







HBase适合场景:单表超千万,上亿,且高并发!
HBase不适合场景:主要需求是数据分析,比如做报表。数据量规模不大,对实时性要求高!
HBase的查询工具有很多,如:Hive、Tez、Impala、Spark SQL、Kylin、Phoenix等。
一、HBase的安装
①、保证安装Hive的Linux服务器的环境变量中有JAVA_HOME
②、基于HADOOP工作,保证安装Hive的Linux服务器的环境变量中有HADOOP_HOME
1、HBase解压与安装(在hadoop102服务器上)
在hadoop102服务器上解压HBase到指定目录:
[whx@hadoop102 software]$ tar -zxvf HBase-1.3.1-bin.tar.gz -C /opt/module
修改/opt/module/hbase-1.3.1目录名称为/opt/module/hbase
[whx@hadoop102 module]$ ll
total 28
drwxrwxr-x. 9 whx whx 4096 Jan 31 14:45 flume
drwxr-xr-x. 11 whx whx 4096 Jan 31 10:43 hadoop-2.7.2
drwxrwxr-x. 7 whx whx 4096 Feb 2 10:11 hbase-1.3.1
drwxrwxr-x. 9 whx whx 4096 Jan 30 19:27 hive
drwxr-xr-x. 8 whx whx 4096 Dec 13 2016 jdk1.8.0_121
drwxr-xr-x. 8 whx whx 4096 Feb 1 16:32 kafka
drwxr-xr-x. 11 whx whx 4096 Jan 29 22:01 zookeeper-3.4.10
[whx@hadoop102 module]$ mv hbase-1.3.1/ hbase
[whx@hadoop102 module]$ ll
total 28
drwxrwxr-x. 9 whx whx 4096 Jan 31 14:45 flume
drwxr-xr-x. 11 whx whx 4096 Jan 31 10:43 hadoop-2.7.2
drwxrwxr-x. 7 whx whx 4096 Feb 2 10:11 hbase
drwxrwxr-x. 9 whx whx 4096 Jan 30 19:27 hive
drwxr-xr-x. 8 whx whx 4096 Dec 13 2016 jdk1.8.0_121
drwxr-xr-x. 8 whx whx 4096 Feb 1 16:32 kafka
drwxr-xr-x. 11 whx whx 4096 Jan 29 22:01 zookeeper-3.4.10
[whx@hadoop102 module]$
2、修改HBase配置文件
2.1 hbase-env.sh
JAVA_HOME配置(可不用改 因为Linux服务器的环境变量文件/etc/profile里面已经把JAVA_HOME设为全局了!)
export JAVA_HOME=/opt/module/jdk1.8.0_144
注释掉Configure PermSize(所用的JDK为1.8以上,不需要此配置)
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
使用HBase外部的Zookeeper,而不是用HBase内置的Zookeeper。默认是使用HBase内置的Zookeeper(HBASE_MANAGES_ZK=true)
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=false
2.2 hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<!-- 每个regionServer的共享目录,用来持久化Hbase,默认情况下在/tmp/hbase下面 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop101:9000/HBase</value>
</property>
<!-- hbase集群模式,false表示hbase的单机,true表示是分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- hbase依赖的外部Zookeeper地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
<!--外部Zookeeper各个Linux服务器节点上保存数据的目录-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/datas</value>
</property>
</configuration>
3、将hbase配置到系统环境变量中
[whx@hadoop102 ~]$ sudo vim /etc/profile
JAVA_HOME=/opt/module/jdk1.8.0_121
HADOOP_HOME=/opt/module/hadoop-2.7.2
HIVE_HOME=/opt/module/hive
FLUME_HOME=/opt/module/flume
HBASE_HOME=/opt/module/hbase
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin
export JAVA_HOME HADOOP_HOME HIVE_HOME FLUME_HOME HBASE_HOME PATH
[whx@hadoop102 ~]$ source /etc/profile
4、分发hbase安装目录、环境变量文件到hadoop101、hadoop103
[whx@hadoop102 module]$ xsync.sh hbase/
[whx@hadoop102 ~]$ xsync.sh /etc/profile
