







1.数据库高并发解决方案演示及说明
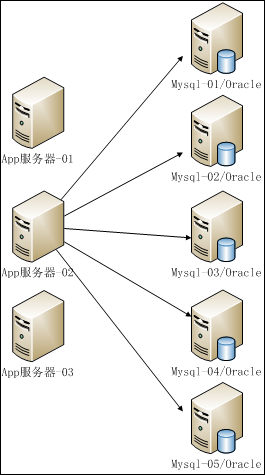
我们要解决的是数据库层面的高并发 ,App服务器上安装Tomcat,访问后端的Mysql集群
一台Tomcat连接多台数据库是如果连接的? 连接Mysql/Orcal的问题:
1:一台Tomcat 连接 多台数据库是如果连接的?
2:连接之后,是怎么解决高并发的?
下面我们用Mysql数据库举例说明解决数据库高并发的方案。
补充说明:为什么现在更多的互联网公司使用Mysql集群而不使用Oracle数据库?
①马云目前旗下:淘宝 天猫 支付宝 余额宝 阿里巴巴,统统不使用Oracle,使用自己公司开发的MyFox,MyFox就是以Mysql为基础开发而来的,Oracle 是非常贵的,Oracle收费是按照CPU收费的 无限期使用 32万美元 ~ 200万美元,紧紧是一台Oracle数据库的费用;
②互联网企业开发一般并发量比较大,要使用到数据库集群,单独一台Oracle是没什么意义的,N多台Oracle数据库的费用是相当昂贵的,并且Oracle本身不是开源的.一旦出现问题,必须找Oracle公司的在当地服务商代表来解决,需要收取服务费,别是中小企业或是创业型公司是使用不起的;
2.这里主要用Mysql数据库举例,演示的一套Java写的项目(Spring+ibatis框架),此项目的作用:
1)可以连接N多台Mysql;
2)可以检查后边Mysql的状态,并支持主Mysql与备Mysql切换;
3)如果其中一台Mysql数据库宕机,可以让程序代码自动访问另外一台备机;
4)此项目支持水平拆分,库表散列
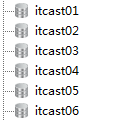
现在有六个数据库,分别为itcast01-itcast06,用来做演示:
项目应用场景:
Linux服务器上安装有一Mysql实例,对实例进行分库,分表操作,给大家分成六个库itcast01-itcast06作演示:
itcast01 itcast04 是一组 partition1
itcast02 itcast05 是一组 partition2
itcast03 itcast06 是一组 partition3
要求:1:存数据到6个库中;
2:取数据从6个库中;
Java写的项目架构(spring+ibatis,SI框架),开启eclipse,代码结构如下:
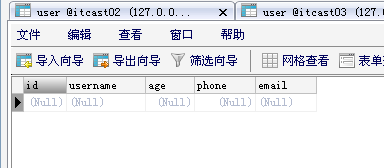
icast01-itcast06数据库中都有一张user表,使用到的user表的表结构如下:
应用的测试类的代码如下:
package com;
import java.util.List;
import org.junit.Ignore;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import com.caland.common.junit.AbstractSpringJunitTest;
import com.caland.core.bean.User;
import com.caland.core.query.UserQuery;
import com.caland.core.service.UserService;
/**
* junit
*/
public class TestUser extends AbstractSpringJunitTest{
//测试用户添加
//看看能不能添加到指定库去
//写好了Service Dao
//直接使用 自动装配
@Autowired
private UserService userService;
//开始运行了
@Test
@Ignore //忽略
public void testAddUser() throws Exception {
//用户对象是跟数据库一一对应的JavaBean
User user = new User();
user.setUsername("赵六");
user.setAge(36);
user.setPhone(138888888);
user.setEmail("888888@qq.com");
//把此数据添加到数据库去
userService.addUser(user);
}
//测试取数据
@Test
//@Ignore
public void testGetUser() throws Exception {
//使用用户的Service层来取
//知道只有一条
//实际当中 我们是不知道有多少条的
//返回的一定是List集合
//创建用户条件对象
UserQuery userQuery = new UserQuery();
//设置用户名 为 赵六 或李四
userQuery.setUsername("李四");
//返回结果
List<User> users = userService.getUserList(userQuery);
for(User user : users){
//输出结果
System.out.println(user.toString());
}
}
}其中testAddUser方法是向数据库中增加用户记录,testGetUser方法是从数据库中取出用户信息,
分别测试将'李四','赵六'两个用户存储到相应的数据库中,并从相应的数据库中取出这两个人的用户信息,结果如下:
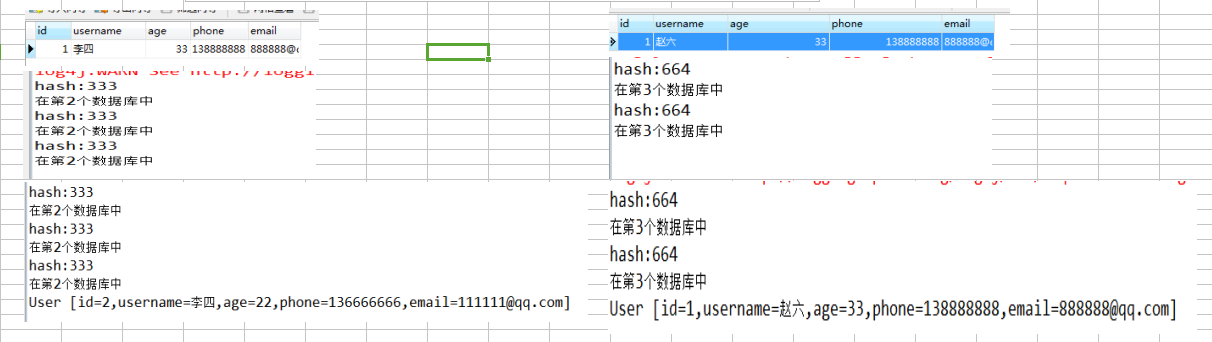
此项目就是支持水平拆分,库表散列,只演示了用户表User,新建一个测试类TestUser来进行存取用户信息的演示:
第一项:支持数据水平拆分和读取吗?
①测试用户'李四'的用户信息保存到itcast02库中,验证是否在02库中有数据,只有itcast02库有数据提示;
② 测试用户'赵六'的用户信息保存到itcast03库中,验证是否在03库中有数据, 只有itcast03库有数据提示;经过二次用户信息的保存,证明用户名路由规则是正确的;
验证:用户信息保存进去了,是不是能取出来呢?
③李四的用户信息在第2个库中,可以正常的取出李四的用户信息;
④赵六的用户信息在第3个库中,可以正常的取出赵六的用户信息;
总结:能存能取 功能是没问题的
第二项:支持数据容灾吗?
心跳检查数据,主库挂了,备库接管
①把李四保存到备库中呢?
李四是存在02中,如果把itcast02库删除了的话,那么李四还能保存吗?
证明:02库挂了,05库接管它的工作,保存了李四的用户信息;
②如果02库和05库都挂了,那就真的不能保存用户信息了,只能备份还原数据库服务器了;
注意:本项目演示是以单元Junit测试的,所有的对象都需要实例化,所以有会些慢。如果是以Tomcat启动的 ,启动的速度就会非常快了。
代码配置分析:


application-context.xml的配置信息如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jee="http://www.springframework.org/schema/jee" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.0.xsd
