







Spark excels at processing in-memory data. We are going to look at various caching options and their effects, and (hopefully) provide some tips for optimizing Spark memory caching.
When caching in Spark, there are two options
1. Raw storage
2. Serialized
Here are some differences between the two options
Raw caching | Serialized Caching |
| Pretty fast to process | Slower processing than raw caching |
| Can take up 2x-4x more spaceFor example, 100MB data cached could consume 350MB memory | Overhead is minimal |
| can put pressure in JVM and JVM garbage collection | less pressure |
usage:rdd.persist(StorageLevel.MEMORY_ONLY) or rdd.cache() | usage:rdd.persist(StorageLevel.MEMORY_ONLY_SER |
So what are the trade offs?
Here is a quick experiment. I cache a bunch of RDDs using both options and measure memory footprint and processing time. My RDDs range in size from 100MB to 1GB.
Testing environment:
3 node spark cluster running on Amazon EC2 (m1.large type with 8G memory per node)
Reading data files from S3 bucket
Testing method:
$ ./bin/spark-shell --driver-memory 8g
> val f = sc.textFile("s3n://bucket_path/1G.data")
> f.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY) // specify the cache option
> f.count() // do this a few times and measure times
// also look at RDD memory size from Spark application UI, under 'Storage' tabOn to the results:
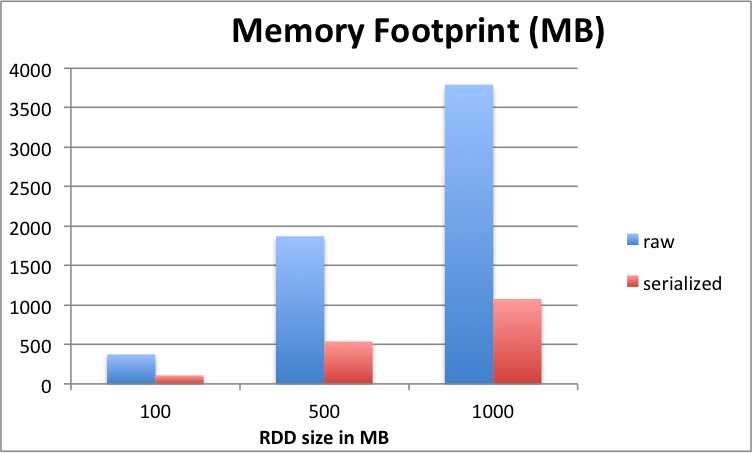
| Data Size | 100M | 500M | 1000M (1G) | |
| Memory Footprint (MB) | ||||
| raw | 373.8 | 1,869.20 | 3788.8 | |
| serialized | 107.5 | 537.6 | 1075.1 | |
| count() time (ms) | ||||
| cached raw | 90 ms | 130 ms | 178 ms | |
| cached serialized | 610 ms | 1,802 ms | 3,448 ms | |
| before caching | 3,220 ms | 27,063 ms | 105,618 ms |

Conclusions
raw caching consumes has a bigger footprint in in memory – about 2x – 4x (e.g. 100MB RDD becomes 370MB)
Serialized caching consumes almost the same amount of memory as RDD (plus some overhead)
Raw cache is very fast to process, and it scales pretty well
Processing serialized cached data takes longer
So what does all this mean?
For small data sets (few hundred megs) we can use raw caching. Even though this will consume more memory, the small size won’t put too much pressure on Java garbage collection.
Raw caching is also good for iterative work loads (say we are doing a bunch of iterations over data). Because the processing is very fast
For medium / large data sets (10s of Gigs or 100s of Gigs) serialized caching would be helpful. Because this will not consume too much memory. And garbage collecting gigs of memory can be taxing















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









