







第六章 面向对象编程
通过提供一个object数据类型和一些用于处理对象的函数,Lisp-Stat支持面向对象编程。在第二章里,我们看到Lisp-Stat绘图和模型是用对象实现的,我们使用一些消息来检测和修改这些对象。本章将更加深入地描述Lisp-Stat对象系统。该系统专门设计用来处理交互统计工作,与Lisp社区里使用的其它对象系统有些不同,其它的对象系统将在第6.7节里简要讨论。
6.1 一些动机
假设我们想要建立一个智能函数用来描述或者绘制一个数据集。最初,我们可以考虑三个数据类型:单样本、多样本和成对样本。那么describe-data函数可以编写成这样:
(defun describe-data (data)
(cond
((single-sample-p data) ...)
((multiple-sample-p data) ...)
((paired-sample-p data) ...)
(t (error "don't know how to describe this data set"))))假设后来我们决定想要处理数据集的第四个数据类型,一个简单的时间序列。为了容纳这个新的数据类型,我们不得不编辑describe-data函数和plot-data函数。这就有几个缺陷了,首先,我们需要会的并能够理解这些函数的源代码,这在当前这个小例子里不是个问题,但是在处理更复杂的设置的时候会制造很大的困难。其次,仅仅为了达到增加处理新数据类型的能力而编辑源代码,我们要承担处理现有数据类型是代码中断的风险。
一个备选策略是去安排数据集本身去了解如何描述自己,换句话说,能够获得合适的代码段已打印对于自身的描述。那么describe-data函数只不过让数据集去找出合适的代码段并执行之。增加数据集的一个新的类型不需要对describe-data函数进行任何修改,也不需要对处理现有数据类型的代码做任何修改;我们仅需要针对新的数据类型编写和安装合适的代码。这是面向对象编程方法背后的一个主要的思想。定位和执行合适的代码段的请求过程叫做消息传递。代码段本书就是消息的方法调用。
面向对象编程的另一个关键思想是继承。一个对象的新类型与现存对象在细节上的区别可能很小。例如,一个时间序列可能需要它自己的描述方法,但是可能可以使用相同的绘图方法作为配对样本。为了发挥这个相似性的最大优势,我们可以在一个阶层里安排一个对象,同时每个对象都从这个对象继承,它是它们的祖先。那么如果一个对象没有它自己的方法,处理消息的系统就会被引导去使用其祖先的方法。那么,当我们开发一个新对象,如果没有可用的继承方法或者继承的方法不适合的时候,我们仅需要提供一个新的方法就可以了。这种重用现有代码的能力在减少设计新对象所需要的时间上将减少一个数量级。通过确保被很多对象使用的方法之间自动地传递消息的改进,同样可以方便代码维护。
6.2 对象和消息
6.2.1 基础结构和术语
Lisp-Stat对象是为面向对象编程专门设计的独立的数据类型。通过使用objectp谓词,你可以确认一个数据项是不是对象。
一个对象是一个数据结构,它在所谓的slots的指定位置包含对象的信息。在这方面,它与C或者S结构体是相似的。另外在处理数据方面,对象可以应答消息,让他们做一定的动作。在形如以下格式的表达式里,消息使用函数send发送给对象:(send <object> <selector> <arg 1> ... <arg n>)。
<selector>是一个符号,通常是一个关键字符号,用来识别一个消息。举个例子,假设变量p指的是第二章里介绍的那个histogram函数返回的一个直方图对象,那么表达式(send p :add-points (normal-rand 20))向直方图发送一个消息,让它向自己加入一个有20个标准随机分布变量的样本,消息对应的message selector是:add-points;消息的参数是由表达式(normal-rand 20)产生的正态变量的样本。消息由选择器和参数组成。用来响应这个消息代码就是针对消息的方法。通过向对象和消息选择器分发(dispatching),send函数会找出那个合适的方法。
对象在一个继承的层次里被组织起来。在这个层次里的顶层是根对象,就是全局变量*object*的值。这个对象包含一些方法,用来对所有对象使用一些标准消息。例如,消息:own-slots返回一个对象里的用来命名槽的符号列表。根对象里的槽是:
> (send *object* :own-slots)
(DOCUMENTATION PROTO-NAME INSTANCE-SLOTS)
> (send *object* :slot-value 'proto-name)
*OBJECT*
> (send *object* :slot-value 'instance-slots)
NIL 根对象是一个原型对象,设计根对象是用来充当一个构造其它对象的模板,也叫做原型的实例。槽proto-name包含一个命名这个原型的符号,该槽的值在产生一个对象的打印体表示时被用到:
> *object*
#<Object: 145d040, prototype = *OBJECT*> 当对象发送一个消息时,它首先检查它自己是否有一个处理该消息的方法。如果它自己有,它就用这个方法。否则,它将遍历它的祖先直到找到该方法。如果没有找到这样的一个方法,将发送一个错误。在确定一个槽的值的时候,也是用了相同的处理过程:首先,对象检测自己的槽,然后是其祖先的槽。这里对象的租箱被检查的顺序叫做对象的优先级列表。这个优先级列表通常包含对象本身作为第一个元素,包含根对象作为最后一个元素。在本节的这个简单的例子里,可以认为每个对象仅有一个直接祖先,或者叫父类。本例中,优先级列表是由该对象、该对象的父对象、父对象的父对象、等等,直到根对象位置。更加复杂的例子将在后标的第6.6节中讨论。
6.2.2 构造新的对象
新的对象通常通过向一个原型第一项里发送:new消息来构造。这个消息需要的参数的数量由原型来决定;对于根节点,它不需要参数。举个例子,我们可以使用以下表达式来构造一个表示一个数据集的对象:
> (setf x (send *object* :new))
#<Object: 147e0bc, prototype = *OBJECT*>> (send x :own-slots)
NIL> (send x :add-slot 'data (normal-rand 50))
(-0.961671261245195 -0.03073969289405536 1.5577613346793322 0.5292481826230735 -0.3462433415969322 0.8429198212376022 0.8955459122132918 -0.6722222042240655 -0.2258089379905481 -0.7424918965036337 -0.7065091306089195 1.4569458955136176 1.8034388173374396 -1.0011915353362055 -1.1439767529393954 0.23075866234223663 -0.04478652198931416 -0.6938743027004384 0.27549371131380973 -0.12461730393232302 0.9154031052901357 -0.7901457891598227 -1.0528183854817184 -0.1611916129413438 -0.5570674445463484 2.026709492605648 -1.8321937303176188 -0.057280152706097424 0.14707120651936426 1.6974462077365668 1.114021890943337 0.4157649206799311 1.0151465340915484 -1.1710331835472994 1.151784316238704 -1.350950765281483 -1.0910310770474871 2.659543772302781 1.5208132663438354 0.026963615535911336 0.6286342472708142 -1.6753192017970124 -0.7329778544654284 -1.66605746948027 -1.477241171430288 -0.6115453732205446 0.047807107535505836 0.2553196181944672 0.6777721882239728 0.1643399828719198)
> (send x :add-slot 'title)
NIL
> (send x :own-slots)
(TITLE DATA)> (send x :slot-value 'data)