http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-3.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd"
default-lazy-init="true">
<!-- 使用Annotation自动注册Bean,解决事物失效问题:在主容器中不扫描@Controller注解,在SpringMvc中只扫描@Controller注解。 -->
<context:component-scan base-package="com"><!-- base-package 如果多个,用“,”分隔 -->
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>
<context:annotation-config/>
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location">
<value>classpath:/jdbc.properties</value>
</property>
</bean>
<!-- 配置数据源开始 -->
<bean id="dataSources" class="com.caland.sun.client.datasources.DefaultDataSourceService">
<property name="dataSourceDescriptors">
<set>
<bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
<property name="identity" value="partition1"/>
<property name="targetDataSource" ref="dataSource1"/>
<property name="targetDetectorDataSource" ref="dataSource1"/>
<property name="standbyDataSource" ref="dataSource4"/>
<property name="standbyDetectorDataSource" ref="dataSource4"/>
</bean>
<bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
<property name="identity" value="partition2"/>
<property name="targetDataSource" ref="dataSource2"/>
<property name="targetDetectorDataSource" ref="dataSource2"/>
<property name="standbyDataSource" ref="dataSource5"/>
<property name="standbyDetectorDataSource" ref="dataSource5"/>
</bean>
<bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
<property name="identity" value="partition3"/>
<property name="targetDataSource" ref="dataSource3"/>
<property name="targetDetectorDataSource" ref="dataSource3"/>
<property name="standbyDataSource" ref="dataSource6"/>
<property name="standbyDetectorDataSource" ref="dataSource6"/>
</bean>
</set>
</property>
<property name="haDataSourceCreator">
<bean class="com.caland.sun.client.datasources.ha.FailoverHotSwapDataSourceCreator">
<property name="detectingSql" value="update caland set timeflag=CURRENT_TIMESTAMP()"/>
</bean>
</property>
</bean>
<!-- 数据源1 -->
<bean id="dataSource1" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClassName}" />
<property name="jdbcUrl" value="${jdbc1.url}" />
<property name="user" value="${jdbc1.username}" />
<property name="password" value="${jdbc1.password}" />
<property name="autoCommitOnClose" value="true"/>
<!-- <property name="checkoutTimeout" value="${cpool.checkoutTimeout}"/>-->
<property name="initialPoolSize" value="${cpool.minPoolSize}"/>
<property name="minPoolSize" value="${cpool.minPoolSize}"/>
<property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
<property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
<property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
<property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
</bean>
<!-- 数据源2 -->
<bean id="dataSource2" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClassName}" />
<property name="jdbcUrl" value="${jdbc2.url}" />
<property name="user" value="${jdbc2.username}" />
<property name="password" value="${jdbc2.password}" />
<property name="autoCommitOnClose" value="true"/>
<!-- <property name="checkoutTimeout" value="${cpool.checkoutTimeout}"/>-->
<property name="initialPoolSize" value="${cpool.minPoolSize}"/>
