







回归问题的条件/前提:
1) 收集的数据
2) 假设的模型,即一个函数,这个函数里含有未知的参数,通过学习,可以估计出参数。然后利用这个模型去预测/分类新的数据。
1. 线性回归
假设 特征 和 结果 都满足线性。即不大于一次方。这个是针对 收集的数据而言。
收集的数据中,每一个分量,就可以看做一个特征数据。每个特征至少对应一个未知的参数。这样就形成了一个线性模型函数,向量表示形式:
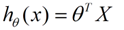
这个就是一个组合问题,已知一些数据,如何求里面的未知参数,给出一个最优解。 一个线性矩阵方程,直接求解,很可能无法直接求解。有唯一解的数据集,微乎其微。
基本上都是解不存在的超定方程组。因此,需要退一步,将参数求解问题,转化为求最小误差问题,求出一个最接近的解,这就是一个松弛求解。
求一个最接近解,直观上,就能想到,误差最小的表达形式。仍然是一个含未知参数的线性模型,一堆观测数据,其模型与数据的误差最小的形式,模型与数据差的平方和最小:

这就是损失函数的来源。接下来,就是求解这个函数的方法,有最小二乘法,梯度下降法。
http://zh.wikipedia.org/wiki/%E7%BA%BF%E6%80%A7%E6%96%B9%E7%A8%8B%E7%BB%84
最小二乘法
是一个直接的数学求解公式,不过它要求X是列满秩的,
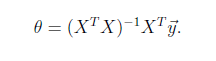
梯度下降法
分别有梯度下降法,批梯度下降法,增量梯度下降。本质上,都是偏导数,步长/最佳学习率,更新,收敛的问题。这个算法只是最优化原理中的一个普通的方法,可以结合最优化原理来学,就容易理解了。
在现实生活中普遍存在着变量之间的关系,有确定的和非确定的。确定关系指的是变量之间可以使用函数关系式表示,还有一种是属于非确定的(相关),比如人的身高和体重,一样的身高体重是不一样的。
线性回归:
(1): 函数模型(Model):
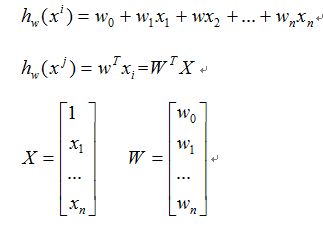
假设有训练数据
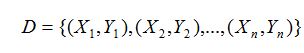
那么为了方便我们写成矩阵的形式
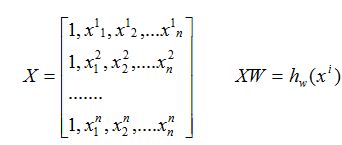
(2): 损失函数(cost):
现在我们需要根据给定的X求解W的值,这里采用最小二乘法。
a.最小二乘法:
何为最小二乘法,其实很简单。我们有很多的给定点,这时候我们需要找出一条线去拟合它,那么我先假设这个线的方程,然后把数据点代入假设的方程得到观测值,求使得实际值与观测值相减的平方和最小的参数。对变量求偏导联立便可求。
因此损失代价函数为:
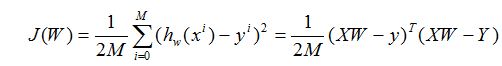
(3): 算法(algorithm):
现在我们的目的就是求解出一个使得代价函数最小的W:
a.矩阵满秩可求解时(求导等于0):
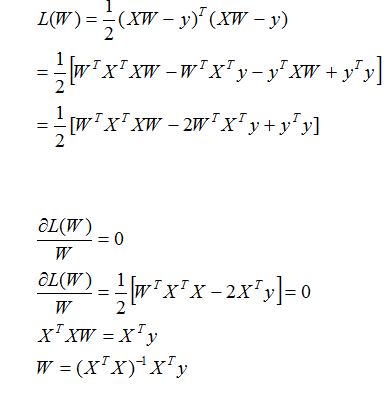
b.矩阵不满秩时(梯度下降):
梯度下降算法是一种求局部最优解的方法,对于F(x),在a点的梯度是F(x)增长最快的方向,那么它的相反方向则是该点下降最快的方向,具体参考wikipedia。
原理:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快;
注意:当变量之间大小相差很大时,应该先将他们做处理,使得他们的值在同一个范围,这样比较准确。
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
描述一下梯度减少的过程,对于我们的函数J(θ)求偏导J:
Repeat until convergence:{

下面是更新的过程,也就是θi会向着梯度最小的方向进行减少。θi表示更新之前的值,-后面的部分表示按梯度方向减少的量,α表示步长,也就是每次按照梯度减少的方向变化多少。

假设有数据集D时:
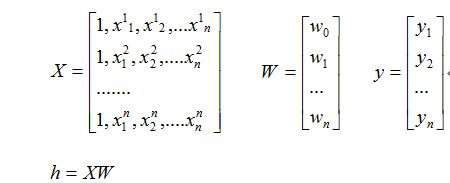
对损失函数求偏
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7283
7283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