(-0.961671261245195 -0.03073969289405536 1.5577613346793322 0.5292481826230735 -0.3462433415969322 0.8429198212376022 0.8955459122132918 -0.6722222042240655 -0.2258089379905481 -0.7424918965036337 -0.7065091306089195 1.4569458955136176 1.8034388173374396 -1.0011915353362055 -1.1439767529393954 0.23075866234223663 -0.04478652198931416 -0.6938743027004384 0.27549371131380973 -0.12461730393232302 0.9154031052901357 -0.7901457891598227 -1.0528183854817184 -0.1611916129413438 -0.5570674445463484 2.026709492605648 -1.8321937303176188 -0.057280152706097424 0.14707120651936426 1.6974462077365668 1.114021890943337 0.4157649206799311 1.0151465340915484 -1.1710331835472994 1.151784316238704 -1.350950765281483 -1.0910310770474871 2.659543772302781 1.5208132663438354 0.026963615535911336 0.6286342472708142 -1.6753192017970124 -0.7329778544654284 -1.66605746948027 -1.477241171430288 -0.6115453732205446 0.047807107535505836 0.2553196181944672 0.6777721882239728 0.1643399828719198)
> (send x :slot-value 'title)
NIL> (send x :slot-value 'title "a data set")
"a data set"
> (send x :slot-value 'title)
"a data set"除了它自己的槽,对象x也能获取被它继承的或者共享的根对象的槽:
> (send x :slot-value 'proto-name)
*OBJECT*> (send x :slot-names)
(TITLE DATA DOCUMENTATION PROTO-NAME INSTANCE-SLOTS)> (send x :has-slot 'title)
T
> (send x :has-slot 'x)
NIL
> (send x :has-slot 'proto-name)
T> (send x :has-slot 'title :own t)
T
> (send x :has-slot 'proto-name :own t)
NIL一个槽是属于一个对象所有,还是从其他对象继承而来仅在我们想要删除该槽或者改变槽的值的时候才是重要的。通过发送一个合适的消息给槽的所有者,你仅能删除该槽或者改变该槽的值。要求一个对象改变一个继承的槽的值会引发一个错误。例如:
> (send x :slot-value 'proto-name 'new-name)
Error: object does not own slot - PROTO-NAME
Happened in: #<Byte-Code-Closure-SLOT-VALUE: #149d2b0>略。
6.2.3 定义新的方法
初始情况下,一个对象可以应答一些标准消息,就像我们用过的一样。针对这些消息的方法是从根对象继承而来的。就像在第2.7节里简要概述过得一样,通过使用defmeth宏可以为一个对象定义新的方法。defmeth表达式看起来像这样:(defmeth <object> <selector> <parameters> <body>)。参数<object>应该是一个可以求值成对象的表达式,其余的参数不会被求值,<parameters>是命名方法的参数的符号的列表。参数列表里可以包括&key、&optional和&rest类型的参数。如果方法体是由字符串开始的,那个字符串将被看作为一个文档字符串,并且被安装供:help消息使用。
在为一个消息写一个方法时,你通常需要能够引用到接收消息的那个对象。因为方法是可以被继承的,你无法确认一个对象被写的时候接收对象的身份。为了解决这个问题,对象系统确保当方法体被求值时,变量self是与接收消息的对象是绑定的。举个例子,通过使用以下定义,针对:discribe消息,我们可以给定数据集一个方法:
> (defmeth x :describe (&optional (stream t))
(format stream "This is ~a~%"
(send self :slot-value 'title))
(format stream "The sample mean is ~g~%"
(mean (send self :slot-value 'data)))
(format stream "The sample standard deviation is ~g~%"
(standard-deviation
(send self :slot-value 'data))))
:DESCRIBE> (send x :describe)
This is a data set
The sample mean is 2.271335432522105E-2
The sample standard deviation is 1.0647789521240567
NIL变量self可以被视为对一个方法的强制的首参数。它可以针对关键字参数和可选参数,被用在默认表达式中。如果在方法里建立了一个函数闭包,绑定到正在接收消息的对象上的变量self是被包含在闭包的环境中的。
有一些函数,它们仅能在方法体内部使用。一个这样的函数就是slot-value,这个函数带一个参数,一个命名当前对象里的槽的符号,返回这个槽的值。在一个方法体里,你也可以使用slot-value函数作为setf函数的要设置的位置。使用slot-value函数而不是:slot-value消息通常会产生较快的代码;:slot-value消息主要的意图是从解释器里检测对象,那里slot-value函数是不能使用的。使用这个函数,我们可以将我们自己的函数定义如下:
> (defmeth x :describe (&optional (stream t))
(format stream "This is ~a~%" (slot-value 'title))
(format stream "The sample mean is ~g~%"
(mean (slot-value 'data)))
(format stream "The sample standard deviation is ~g~%"
(standard-deviation (slot-value 'data))))
:DESCRIBE这种定义的一个缺点就是,通过明确地假设:数据和标题是通过这些名字储存在槽里这一事实,该定义将我们与我们的数据集的一种特定的实现拴在了一起。更灵活的方法,是由数据抽象原则激发的,就是去定义一个读取方法来获取和修改标题和数据,比如这样:
(defmeth x :title (&optional (title nil set))
(if set (setf (slot-value 'title) title))
(slot-value 'title))还有
(defmeth x :data (&optional (data nil set))
(if set (setf (solt-value 'data) data))
(slot-value 'data))(defmeth x :describe (&optional (stream t))
(let ((title (send self :title))
(data (send self :data)))
(format stream "This is ~a~%" title)
(format stream "The sample mean is ~g~%" (mean data))
(format stream "The sample standard deviation is ~g~%"
(standard-deviation data))))对于每个有它自己的方法的对小,消息:own-methods返回了一个消息列表:
> (send x :own-methods)
(:DESCRIBE :DATA :DISCRIBE)> (send x :method-selectors)
(:DESCRIBE :DATA :TITLE :METHOD-SELECTORS :SLOT-NAMES :SLOT-VALUE :PRINT :RETYPE :NEW :HELP :DELETE-DOCUMENTATION :DOCUMENTATION :DOC-TOPICS :MAKE-PROTOTYPE :INTERNAL-DOC :OWN-METHODS :OWN-SLOTS :PRECEDENCE-LIST :PARENTS :ISNEW :SHOW :DELETE-METHOD :ADD-METHOD :DELETE-SLOT :ADD-SLOT :HAS-METHOD :HAS-SLOT :REPARENT :GET-METHOD)你也可以使用不带参数的:delete-method消息从一个对象里删除一个方法,这个方法的消息选择器符号将被删除。
练习 6.2
略。
练习 6.3
略。
练习 6.4
略。
6.2.4 对象打印
通过向Lisp-Stat打印系统发送:print消息来打印一个对象。针对这个从根对象继承来的消息的方法,来产生类似下边的输出:
#<Object: 2106610, prototype = *OBJECT*>以下事实——以#<开始的打印的结果,表示这是一个读取器无法理解的形式。作为一个替换方法,你可以定义你自己的:print方法。为了与这个被调用的方法的方式一致,应该加入一个可选的流参数,如果使用该流参数它将被打印到标准输出上。举个例子,我们可以为x定义一个:print方法:
> (defmeth x :print (&optional (stream t))
(format stream "#<~a>" (send self :title)))
:PRITN> x
#<a data set>6.3 原型和继承
6.3.1 构造原型和实例
通过重复创建对象、添加数据和标题槽和定义一个方法集这些过程,我们可以定义额外的数据集对象。但是这涉及到相当大的成倍的努力。与之相反,我们可以重复一次这个过程来构造一个原型数据集,然后使用这个原型作为一个模板来产生额外的数据集。
使用defproty宏来产生一个原型,在它最简单的形式里,调用如下:(defproto <name> <instance slots>)。第一个参数<name>应该是一个符号,它不会被求值;第二个参数应该是这样一个表达式:求值为一个符号列表。defproto宏有以下几个行为:
- 它构建一个新对象,分配一个全局变量<name>给对象,然后安装带<name>值的槽proto-name。默认地,该槽是:print方法使用的,用来构建对象的打印表达式的。
- 它的参数列表是由<instance slots>表达式产生的表达式列表组成的,接着安装一个名为instance-slots的槽,在新创建的对象里使用这个列表作为它的值。然后,它向这个对象里安装一个槽,对于每一个在instance-slots列表里的符号,该槽的值为nil。
instance-slots列表指定为每个由原型创建的对象指定槽名。通常地,由原型创建的不同的实例仅在它们的实例里槽的值是不同的。我们可以这样定义一个数据集原型:
> (defproto data-set-proto '(data title))
DATA-SET-PROTO> (send data-set-proto :slot-value 'title "a data set")
"a data set"同时,我们也可以用以下表达式形式为:describe、:data、:title和:print方法赋值:
> (defmeth data-set-proto :title (&optional (title nil set))
(if set (setf (slot-value 'title) title))
(slot-value 'title))
:TITLE
> (defmeth data-set-proto :data(&optional (data nil set))
(if set (setf (slot-value 'data) data))
(slot-value 'data))
:DATA
> (defmeth data-set-proto :describe (&optional (stream t))
(format stream "This is ~a~%" (slot-value 'title))
(format stream "The sample mean is ~g~%"
(mean (slot-value 'data)))
(format stream "The sample standard deviation is ~g~%"
(standard-deviation (slot-value 'data))))
:DESCRIBE
> (defmeth data-set-proto :print (&optional (stream t))
(format stream "#<~a>" (send self :title)))
:PRITN但是,一个原型的主要用途是作为构造新对象的模板。
原型的实例是这样一个对象,它集成自原型并包含原型指定的实例的槽作为它自己的槽。可以通过向原型发送:new消息来从一个原型构造一个实例,对于这个消息,它的方法继承自根对象,并具有如下行为:
- 它创建了一个继承自原型的新对象。
- 它通过一个由原型的instance-slots列表指定的槽向新对象加入槽,然后将这些槽初始化为原型里的值。
- 它向新对象发送带参数的初始化消息:isnew,那些参数在调用:new消息时使用,如果有这些参数的话。
- 它返回这个新对象。
从根对象继承来的:isnew方法是不需要参数的,但是它允许对象里的任意槽通过使用相应的关键字参数来初始化。
通过向data-set-proto发送一个带:data关键字参数(该参数用来为data槽安置一个值)的:new消息,我们可以创建一个data-set-proto原型的实例:
> (setf x (send data-set-proto :new :data (chisq-rand 20 5)))
#<a data set>> (send x :describe)
This is a data set
The sample mean is 4.886239840565315
The sample standard deviation is 3.1586394887010028
NIL因为任何新的数据集需要一个值作为其数据槽,为这个槽编写一个:isnew方法,它需要一个为这个槽指定的值。例如,我们可以这样定义一个方法:
> (defmeth data-set-proto :isnew (data &key title)
(send self :data data)
(if title (send self :title title)))
:ISNEW当创建一个对象时,通过集成获得的方法与槽集合不会被冻结。例如,创建一个继承自data-set-proto的x对象,我们可以这样为data-set-proto定义一个:plot方法:
(defmeth data-set-proto :plot ()
(histogram (send self :data)))最后,你可能想要为我们的原型定义一个构造函数:
(defun make-data-set (x &key (title "a data set") (print t))
(let ((object (send data-set-proto :new x :title title)))
(if print (send object :describe))
object))> (defun describe-data (data) (send data :describe))
DESCRIBE-DATA
> (defun plot-data (data) (send data :plot))
PLOT-DATA6.3.2 继承自原型的原型
defproto宏可被用来设置一个原型,该原型从其他对象,通常是从其他原型对象继承而来。一个对该宏的完整的调用形式为:
(defproto <name> <instance slots> <shared slots> <parents> <doc string>)如果defproto宏使用一个强制的父对象进行调用的话,那么这个新对象将直接从<parents>继承来进行构造。此外,被包含到新原型里的实例槽的列表作为以下形式存在:作为父对象的实例槽和被指定为<instance slots>参数的组合形式。因此,你仅需要指定你需要的所有的额外的,父对象里不包含的那些实例槽。当defproto宏安装父对象要求的实例槽时,它初始化这些槽到它们的被继承值。
让我们使用defproto宏为一个时间序列对象设置一个原型,该时间序列是从我们上边定义过的数据集原型继承来的。data槽和title槽将被自动包含。此外,我们可能想要包含origin槽和spacing槽用来指定原点和观测时间之间的间隔。这将引出如下定义:
> (defproto time-series-proto
'(origin spacing) () data-set-proto)
TIME-SERIES-PROTO为新原型准备的title槽初始化时包含从data-set-proto继承来的值:
> (send data-set-proto :title)
"a data set"> (send time-series-proto :title "a time series")
"a time series"> (defmeth time-series-proto :origin (&optional (origin nil set))
(if set (setf (slot-value 'origin) origin))
(slot-value 'origin))
:ORIGIN
> (defmeth time-series-proto :spacing (&optional (sp nil set))
(if set (setf (slot-value 'spacing) sp))
(slot-value 'spacing))
:SPACING> (send time-series-proto :origin 0)
0
> (send time-series-proto :spacing 1)
1现在我们可以这样构造一个时间序列对象来表示一个短的移动的平均值序列:
> (let* ((e (normal-rand 21))
(data (+ (select e (iseq 1 20))
(* .6 (select e (iseq 0 19))))))
(setf y (send time-series-proto :new data)))
#<a time series>从data-set-proto原型继承来的:isnew方法需要data参数。如果我们像该新时间序列发送:describe消息,从data-set-proto原型继承来的方法将产生:
> (send y :describe)
This is a time series
The sample mean is 0.4011466522084276