二、HBase的启动
1、HBase启动前先启动Zookeeper、HDFS
启动Zookeeper
[whx@hadoop102 ~]$ xcall.sh /opt/module/zookeeper-3.4.10/bin/zkServer.sh start
要执行的命令是/opt/module/zookeeper-3.4.10/bin/zkServer.sh start
----------------------------hadoop101----------------------------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
----------------------------hadoop102----------------------------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
----------------------------hadoop103----------------------------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
3037 QuorumPeerMain
3071 Jps
----------------------------hadoop102----------------------------------
3633 QuorumPeerMain
3677 Jps
----------------------------hadoop103----------------------------------
3072 Jps
3038 QuorumPeerMain
[whx@hadoop102 ~]$
启动HDFS
[whx@hadoop102 ~]$ start-dfs.sh
Starting namenodes on [hadoop101]
hadoop101: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-namenode-hadoop101.out
hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop102.out
hadoop101: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop101.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-datanode-hadoop103.out
Starting secondary namenodes [hadoop103]
hadoop103: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-whx-secondarynamenode-hadoop103.out
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
3361 Jps
3153 NameNode
3275 DataNode
3037 QuorumPeerMain
----------------------------hadoop102----------------------------------
3633 QuorumPeerMain
3876 DataNode
4106 Jps
----------------------------hadoop103----------------------------------
3281 SecondaryNameNode
3154 DataNode
3331 Jps
3038 QuorumPeerMain
[whx@hadoop102 ~]$
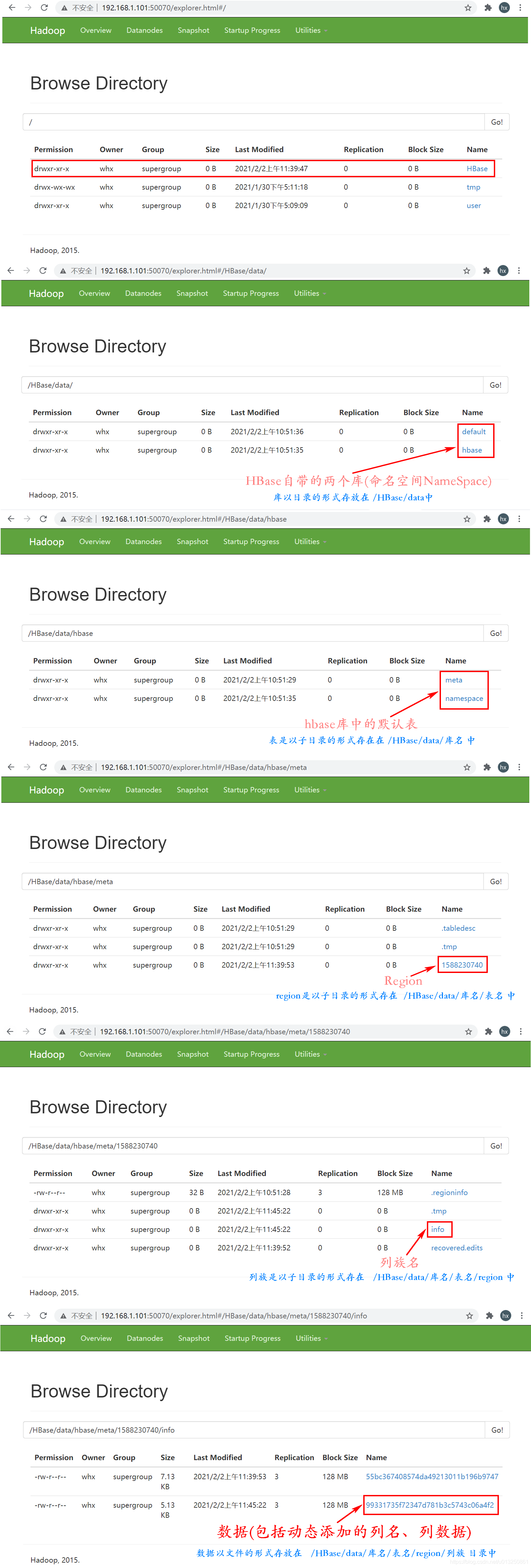
HBase中的对象的表现形式
- 库以目录的形式存放在 /HBase/data中
- 表是以子目录的形式存在在 /HBase/data/库名 中
- region也是以子目录的形式存在 /HBase/data/库名/表名 中
- 列族也是以子目录的形式存在 /HBase/data/库名/表名/region 中
- 数据以文件的形式存放在 /HBase/data/库名/表名/region/列族 目录中
2、HBase服务的启动/停止
2.1 启动/停止方式一:分别启动/停止master(选择任意一台节点)、regionserver(所有节点)
- 提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
- 修复提示:
- 同步时间服务
[whx@hadoop102 ~]$ xcall.sh sudo ntpdate -u ntp4.aliyun.com 要执行的命令是sudo ntpdate -u ntp4.aliyun.com ----------------------------hadoop101---------------------------------- 2 Feb 11:37:55 ntpdate[5838]: adjust time server 203.107.6.88 offset -0.010311 sec ----------------------------hadoop102---------------------------------- 2 Feb 11:37:56 ntpdate[8752]: adjust time server 203.107.6.88 offset -0.000953 sec ----------------------------hadoop103---------------------------------- 2 Feb 11:37:56 ntpdate[5930]: adjust time server 203.107.6.88 offset -0.004596 sec [whx@hadoop102 ~]$ - 属性:hbase.master.maxclockskew设置更大的值
