







人一生经历的肯定要比大脑记住的要多, 即便是这样, 记住的东西用十年百年也说不完, 人的记忆是不是基于统计的呢?
T: Universal Reinforcement Learning Algorithms Survey and Experiments
P: 关于 Universal Reinforcement Learning (URL) 的多 Agent, 对单 agent 是 POMDP 的序贯决策问题不对环境做出假设 makeas few assumptions as possible about the environment:
Dartmouth Conference
符合条件的有AIXI
AIXI is a theoretical mathematical formalism for artificial general intelligence. It combines Solomonoff induction with sequential decision theory. AIXI was first proposed by Marcus Hutter in 2000 and the results below are proved in Hutter's 2005 book Universal Artificial Intelligence.
AIXI: RL Agent
它最大限度地提高了从环境中获得的预期总收益。
step1. 它同时考虑每个可计算的假设
step2. 在每个时间步骤中,它会查看每个可能的程序,并根据下一步采取的行动评估程序生成的奖励数。
step3. 许可的奖励将以主观认为该计划构成真实环境的方式加权
Belief 是从程序的长度计算的: 较长的程序被认为是不太可能,符合奥卡姆的剃须刀。
step4. AIXI选择所有这些程序的加权总和中具有最高预期总奖励的动作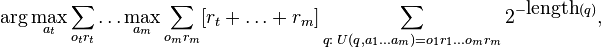
AIXI 假设这个世界是可计算逼近的:
对任意pattern(误差d) 存在算法f(x): 当 x>r(r为特定常数) 时, f(x)能逼近 range(pattern)±d 范围 (渐近最优)
Pareto 最优 (Pareto optimality): 不存在 Agents 在任何一个环境表现都不比AIXI差, 并且能在某个环境中表现比 AIXI (严格)好
平衡 Pareto 最优性 (考虑到环境的加权和?, 主观)
自我优化(Self-optimizing): 自我优化策略π: life(Agent) →∞, π→ argmax u; 在存在自优化策略的一类环境中, AIXI是自优化的。
AIXI限制: 限于根据感知最大化奖励而不是外部状态。它还假定它仅通过行动和感知渠道与环境相互作用,阻止它考虑被损坏或修改的可能性。它也假设环境是可计算的, 但AIXI是不可计算的, 它不认为自己被与它相互作用的环境所包含:
它为自己的存在赋予零概率
AIXI近似
1. AIXItl,其执行作为至少还有可证明最佳时间 t 和空间l有限Agent;
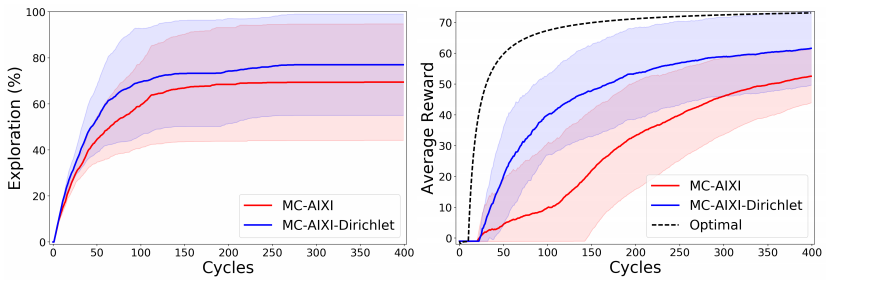
2. MC-AIXI(FAC-CTW),它在一些简单的游戏中(部分可观察的 Pac-Man) 可行
在任何确定世界, 世界的所有后续状态由其历史唯一决定, 那之中的人用算法概率来预测未来, 虽说他们能够预测, 但从不敢采取任何行为去改变其所在的世界.
Solomonoff(通用归纳) 算法概率
M(x):=\sum_{p:U(p)=x*}^{}{2^{-l(p)} }
------------
POMDP:
A partially observable Markov decision process (POMDP) is a generalization of a Markov decision process (MDP). A POMDP models an agent decision process in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state. Instead, it must maintain a probability distribution over the set of possible states, based on a set of observations and observation probabilities, and the underlying MDP.