The sample standard deviation is 0.9777933783149011
NIL6.3.3 覆写和修改继承的方法
从data-set-proto继承来的:plot方法产生了一个时间序列直方图。它更合适去绘制相对于时间的序列。我们可以在时间序列原型里为:plot定义一个新方法,然后"覆盖"继承来的:plot方法,就像这样:
> (defmeth time-series-proto :plot ()
(let* ((data (send self :data))
(time (+ (send self :origin)
(* (iseq (length data))
(send self :spacing)))))
(plot-points time data)))
:PLOT> (defmeth time-series-proto :describe (&optional (stream t))
(call-next-method stream)
(format stream
"The autocorrelation is ~g~%"
(autocorrelation (send self :data))))
:DESCRIBE> (defun autocorrelation (x)
(let ((n (length x))
(x (- x (mean x))))
(/ (mean (* (select x (iseq 0 (- n 2)))
(select x (iseq 1 (- n 1)))))
(mean (* x x)))))
AUTOCORRELATION> (send y :describe)
This is a time series
The sample mean is 0.4011466522084276
The sample standard deviation is 0.9777933783149011
The autocorrelation is 0.40181991922789645
NIL> (defmeth data-set-proto :isnew (data &rest args)
(apply #'call-next-method :data data args))
:ISNEW 此时我们可能想要调用属于一个对象的方法,该方法当前对象的继承路径里,或者是一个不在优先级列表里的下一个方法。我们可以使用call-method函数来达到这一目的。该函数这样调用:
(call-method <owner> <selector> <arg 1> ... <arg n>)
<owner>的优先级列表的搜索是为消息<selector>查找方法,然后那个方法将使用当前对象和所有额外测参数。使用call-method函数,time-series-proto原型的:describe方法可以这样定义:
> (defmeth time-series-proto :describe (&optional (stream t))
(call-method data-sset-proto :describe stream)
(format stream
"The autocorrelation is ~g~%"
(autocorrelation (send self :data))))
:DESCRIBE对象系统不允许你从公共区域访问想要内部使用的槽和消息。为了饱和你自己免受被继承的方法的破坏,你应该确保不要去修改槽或者覆写方法,除非你确定你的修改与它们被其它方法使用的结果是一致的。再强调一次,无论何时,避免直接使用读取方法读取槽十个好主意。
练习 6.5
略。
练习 6.6
略。
6.4 额外的细节
本节展示Lisp-Stat对象系统的一些低层面的细节,首次接触者可以忽略本节的阅读。6.4.1 创建对象和原型
你可以使用make-object函数构建一个对象,代替使用一个原型来构建。传递给make-object函数的参数是这个新对象的父对象。如果不适用参数调用make-object函数,那么它将构建一个继承自根对象的对象。因此,第6.2.2节的数据集对象可以这样构建:
> (setf x (make-object))
#<Object: 13de8e4, prototype = *OBJECT*>原型就是一个包含proto-name和instance-slots两个槽的对象。构建一个原型最简单的方式就是使用defproto宏。但是你也可以使用一个现存的对象构建,比如说上边构建的对象x,然后通过发送:make-prototype消息将它转换为一个原型。该消息带两个参数,一个用来作为proto-name槽的值的符号和一个表示额外实例变量的符号列表。该消息的方法将查找由对象的父对象指定的实例槽,如果有的话,使用消息里指定的实例槽将它们组合在一起,然后将结果安置在instance-slots槽里。然后,它为instance-slots列表里的每一个元素安置一个槽,除非这样的槽已经存在了。现在槽已经使用从对象的祖先继承来的值初始化过了。因此,我们可以使用以下表达式将我们的x对象转换为一个原型:
> (send x :make-prototype 'data-set-proto '(data title))
#<Object: 13de8e4, prototype = DATA-SET-PROTO> Lisp-Stat原型系统是通过defproto宏和针对:new和:make-prototype消息的根对象方法来实现的。这些方法不应被覆写,除非你想修改原型系统。
6.4.2 额外的方法和函数
为了检测对象,有一些额外的方法和函数时可用的。
通过使用:precedence-list消息,对象的优先级列表可以包含到对象里,它的直接父对象可以通过使用:parents来包含。例如,对于第6.3节的那个原型:
> (send time-series-proto :precedence-list)
(#<a time series>
#<a data set>
#<Object: 13fd0c8, prototype = *OBJECT*>)
> (send time-series-proto :parents)
(#<a data set>)> (kind-of-p time-series-proto data-set-proto)
T
> (kind-of-p data-set-proto time-series-proto)
NIL> (send x :reparent time-series-proto)
#<NIL>6.4.3 共享槽
defproto宏允许共享槽的设置,该槽被安置在原型里而不是在实例里复制。这个机制不是很常用,但是偶尔很有用。举个例子,假设你想能够回溯一个特殊原型的所有实例,你可以像这样定义原型来达到目的:
> (defproto myproto '(...) '(instances))> (defmeth myproto :new (&rest args)
(let ((object (apply #'call-next-method args)))
(setf (slot-value 'instances)
(cons object (slot-value 'instances)))
object))
:NEW在这一点上忠告可能是合适的。平常,如果创建了一个对象,他就会一直存在,只要它作为一些变量的值或者一些结构的组件。一旦它不被引用了,Lisp系统就会在垃圾回收进程里自动回收它的空间。你无需强制释放。然而,如果一个原型要回溯它的实例,那么该实例就会从原型里被引用,并且不会被回收。因此你将不得不通过定义一个:dispost方法,自行安排去强制性地通知原型有一个对象不再需要了:
> (defmeth myproto :dispose (object)
(setf (slot-value 'instances)
(remove object (slot-value 'instances))))
:DISPOSE6.4.4 对象文档系统
对象系统允许你为你选择的对象的任何主题安置文档字符串。这些主题可以被符号名识别,也可以通过使用:documentatiion消息来设置和取回。例如,
(send data-set-proto :documentation :title)> (send data-set-proto :documentation
:title "sets or returns the title")
"sets or returns the title"> (send data-set-proto :help :title)
TITLE
sets or returns the title
NIL:doc-topics消息返回将为所有可用的文档字符串返回符号列表。针对数据集原型,发送这个消息的结果是:
> (send data-set-proto :doc-topics)
(:TITLE :REPARENT :INTERNAL-DOC :OWN-METHODS :OWN-SLOTS :PRECEDENCE-LIST :PARENTS :ISNEW :SHOW :DELETE-METHOD :DELETE-SLOT :ADD-METHOD :ADD-SLOT :HAS-METHOD :HAS-SLOT :GET-METHOD PROTO :METHOD-SELECTORS :SLOT-NAMES :SLOT-VALUE :PRINT :RETYPE :NEW :HELP :DELETE-DOCUMENTATION :DOCUMENTATION :DOC-TOPICS)> (send data-set-proto :help)
DATA-SET-PROTO
The root object.