<property name="minPoolSize" value="${cpool.minPoolSize}"/>
<property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
<property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
<property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
<property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
</bean>
<!-- 数据源3 -->
<bean id="dataSource3" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClassName}" />
<property name="jdbcUrl" value="${jdbc3.url}" />
<property name="user" value="${jdbc3.username}" />
<property name="password" value="${jdbc3.password}" />
<property name="autoCommitOnClose" value="true"/>
<!-- <property name="checkoutTimeout" value="${cpool.checkoutTimeout}"/>-->
<property name="initialPoolSize" value="${cpool.minPoolSize}"/>
<property name="minPoolSize" value="${cpool.minPoolSize}"/>
<property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
<property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
<property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
<property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
</bean>
<!-- 数据源4 -->
<bean id="dataSource4" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClassName}" />
<property name="jdbcUrl" value="${jdbc4.url}" />
<property name="user" value="${jdbc4.username}" />
<property name="password" value="${jdbc4.password}" />
<property name="autoCommitOnClose" value="true"/>
<!-- <property name="checkoutTimeout" value="${cpool.checkoutTimeout}"/>-->
<property name="initialPoolSize" value="${cpool.minPoolSize}"/>
<property name="minPoolSize" value="${cpool.minPoolSize}"/>
<property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
<property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
<property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
<property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
</bean>
<!-- 数据源5 -->
<bean id="dataSource5" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClassName}" />
<property name="jdbcUrl" value="${jdbc5.url}" />
<property name="user" value="${jdbc5.username}" />
<property name="password" value="${jdbc5.password}" />
<property name="autoCommitOnClose" value="true"/>
<!-- <property name="checkoutTimeout" value="${cpool.checkoutTimeout}"/>-->
<property name="initialPoolSize" value="${cpool.minPoolSize}"/>
<property name="minPoolSize" value="${cpool.minPoolSize}"/>
<property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
<property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
<property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
<property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
</bean>
<!-- 数据源6 -->
<bean id="dataSource6" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClassName}" />
<property name="jdbcUrl" value="${jdbc6.url}" />
<property name="user" value="${jdbc6.username}" />
<property name="password" value="${jdbc6.password}" />
<property name="autoCommitOnClose" value="true"/>
<!-- <property name="checkoutTimeout" value="${cpool.checkoutTimeout}"/>-->
<property name="initialPoolSize" value="${cpool.minPoolSize}"/>
<property name="minPoolSize" value="${cpool.minPoolSize}"/>
<property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