一个MDP的环境,但是Agent本身是不能观测到其全部的(不完全可观察)
POMDP 《S, A, Ω, T, O, R, γ, b》
状态空间: S ∈ Real^Num
动作空间: A 有限
观察空间: Ω
转移函数: T := S×A×S → Real[0, 1], T(s, a, s′) = p(s′ |s, a) 表示Agent在状态s下执行动作a后得到状态s′的概率;
观察函数: O := A×S×Ω → Real[0, 1], O(a, s′, z) = p(w |a, s′) 表示Agent在执行动作a后到达状态s′时得到观察z的概率;
回报函数: R := S×A→R, R(s, a) 表示Agent在状态s下执行动作a所得到的即时奖赏值.
折扣因子: γ ∈ Real(0, 1), 用来弱化未来得到的奖赏. 确保了收敛性
觉状态: b := 状态集S上的一个概率分布, 所有信念状态: |S|维 单形体 ∆.
b0 b0(s)=Pr(s0=s) 是在时间t=0时在状态集S上的概率分布
状态不能被直接观察,因此为了执行最优的动作,Agent必须维护一个所经历动作和观察的完整序列,即历史.历史可以用觉状态来取代,
环境 与 Agent 交互 Loop:
step1. 系统状态为 s ∈ S, Agent动作 a ∈ A, 于是获得回报 R(s,a);
step2. 系统状态为 s' 按照 T(s, a, s'), Agent 按照观察分布 O(a,s′,z) 获取一个观察 z∈Z, 提供了隐蔽状态s′的信息 POMDP规划的目标是找一个选择动作的策略π,它最大化折扣奖赏的期望值:
V[π](b[0]) = E(∑[t = 0:inf](γ^t * r[t]))
b'(s') = b[a,z](s') : p(s'|b, a, z) = ( O(a, s', ) * ∑ [s∈S](b(s) * T(s, a, s')) ) / p(z|a, b) (1) Bayes
V[0](b) = max[a∈A](R(b, a))V[*](b) = max[a∈A](R(b, a) + γ *(∑ [s∈S](p(z |a, b) * V[*](b[a,z]) )
V 分段线性凸超平面集Γ
值函数被初始化为一个α-向量
如果存在过神明的话,那她最后的工作就是抹消了自己的一切,并把整个自然托付给她信任的我们了吧。
这就是传说的开始,和我们的辉煌现在,至于未来,没有人会注意也不能够看到了。
渐近最优算法或行为在最坏的情况下比最好的只差一个固定的错觉(不可避免的)