Help is available on the following:
ADD-METHOD ADD-SLOT DELETE-DOCUMENTATION DELETE-METHOD DELETE-SLOT DOC-TOPICS DOCUMENTATION GET-METHOD HAS-METHOD HAS-SLOT HELP INTERNAL-DOC ISNEW METHOD-SELECTORS NEW OWN-METHODS OWN-SLOTS PARENTS PRECEDENCE-LIST PRINT PROTO REPARENT RETYPE SHOW SLOT-NAMES SLOT-VALUE TITLE
NIL> (send data-set-proto :documentation
'proto "A generic data set.")
"A generic data set."> (send data-set-proto :help)
DATA-SET-PROTO
A generic data set.
Help is available on the following:
ADD-METHOD ADD-SLOT DELETE-DOCUMENTATION DELETE-METHOD DELETE-SLOT DOC-TOPICS DOCUMENTATION GET-METHOD HAS-METHOD HAS-SLOT HELP INTERNAL-DOC ISNEW METHOD-SELECTORS NEW OWN-METHODS OWN-SLOTS PARENTS PRECEDENCE-LIST PRINT PROTO REPARENT RETYPE SHOW SLOT-NAMES SLOT-VALUE TITLE
NIL6.4.5 保存对象
为了能够在另一个会话或者机器里恢复对象,有时将一个对象保存到文件里是有用的。开发一个对所有的可能的对象都起作用的策略看起来是不可能的。因此Lisp-Stat采用了这样一个惯例:一个能被保存到文件的对象应该相应:save消息。该消息应该返回一个可以被打印到一个文件的表达式。当该表达式被读回和求值的时候,可以构造出对象的复制品。例如,对于data-set-proto原型,可以使用反引号机制定义一个:save方法:
> (defmeth data-set-proto :save ()
`(send data-set-proto :new
',(send self :data)
:title ',(send self :title)))
:SAVE> (send x :save)
(SEND DATA-SET-PROTO :NEW
(QUOTE NIL)
:TITLE (QUOTE NIL))savevar函数使用:save消息保存变量,其值是要保存到文件的对象。一些对象没有提供:save方法,试图保存这样的对象将引发一个错误。
6.5 一些内置原型
Lisp-Stat包含一些内置原型。这些原型的继承树的一个子集显示在图6.1中。这些原型里的很多都与系统的绘图部分是相关联的,将在下一章里描述。本节只大略地表示非绘图原型中的三个:组合数据原型,回归模型原型和非线性回归模型原型。
6.5.1 组合数据对象
到目前为止,我们仅仅考虑了列表和数组作为可能的组合数据项。更多一般的集合也可以定义为组合数据对象。设计矢量化算术系统和map-elements函数时也使用了这些对象。任何一个继承自compound-data-proto原型的对象都是组合数据对象,并具有如下特征:
- 它包含一个元素的序列,这些元素可以通过使用:data-seq消息来提取。
- 它的数据序列的长度可以使用:data-length消息来确认。
- 通通过使用:make-data消息,它可以创建一个像它自身一样的新对象,除了一个新的数据序列。该消息的参数可以是一个列表或者一个向量。
举个简单的例子,让我们定义一个对象来表示二维空间里的一个点,该对象带两个实例槽,它的笛卡尔坐标x和y:
> (defproto point-proto '(x y) '() compound-data-proto)
POINT-PROTO> (defmeth point-proto :x (&optional (x nil set))
(if set (setf (slot-value 'x) x))
(slot-value 'x))
:X
> (defmeth point-proto :y (&optional (y nil set))
(if set (setf (slot-value 'y) y))
(slot-value 'y))
:Y> (defmeth point-proto :isnew (x y)
(send self :x x)
(send self :y y))
:ISNEW> (defmeth point-proto :data-length () 2)
:DATA-LENGTH
> (defmeth point-proto :data-seq ()
(list (send self :x) (send self :y)))
:DATA-SEQ
> (defmeth point-proto :make-data (seq)
(send point-proto :new (select seq 0) (select seq 1)))
:MAKE-DATA> (defmeth point-proto :print (&optional (stream t))
(format stream
"#<a point located at x = ~d and y = ~d>"
(send self :x)
(send self :y)))
:PRINT通过向矢量化算术系统传送:data-seq消息,该系统可以提取一个组合数据对象的数据序列。如果传递给矢量化函数的第一个复合参数是一个组合数据对象的话,那么通过向那个对象传送:make-data消息可以构造结果。因为我们的点对象遵循必要的协议,例如,这意味着我们可以使用+函数来加两个点,使用*函数让一个点与一个常量相乘,或者使用log函数求取一个点的坐标的对数值:
> (+ a a)
#<a point located at x = 6 and y = 10>
> (* a 2)
#<a point located at x = 6 and y = 10>
> (log a)
#<a point located at x = 1.0986122886681098 and y = 1.6094379124341003>练习 6.7
6.5.2 线性回归模型
线性回归模型对象已经在第2.6节里介绍过了。本小节将给出额外的细节。
回归模型原型是regression-mode-proto,它可以使用一个像下式的表达式来构建:
> (defproto regression-mode-proto
'(x y intercept weights included
predictor-names response-name case-labels
sweep-matrix basis
total-sum-of-squares
residual-sum-of-squares))
REGRESSION-MODE-PROTO因此这个原型有12个实例槽,没有共享槽,继承自根对象。前8个槽包含描述模型的信息。每一个槽都可以通过对应的关键字:x, :y, :intercept等等命名读取方法来进行读取和修改。改变前5个槽中的任何一个都需要被计算的模型对象内的估计,重新计算发生在下一次需要计算结果的时候。最后四个槽是计算方法内部使用的。相应的关键字命名的读取方法可以用来读取槽的内容,但是无法改变它们的值。槽读取器和读取方法是唯一的可以直接使用槽的方法;其它的方法只能使用读取函数和读取方法来使用槽。
回归模型原型里的剩余的方法可以被分成几个组。对应:df, :num-cases, :num-coefs和:num-included的方法将返回关于模型维度的信息。:sum-of-squares方法将返回残差平方和。对应:x-matrix的方法,如果其中包括截距这一术语的话,它将返回一个列矩阵,其后跟着一个对应拟合过程里的一个基础应用的独立变量。带权值情况下的(XTX)-1和(XTWX)-1矩阵是由:xtxinv返回的,这里的X是由:x-matrix返回的矩阵。拟合过程中使用的列的下标列表是由:basis消息返回的。