<property> <name>hbase.master.maxclockskew</name> <value>180000</value> <description>Time difference of regionserver from master</description> </property>
- 同步时间服务
启动任意一个节点上的master(只启动一个节点上的master,比如hadoop102 )
[whx@hadoop102 ~]$ /opt/module/hbase/bin/hbase-daemon.sh start master
starting master, logging to /opt/module/hbase/bin/../logs/hbase-whx-master-hadoop102.out
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
3153 NameNode
3275 DataNode
3037 QuorumPeerMain
3670 Jps
----------------------------hadoop102----------------------------------
3876 DataNode
4426 HMaster
3633 QuorumPeerMain
4641 Jps
----------------------------hadoop103----------------------------------
3281 SecondaryNameNode
3154 DataNode
3038 QuorumPeerMain
3654 Jps
[whx@hadoop102 ~]$
停止hadoop102 节点上的master
[whx@hadoop102 ~]$ /opt/module/hbase/bin/hbase-daemon.sh stop master
stopping master.
[whx@hadoop102 ~]$
启动所有服务器上的regionserver
[whx@hadoop102 ~]$ xcall.sh /opt/module/hbase/bin/hbase-daemon.sh start regionserver
要执行的命令是/opt/module/hbase/bin/hbase-daemon.sh start regionserver
----------------------------hadoop101----------------------------------
starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop101.out
----------------------------hadoop102----------------------------------
starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop102.out
----------------------------hadoop103----------------------------------
starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop103.out
[whx@hadoop102 ~]$ xcall.sh jps
要执行的命令是jps
----------------------------hadoop101----------------------------------
3153 NameNode
3275 DataNode
3037 QuorumPeerMain
3447 HRegionServer
3610 Jps
----------------------------hadoop102----------------------------------
3876 DataNode
4426 HMaster
3633 QuorumPeerMain
4196 HRegionServer
4363 Jps
----------------------------hadoop103----------------------------------
3281 SecondaryNameNode
3154 DataNode
3038 QuorumPeerMain
3425 HRegionServer
3592 Jps
[whx@hadoop102 ~]$
停止所有服务器上的regionserver
[whx@hadoop102 ~]$ xcall.sh /opt/module/hbase/bin/hbase-daemon.sh stop regionserver
要执行的命令是/opt/module/hbase/bin/hbase-daemon.sh stop regionserver
----------------------------hadoop101----------------------------------
stopping regionserver.
----------------------------hadoop102----------------------------------
stopping regionserver.
----------------------------hadoop103----------------------------------
stopping regionserver.
[whx@hadoop102 ~]$
端口说明:
- 16000是master进程的RPC端口!
- 16010是master进程的http端口!
- 16020是RegionServer进程的RPC端口!
- 16030是RegionServer进程的http端口!