µ[π]( lim[n→∞](1/n * ∑[ t=1:n] (V[µ, *](æ[<t]) - V[µ, π](æ[<t]))= 0) = 1
ε-Effective horizon
H[γ, t](ε) := min(H: (Γ[γ, t+H] / Γ[γ, t] ≤ ε)
终止计划实现收益
------------
Bayes agent AIξ
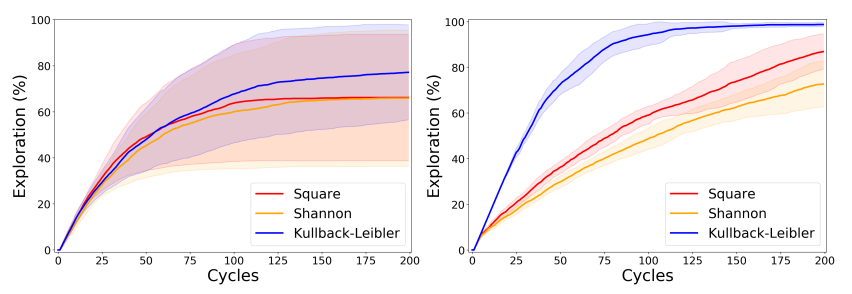
KSA(Knowledge-seeking agents)
未超越 ε-greedy exploration
取消外部依赖(外部reward), utility func. epr-epi -> epr
KL-KSA(Kullback-Leibler Knowledge-seeking agents)
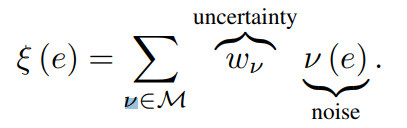
SS-KSA(Square & Shannon Knowledge-seeking agents)
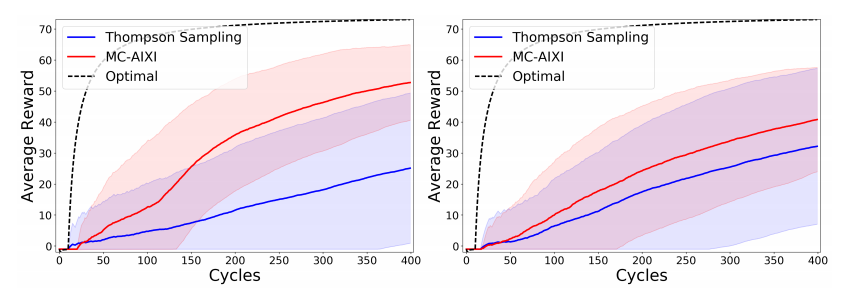
Thompson sampling
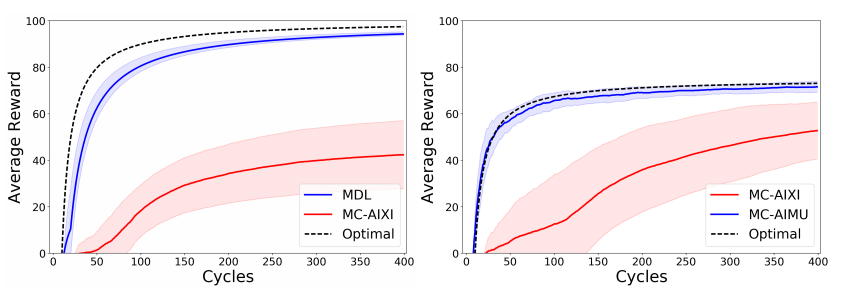
The minimum description length
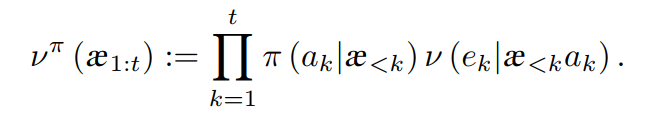
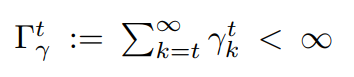
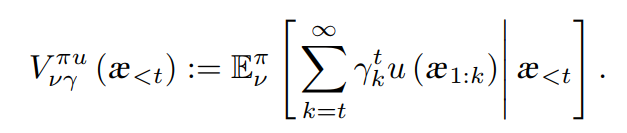
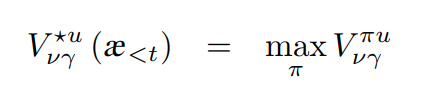
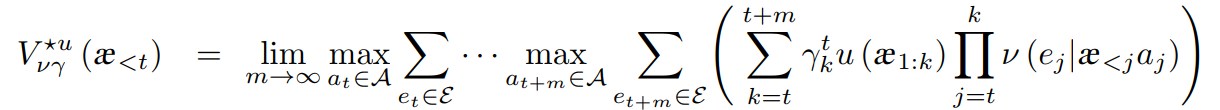
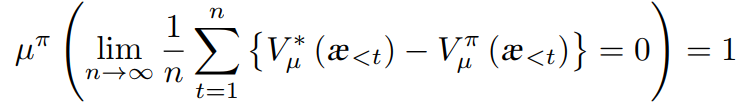
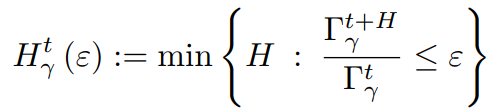
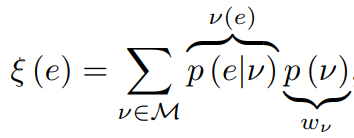
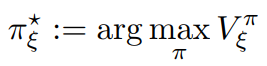
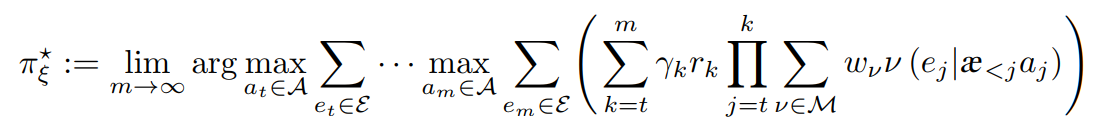
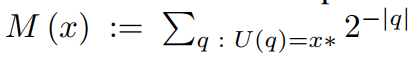

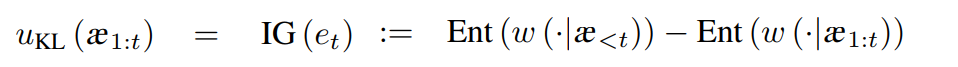




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