<property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
<property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
<property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
</bean>
<!-- 配置数据源结束 -->
<!-- 配置路由规则开始 -->
<bean id="hashFunction" class="com.caland.core.dao.router.HashFunction"/>
<bean id="internalRouter"
class="com.caland.sun.client.router.config.InteralRouterXmlFactoryBean">
<!-- functionsMap是在使用自定义路由规则函数的时候使用 -->
<property name="functionsMap">
<map>
<entry key="hash" value-ref="hashFunction"></entry>
</map>
</property>
<property name="configLocations">
<list>
<value>classpath:/dbRule/sharding-rules-on-namespace.xml</value>
</list>
</property>
</bean>
<!-- 配置路由规则结束 -->
<!-- 事务配置 -->
<bean id="transactionManager" class="com.caland.sun.client.transaction.MultipleDataSourcesTransactionManager">
<property name="dataSourceService" ref="dataSources"/>
<property name="transactionSynchronization" value="2"/>
</bean>
<!-- 使用annotation定义事务 -->
<tx:annotation-driven transaction-manager="transactionManager"/>
<!-- iBatis SQL map定义。 -->
<bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<!-- 这里配置的dataSource0为默认的数据源,如果找不到数据库的话则到该数据源中查找 -->
<property name="dataSource" ref="dataSource1" />
<property name="configLocation">
<value>classpath:/sqlmap-config.xml</value>
</property>
</bean>
<!-- 工程里一定要使用此工程模板,不能再使用ibatis原生的api,不然有的情况会不经过的过滤 -->
<bean id="sqlMapClientTemplate" class="com.caland.sun.client.SunSqlMapClientTemplate">
<property name="sqlMapClient" ref="sqlMapClient" />
<property name="dataSourceService" ref="dataSources" />
<property name="router" ref="internalRouter" />
<property name="sqlAuditor">
<bean class="com.caland.sun.client.audit.SimpleSqlAuditor" />
</property>
<property name="profileLongTimeRunningSql" value="true" />
<property name="longTimeRunningSqlIntervalThreshold" value="3600000" />
</bean>
</beans>sharding-rules-on-namespace.xml的配置信息如下:
<rules>
<rule>
<namespace>Order</namespace>
<!--
表达式如果不使用自定义路由规则函数,而是直接使用 taobaoId%2==0这种的话就不用在文件
中配置<property name="functionsMap">中了
-->
<shardingExpression>hash.applyOrder(userId) == 1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>Order</namespace>
<shardingExpression>hash.applyOrder(userId) == 2</shardingExpression>
<shards>partition2</shards>
</rule>
<rule>
<namespace>Order</namespace>
<shardingExpression>hash.applyOrder(userId) == 3</shardingExpression>
<shards>partition3</shards>
</rule>
<rule>
<namespace>User</namespace>
<!--
表达式如果不使用自定义路由规则函数,而是直接使用 taobaoId%2==0这种的话就不用在文件
中配置<property name="functionsMap">中了
-->
<shardingExpression>hash.applyUser(username) == 1</shardingExpression>
<shards>partition1</shards>
</rule>
<rule>
<namespace>User</namespace>
<shardingExpression>hash.applyUser(username) == 2</shardingExpression>
<shards>partition2</shards>
</rule>
<rule>
<namespace>User</namespace>
<shardingExpression>hash.applyUser(username) == 3</shardingExpression>
<shards>partition3</shards>
</rule>
</rules>HashFunction哈希算法的代码如下:
package com.caland.core.dao.router;
/**
* 根据某种自定义的hash算法来进行散列,并根据散列的值进行路由
* 常见的水平切分规则有:
基于范围的切分, 比如 memberId > 10000 and memberId < 20000
基于模数的切分, 比如 memberId%128==1 或者 memberId%128==2 或者...
