分类的计算复杂度取决于支持向量的个数。
不难发现,支持向量机作为统计学习理论中的经典代表使用了与传统方法完全不同的思路,即不是像传统方法那样首先试图将原输入空间降维(即特征选择和特征变换),而是设法将输入空间升维,以求在高维空间中问题变得线性可分或接近线性可分。因为升维知识改变了内积运算,并没有使得算法的复杂性随着维数的增加而增加,而且在高维空间中的推广能力并不受到维数的影响。
另外,需要说明的是,支持向量机采用不同的内积函数,将导致不同的支持向量机算法
目前得到研究的内积函数主要有以下三类:
(1)采用多项式形式的内积函数;
(2)采用核函数形式的内积函数;
(3)采用S形函数作为内积函数;
libSVM是台湾大学林智仁教授等研究人员开发的一个用于支持向量机分类,回归分析及分布估计的c/c++开源库。另外,它也可以用于解决多类分类问题。 libSVM最新的版本是2011年4月发布的3.1版。林智仁教授设计开发该SVM库的目的是为了让其它非专业人士可以更加方便快捷的使用SVM这个统计学习工具。libSVM提供了一些简单易用的接口,从而使得用户可以方便的使用,而不必关心其内部复杂的数学模型和运算过程。libSVM的主要特点有:
(1)各种SVM的表达公式;
(2)有效的多类分类能力;
(3)交叉验证功能;
(4)各种核函数,包括预先计算得到的核矩阵;
(5)用于非平衡数据的加权svm;
(6)提供c++和java源代码;
(7)用于演示SVM分类与回归能力的GUI界面;
.....
很多初学者往往按照以下的步骤使用libSVM:
(1)将数据转换到libSVM指定的格式;
(2)随机选择一个核函数和一些参数;
(3)测试;
这种方法虽然可行,但却不一定能很快达到好的效果。为此,林智仁教授推荐按照以下的步骤来使用libSVM:
(1)将数据转换到libSVM指定的格式;
(2)对数据进行尺度操作(一般指数据的归一化);
(3)考虑RBF(径向基)核函数;
(4)利用交叉验证来得到最好的参数C和r;
(5)用最好的C和r来训练所有训练集合;
(6)测试;
之所以推荐首选径向基核函数,是由于该核可以将数据非线性地映射到高维空间,而且,它还能处理那种特征(数据)及其属性之间呈现非线性关系的情况,而线性核函数只是径向基核函数的一个特例。另外,相比而言,多项式核函数在高维空间有着更多的参数,从而使得模型更加复杂。同时,需要提醒的是,径向基核函数并非万能的,尤其当特征数据的数值本身比较大的时候,线性核函数要更实用一些。
任何人可以在http://www.csie.ntu.edu.tw/~cjlin/libsvm 来下载libSVM开源库。不过,按照开发者的要求,在使用之前,请务必阅读其copyright,并按照其要求进行相应的引用和说明。另外,在使用之前,强烈推荐大家阅读libSVM.zip里面的readme文件。该文件详细描述了libSVM的使用方法及注意事项。
libSVM介绍
鉴于libSVM中的readme文件有点长,而且,都是采用英文书写,这里,我把其中重要的内容提炼出来,并给出相应的例子来说明其用法,大家可以直接参考我的代码来调用libSVM库。
第一部分,利用libSVM自带的简易工具来演示SVM的两类分类过程。
(以下内容只是利用libSVM自带的一个简易的工具供大家更好的理解SVM,如果你对SVM已经有了一定的了解,可以直接跳过这部分内容)
首先,你要了解的是libSVM只是众多SVM实现版本中的其中之一。而SVM是一种进行两类分类的分类器,在libSVM最新版(libSVM3.1)里面,已经自带了简单的工具,可以对二分类进行演示。以windows平台为例,将libSVM.zip解压之后,有一个名为windows的子文件夹,里面有一个名为svm-toy.exe的可执行文件。直接双击,运行该可执行文件,显示如下的界面
点击第二个按钮“Run”,然后,在左上部分,用鼠标左键随机点几下,代表你选择的第一类模式的数据分布,下图是我随即点了几下的结果:

之后,点击“Change”,接着,用鼠标左键在窗口右下方随便点击几下,代表你选择的第二类模式的数据分布,如下图所示:
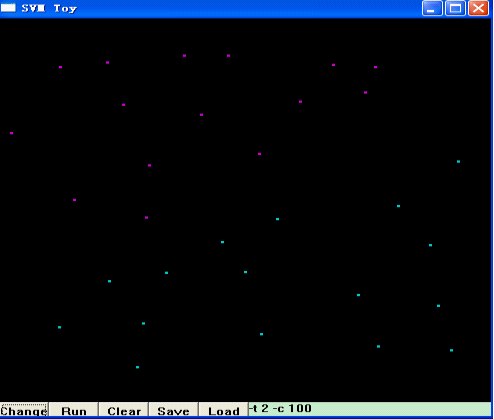
接着,点击“Run”,libSVM就帮你把这两类模式分开了,并用两种不同的颜色区域来代表两类不同的模式,如下图所示:

图中左上方紫色的区域,是第一类模式所在的区域,右下方的蓝色区域,是你选择的第二类模式所在的的区域,而两者的分界面,也就是SVM的最优分类面。当然,SVM是通过核函数将原始数据映射到高维空间,在高维空间进行线性分类。换句话说,在高维空间,这两类数据应该是线性可分的,即:最优分类面应该是一条直线,而这里看到的,是将高维空间分类的结果又映射回原始空间所呈现的分类结果,即:非线性的分类面。细心的朋友可能已经发现,在上述界面的右下角,有一个编辑框,里面写着“-t 2 -c 100”,显然,这是libSVM的一些参数,你也可以试着更改这些参数,来选择不同的核函数、不同的SVM类型等来达到最好的分类效果。
第二部分:libSVM中的小工具
libSVM中包含以下可执行程序文件(小工具):
(1)svm-scale:一个用于对输入数据进行归一化的简易工具
(2)svm-toy:一个带有图形界面的交互式SVM二分类功能演示小工具;
(3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