系数的标准差和估计量是由coef-standard-errors和:coef-estimates返回的。:sigma-hat返回估计后的均方差。拟合后的值由:fit-values返回,采样平方与相关性系数由:r-squared返回。
对残差和影响性分析有用的消息有:cooks-distance, :externally-studentized-residuals, :leverages, :raw-residuals, :residuals和:studentized-residuals。还有两个残差绘图方法是:plot-bayes-residuals和:plot-residuals。
模型的概略性描述可以由:display消息打印。regression-model函数将发送这个消息到一个新模型,如果该函数的值不是nil的话。针对:save消息的方法将试图返回一个表达式,该表达式可以求值而重新生成模型对象。
:compute和:need-computing主要是内部使用。:compute方法重新计算估计量。:needs-compute的方法如果以不带参数的形式调用将确定该模型是否需要被重新计算;如果以带参数t的形式调用,在被计算的槽下次被读取的时候,它将告诉对象重新计算自身。这允许模型的一些特性可以立刻被修改而不需要每次修改之后都进行模型的重新计算。
:isnew方法仅会设置模型对象,然后将它标记为需要被重新计算。它不允许通过关键字参数来指定槽。因此如果你不想使用regression-model构造函数构建一个模型,你可以向原型发送:new消息来构造一个新的对象,然后使用读取方法向模型里添加模型组件。
6.5.3 非线性回归模型
通过下边的表达式,可以定义非线性回归原型nreg-model-proto:
> (defproto nreg-model-proto
'(mean-function theta-hat epsilon count-limit verbose)
nil
regression-model-proto)
NREG-MODEL-PROTO 使非线性回归模型原型继承线性模型原型的方法看起来非常的奇怪。非线性即不一定是线性的意思,非线性回归模型是线性回归模型的一个超集,在目前给定的所有例子里,新的原型已经作为它们的父对象的特化被介绍了。在这种情况下我将使用继承关系来表示一种相似性而非特化性。拟合和计算拟合值这两个操作在非线性模型和在非线性模型里是非常不同的。但是估计量的标准误差、杠杆值(即用于模型稳定性评价的值)和相似量通常是通过对非线性模型的线性化的方式计算出来的,该非线性模型是使用被估计参数值的一定范围的扩大值得到的。在这个线性化的近似值中,X矩阵的角色由被估计参数值处的均值函数的雅克比矩阵充当。有了这个身份,标准差、杠杆值等等的公式,还有对于线性情况在非线性的情况下也有意义,至少作为一阶近似值是有意义的。
这种相似性是由继承关系捕捉的。非线性模型的原型包含一个针对:compute的新方法,该方法可以使用带回溯的高斯-牛顿搜索法找出极大似然估计量。然后它将雅克比矩阵安置为x槽的值,对于现行回归计算使用线性估计值,再利用继承来的:compute方法将它添加到槽中。最后,它将剩余平方和的合适的值安置到它的槽里。也可以为:fit-values、:coef-estimates和:save定义新的方法。一个叫做:parameter-names的新消息可以加到对象里来为显示方法而提供它们的名字。这些储存在predictor-names槽里。因为改变X矩阵, 截距, 或者谓词名不再有意义,对应的消息会被新的方法覆写,这些方法仅允许读取,不允许修改。最后,为:new-initial-guess准备的一个方法被添加到对象里,目的是允许交互性地搜索估计值,然后在一个新的初始化值处重启。所有其它的方法都是继承自线性回归原型的。它们提供了基于线性化模型的合理的估计值。例如,如果找到了杠杆值的一个较好的定义,那么继承来的方法可以使用一个针对非线性模型的一个方法来覆写。但是到目前为止,一阶近似值是自动可用的。
非线性模型也可以定义为线性模型的父级。存在正态线性回归模型的其它可能的泛化,它可以被安置到比线性化模型提前发生的位置。其中的一个例子就是文献42中的McCullagh和Nelder表述的真正的泛化的线性模型。它们都可以使用多重继承方法作为线性模型的父级,就像下一节要描述到的一样。哪一种方法更好还不确定,这两种方法分别是通过相似性使用推理的方法和通过泛化而基于一个排序的方法。这两种方法都有各自的优势。这里使用的方法可能更加适合这种情况:在该情况里模型的新类型正在被开发,并且需要从继承关系里获益而使开发变成更简单和更易理解的形式。换句话说,泛化的顺序很有可能更适合这种情况:即在这种情况下层级关系容易理解,并且易于进一步的开发。尽管正态非线性回归模型已经被广泛研究,在方法论上仍然有相当大的空间改进该理论以适应对它的分析。这也就是我选择在这里的描述表达方式的原因。
6.6 多重继承
目前用到的涉及到对象的所有例子都是单独父级的继承。因此,这些对象的优先级列表可以通过简单回溯的方法来确定,回溯过程是从该对象的父级开始一直到根对象的过程。在多重继承里(即一个对象有多个父级的情况),不再有一个构建优先级列表的明显的方式,我们需要采用一些惯例。
优先级列表就是设计用来提供对象及其祖先的完整的顺序的列表。该顺序使用如下规则构建:
- 对象总是先于它的父级。
- 对象的父级的列表提供一个关于这些对象的局部的顺序,这个顺序必须是可以保存的。
- 重复的对象将从顺序里忽略掉,出现次数超过一次的对象将在顺序上尽可能地放在开始的位置,而不是违反其它规则。
- 如果没有这样的规则存在则发生错误。
这里有一个关于一个原型集合顺序产生的例子,定义6个原型:
> (defproto food)
FOOD
> (defproto spice () () food)
SPICE
> (defproto fruit () () food)
FRUIT
> (defproto cinnamon () () spice)
CINNAMON
> (defproto apple () () fruit)
APPLE
> (defproto pie () () (list apple cinnamon))
PIE> (send pie :precedence-list)
(#<Object: 142dea8, prototype = PIE>
#<Object: 141e78c, prototype = APPLE>
#<Object: 141eb9c, prototype = FRUIT>
#<Object: 141e97c, prototype = CINNAMON>
#<Object: 141ed4c, prototype = SPICE>
#<Object: 141f08c, prototype = FOOD>
#<Object: 13fd510, prototype = *OBJECT*>)> (defproto spice-cake () () (list spice pie))
Error: inconsistent precedence order
Happened in: #<FSubr-DEFPROTO: #13feb50>> (defproto spice-cake () () (list pie spice))
SPICE-CAKE6.7 其它对象系统
面向对象编程的起源通常要追溯到1960年代后期,1970年代前期由Simula开发的Simulation语言。这种编程范式最早发现是在Smalltalk语言中使用的,Smalltalk语言是施乐公司帕洛阿尔托研究中心在1970年代中叶开发的。Smalltalk是纯面向对象语言:所有的数据都是对象。在Smalltalk里像 1+2这样的表达式将被解释为”向对象1发送消息,将对象2加到它之上,然后返回一个表示结果的对象。“