基于哈希(hashing)的切分, 比如hashing(memberId)==someValue等
* @author lixu
*
*/
public class HashFunction{
/**
* 对三个数据库进行散列分布
* 1、返回其他值,没有在配置文件中配置的,如负数等,在默认数据库中查找
* 2、比如现在配置文件中配置有三个结果进行散列,如果返回为0,那么apply方法只调用一次,如果返回为2,
* 那么apply方法就会被调用三次,也就是每次是按照配置文件的顺序依次的调用方法进行判断结果,而不会缓存方法返回值进行判断
* @param id
* @return
*/
public int applyOrder(Integer userId) {
//先从缓存获取 没有则查询数据库
//input 可能是id,拿id到缓存里去查用户的DB坐标信息。然后把库的编号输出
int result = (userId % 1024);
System.out.println("hash:" + result);
if(0 <= result && result < 256){
result = 0;
System.out.println("在第1个数据库中");
}
if(256 <= result && result < 512){
result = 1;
System.out.println("在第2个数据库中");
}
if(512 <= result && result < 1024){
result = 2;
System.out.println("在第3个数据库中");
}
return result;
}
/**
* 对三个数据库进行散列分布
* 1、返回其他值,没有在配置文件中配置的,如负数等,在默认数据库中查找
* 2、比如现在配置文件中配置有三个结果进行散列,如果返回为0,那么apply方法只调用一次,如果返回为2,
* 那么apply方法就会被调用三次,也就是每次是按照配置文件的顺序依次的调用方法进行判断结果,而不会缓存方法返回值进行判断
* @param id
* @return
*/
public int applyUser(String username) {
//先从缓存获取 没有则查询数据库
//input 可能是id,拿id到缓存里去查用户的DB坐标信息。然后把库的编号输出
int result = Math.abs(username.hashCode() % 1024);//0---1023
System.out.println("hash:" + result);//333
if(0 <= result && result < 256){
result = 1;
System.out.println("在第1个数据库中");
}
if(256 <= result && result < 512){
result = 2;
System.out.println("在第2个数据库中");
}
if(512 <= result && result < 1024){
result = 3;
System.out.println("在第3个数据库中");
}
return result;
}
}注意:本示例只是为了演示一下分库而已,只有主机有数据,没有同步备机,没有搭建主从复制和双主结构。
----------------------------------------------------------------------------------------------
大数据和高并发的解决方案总结:
现在,软件架构变得越来越复杂了,好多技术层出不穷,令人眼花缭乱,解决这个问题呢,就是要把复杂问题简单化,核心就是要把握本质。
软件刚开始的时候是为了实现功能,随着信息量和用户的增多,大数据和高并发成了软件设计必须考虑的问题,那么大数据和高并发本质是什么呢?
本质很简单,一个是慢,一个是等。两者是相互关联的,因为慢,所以要等,因为等,所以慢,解决了慢,也就解决了等,解决了等,也就解决了慢。
关键是如何解决慢和等,核心一个是短,一个是少,一个是分流。
短是指路径要短。典型的mvc结构是请求->controller->model->dao->view,然后把页面返回给用户。要想短的话,
1,页面静态化- 用户可以直接获取页面,不用走那么多流程,比较适用于页面不频繁更新。
2,使用缓存- 第一次获取数据从数据库准提取,然后保存在缓存中,以后就可以直接从缓存提取数据。不过需要有机制维持缓存和数据库的一致性,像使用redis、memcache和mongodb等NoSQL进行数据存储。
3,使用储存过程-那些处理一次请求需要多次访问数据库的操作,可以把操作整合到储存过程,这样只要一次数据库访问就可以了。
4,批量读取 - 高并发情况下,可以把多个请求的查询合并到一次进行,以减少数据库的访问次数
5,延迟修改 - 高并发情况下,可以把多次修改请求,先保存在缓存中,然后定时将缓存中的数据保存到数据库中,风险是可能会断电丢失缓存中的数据,
6, 使用索引 - 索引可以看作是特殊的缓存,尽量使用索引就要求where字句中精确的给出索引列的值。
少是指查询的数据要少:
1,分表 - 把本来同一张表的内容,可以按照地区,类别等分成多张表,很简单的一个思路,但是要尽量避免分出来的多表关联查询。
2,分离活跃数据 - 例如登录用户业务,注册用户很多,但是活跃的登录用户很少,可以把活跃用户专门保存一张表,查询是先查询活跃表,没有的话再查总表,这也类似与缓存啦。
3, 分块 - 数据库层面的优化,对程序是透明的,查询大数据只用找到相应块就行。
分流分为三种:
1,集群 - 将并发请求分配到不同的服务器上,可以是业务服务器,也可以是数据库服务器。
2,分布式 - 分布式是把单次请求的多项业务逻辑分配到多个服务器上,这样可以同步处理很多逻辑,一般使用与特别复杂的业务请求。
3,CDN - 在域名解析层面的分流,例如将华南地区的用户请求分配到华南的服务器,华中地区的用户请求分配到华中的服务器。
暂时总结这么多的方案,随着技术的进步,会有更多的方案出现,一起成长进步中。。。。。














 8863
8863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