在坚持使用面向对象的编程范式的力度方面,Smalltalk是不同寻常的。大多数系统支持面向对象编程都是使用一个混合的方法,即向已存在的语言里加入面向对象编程工具,这样的系统的例子有C++和Objective-C,还有Pascal的Classcal和Object等Pascal扩展。针对Lisp的面向对象扩展也已经开发出来了,包括Object Lisp,Flavors,Common Objects和Common Lisp对象系统CLOS。
最近几年面向对象思想已经受到相当的关注,因为他们在设计图形用户界面方面的使用时很理想的,就像那些在Smalltalk系统里的部分和由Apple Macintosh系统推广中开发的接口。绘图对象,比如窗体和菜单,它们可以很自然地表示成软件对象,用户所做的操作,比如说要求一个窗体改变大小或者按下一个按钮来初始化一个动作,这些操作很自然地被翻译到消息里再发送给这些对象。上边提到的两个面向对象的Pascal方言都是主要为了支持Macintosh操作系统的编程而开发的。
大多数可编译的对象系统都是基于类思想的。类是一个泛化的模板,或者说是一个对象的定义,很像C语言里的结构体的定义,或者Pascal里记录的定义。特殊的是,一个类通常不是一个对象。对象是作为一个特定类的实例来构建的。类的定义要指定槽,或者叫实例变量,那是它的实例应给有的,它还应该指定一个或多个类作为其超类。因此为了构造一个带有指定槽集合的对象,你必须首先定义一个合适的类,然后构造一个对象作为该类的实例。在编译系统里,比如C++或者Object Pascal,类在程序源码里定义,一旦程序被编译,类的定义将固定。相反,类的实例可以在运行时动态分配。Smalltalk和基于CLOS的对象系统的标准类是基于类的系统。
对基于类的方法的替换方案就是允许任意对象直接继承任何其它对象,就像集成在Lisp-Stat里的系统一样。类似系统的其它例子包括Object Lisp系统和Trellis/Owl语言。这些系统通常叫做基于原型的系统。原型,也叫做exemplars,可以像类一样使用来帮助组成一个继承层级关系,但是它们的使用不是强制性的。这就赋予了基于原型的系统更多的灵活性。这个灵活性的代价就是一个类标识符不能用来提供类型检查信息,也不能自动地确认一个对象是否有针对指定方法需要的合适的槽集合。因为槽是不能自动地加入到对象的,对于一个编译器想在编译器优化方法就更困难了。
关于基于类还是基于原型或者基于范例的相对优点的谈论一直在面向对象编程文化中进行着。已经表达的一个观点是基于类的方法可能更加适合良好理解和成熟程序的实现和维护,而基于原型的方法可能更适合程序的开发阶段。因为交互式的统计计算在很多方面是一个实验性的编程形式,我相信这个论点有助于使用基于原型的方法作为一个统计系统的一部分。在任何时候都可以向对象增加槽的能力,这与向S结构里增加组件的能力是相似的,这个在S系统里已经证明是非常有用的。因为这些原因我选择开发一个基于原型的系统来供Lisp-Stat使用。
Common Lisp社区最近开发了一个针对面向对象编程的标准叫做Common Lisp对象系统,即CLOS。该系统提供了一个标准的基于类的对象系统,并将多重继承哈多方法合并到CLOS中,目的是分发多个参数。它也提供了一个元类协议用来实现可替换的对象系统。Lisp-Stat系统在很大意义上与标准CLOS系统不同,但是它可以在由元类协议提供的框架内部实现。
6.8 一些例子
6.8.1 一个矩形数据集
在相关性分析中使用的数据集通常被视为一个表或者一个矩阵,案例用行来表示,变量用列表示。我们可以为这个数据类型增加一个数据集原型,这个数据类型通过将每个变量表示为一个列表,看做是一个带标签字符串的"面向列"的视图。另外,我们也可以允许在图形里使用案例标签。该原型可以定义为:
> (defproto rect-data-proto '(vlabels clabels) () data-set-proto)
RECT-DATA-PROTO 初始方法安置了data,title和一个使用标签的集合。如果没有使用任何标签,将使用变量和案例指标构建摸女人的标签:
> (defmeth rect-data-proto :isnew
(data &key title variable-labels case-labels)
(let ((n (length (first data)))
(m (length data)))
(send self :data data)
(if title (send self :title title))
(send self :variable-labels
(if variable-labels
variable-labels
(mapcar #'(lambda (x) (format nil "X~a" x))
(iseq 0 (- m 1)))))
(send self :case-labels
(if case-labels
case-labels
(mapcar #'(lambda (x) (format nil "~a" x))
(iseq 0 (-n 1)))))))
:ISNEW 我们需要针对:cariable-labels和:case-labels消息的方法,用来设置和获得标签:
> (defmeth rect-data-proto :variable-labels
(&optional (labels nil set))
(if set (setf (slot-value 'vlabels) labels))
(slot-value 'vlabels))
:VARIABLE-LABELS
> (defmeth rect-data-proto :case-labels
(&optional (labels nil set))
(if set (setf (slot-value 'clabels) labels))
(slot-value 'clabels))
:CASE-LABELS
> (send rect-data-proto :title "a rectangular data set")
"a rectangular data set"
(setf stack
(send rect-data-proto :new (list air temp conc loss)
:variable-labels
(list "Air" "Temp." "Concent." "Loss")))
> (defmeth rect-data-proto :plot ()
(let ((vars (send self :data))
(labels (send self :variable-labels)))
(case (length vars)
(1 (histogram vars :variable-labels labels))
(2 (plot-points vars :variable-labels labels))
(3 (spin-plot vars :variable-labels labels))
(t (scatterplot-matrix vars :variable-labels labels)))))
:PLOT
> (send stack :describe)
This is a rectangular data set
The sample mean is 46.3333
The sample standard deviation is 29.6613略。
练习 6.9
略。
6.8.2 一个备用的数据表示
表示矩形数据的另一个方法,是由McDonald提倡的,即通过表示每一个观测值或者案例,将一个"面向行"的视图作为对象。每个案例都给定槽,用来处理基础案例数据,还要有方法用来提取信息。这些方法被用来表示变量。表示派生的变量的其它的方法也被定义到这些基本方法里。
为了开始,一个观测量原型可以定义成如下样子:
> (defproto observation-proto '(label))
OBSERVATION-PROTO
> (defmeth observation-proto :isnew (&rest args)
(setf (slot-value 'label) (string (gensym "GBS-")))
(apply #'call-next-method args))
:ISNEW如果我们假设这里的标签和一个观测量可能拥有的所有的其它槽,它们仅当在一个对象构建的时候使用:isnew方法来填充,那么我们仅需要读取槽的方法。例如,一个读取标签的方法这样给定:
> (defmeth observation-proto :label () (slot-value 'label))
:LABEL> (defproto stack-obs-proto
'(air temp conc loss) () observation-proto)
STACK-OBS-PROTO> (defmeth stack-obs-proto :air () (slot-value 'air))
:AIR
> (defmeth stack-obs-proto :temp () (slot-value 'temp))
:TEMP
> (defmeth stack-obs-proto :conc () (slot-value 'conc))
:CONC
> (defmeth stack-obs-proto :loss () (slot-value 'loss))
:LOSS> (defmeth stack-obs-proto :log-loss () (log (send self :loss)))
:LOG-LOSS> (defproto data-set-proto '(data))
DATA-SET-PROTO那么我们可以定义一个方法,为每一个观测量获取一个变量的值得列表:
> (defmeth data-set-proto :values (var)
(mapcar #'(lambda (x) (send x var))
(slot-value 'data)))
:VALUES> (defmeth data-set-proto :plot (&rest args)
(let ((vals (mapcar #'(lambda (var) (send self :values var))
args))
(labels (send self :values :label))
(vlabs (mapcar #'string args)))
(case (length args)
(0 (error "too few arguments"))
(1 (histogram vals
:point-labels labels
:variable-labels vlabs))
(2 (plot-points vals
:point-labels labels
:variable-labels vlabs))
(3 (spin-plot vals
:point-labels labels
:variable-labels vlabs))
(t (scatterplot-matrix vals
:point-labels labels
:variable-labels vlabs)))))
:PLOT定义一个描述数据集里所有变量的:describe方法不再可能,因为这个不再是一个有意义的概念:观测值可以包含一个仅有很少共性的的各种不痛的变量。相反地,我们可以让:describe带一个或多个变量消息关键字作为参数,再提供一个这些变量的合理的概述信息。仅带一个变量的一个简单的方法可以定义成这样:
> (defmeth data-set-proto :describe (var)
(let ((vals (send self :values var)))
(format t "Variable Name: ~a~%" var)
(format t "Mean: ~g~%" (mean vals))
(format t "Median: ~g~%" (median vals))
(format t "Standard Deviation: ~g~%"
(standard-deviation vals))))
:DESCRIBE> (setf stack-list
(mapcar
#'(lambda (air temp conc loss label)
(send stack-obs-proto :new
:air air
:temp temp
:conc conc
:loss loss
:label (format nil "~d" label)))
air temp conc loss (iseq 0 20)))
(#<Object: 14251a4, prototype = STACK-OBS-PROTO>
#<Object: 1424164, prototype = STACK-OBS-PROTO>
#<Object: 1423964, prototype = STACK-OBS-PROTO>
#<Object: 14231d4, prototype = STACK-OBS-PROTO>
#<Object: 1422bf4, prototype = STACK-OBS-PROTO>
#<Object: 14225a4, prototype = STACK-OBS-PROTO>
#<Object: 1421f74, prototype = STACK-OBS-PROTO>
#<Object: 14217c4, prototype = STACK-OBS-PROTO>
#<Object: 1420d74, prototype = STACK-OBS-PROTO>
#<Object: 1420774, prototype = STACK-OBS-PROTO>
#<Object: 1420144, prototype = STACK-OBS-PROTO>
#<Object: 141fad4, prototype = STACK-OBS-PROTO>
#<Object: 141f484, prototype = STACK-OBS-PROTO>
#<Object: 141ee44, prototype = STACK-OBS-PROTO>
#<Object: 141e7e4, prototype = STACK-OBS-PROTO>
#<Object: 141e114, prototype = STACK-OBS-PROTO>
#<Object: 142d500, prototype = STACK-OBS-PROTO>
#<Object: 142cf40, prototype = STACK-OBS-PROTO>
#<Object: 142c890, prototype = STACK-OBS-PROTO>
#<Object: 142c170, prototype = STACK-OBS-PROTO>
#<Object: 142bb30, prototype = STACK-OBS-PROTO>)> (setf stack-loss (send data-set-proto :new :data stack-list))
#<Object: 142a100, prototype = DATA-SET-PROTO>> (send stack-loss :describe :loss)
Variable Name: LOSS
Mean: 17.523809523809526
Median: 15.
Standard Deviation: 10.171622523565489
NIL> (send stack-loss :describe :log-loss)
Variable Name: LOG-LOSS
Mean: 2.725909553155994
Median: 2.70805020110221
Standard Deviation: 0.5235304969004861
NIL> (send stack-loss :plot :log-loss :air :temp)
#<Object: 144ed2c, prototype = SPIN-PROTO> 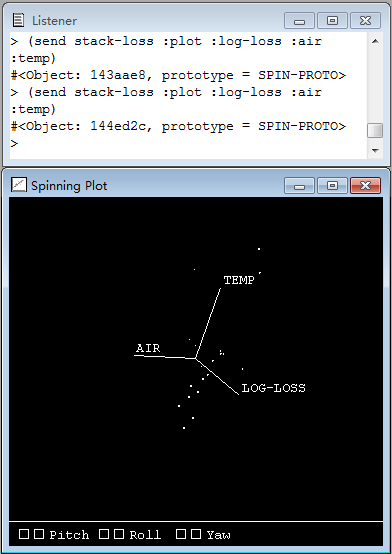















 5141
5141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