通过Web浏览器,输入 hadoop102:16010,可以通过hadoop102查看HMaster信息
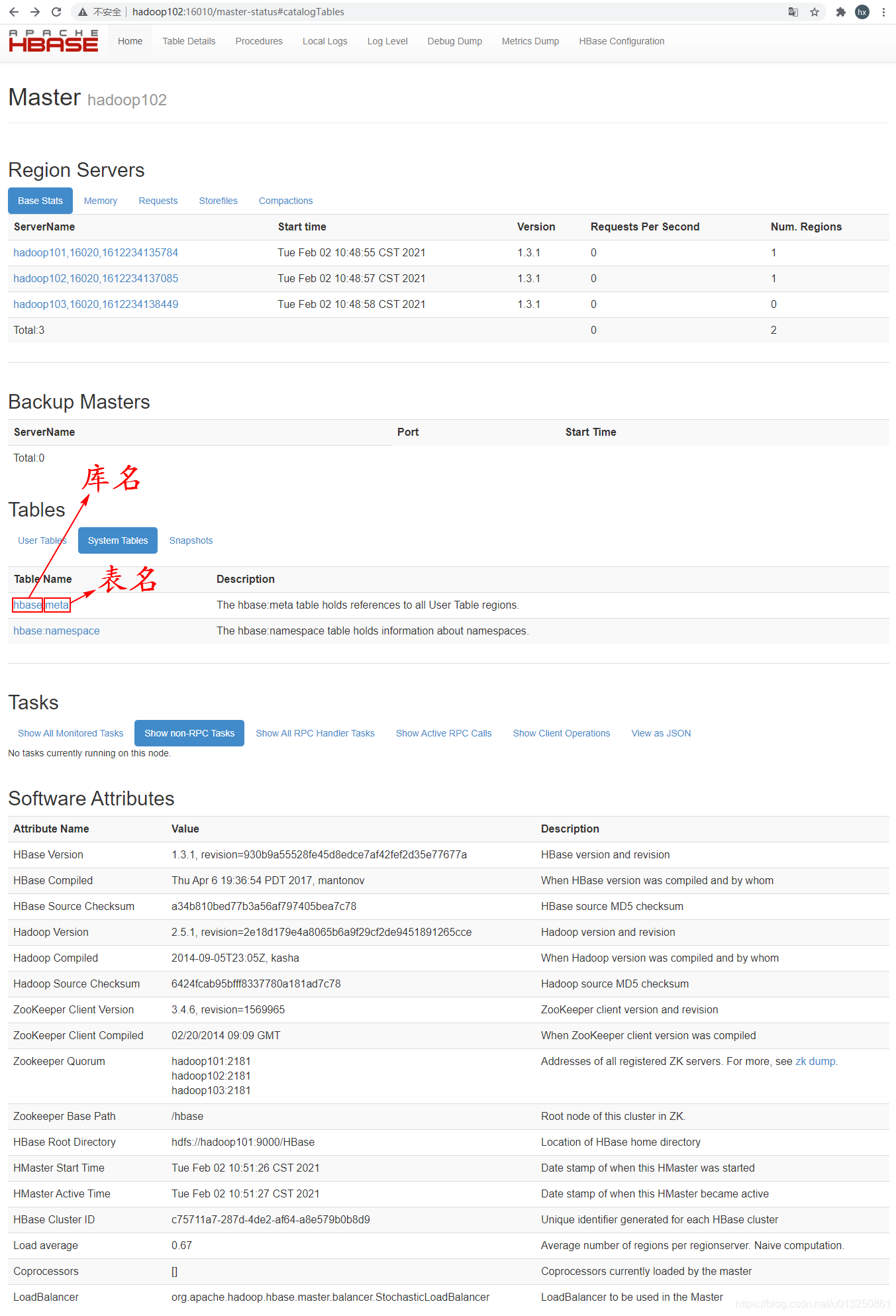
2.2 启动/停止方式二:群起/群停所有节点上的regionserver
hbase-daemons.sh、start-hbase.sh、stop-hbase.sh命令的前提:
- 先配置要执行这些命令所在的机器的 /opt/module/hbase/conf/regionservers文件。
- 在hadoop102节点的 /opt/module/hbase/conf/regionservers 配置文件中添加要群起的 regionserver 所在的节点主机名,将 regionserver 配置文件默认值 localhost 改为:
hadoop101
hadoop102
hadoop103
2.2.1 群起/群停所有服务器上的regionserver【hbase-daemons.sh命令】
群起所有服务器上的regionserver
[whx@hadoop102 ~]$ /opt/module/hbase/bin/hbase-daemons.sh start regionserver
hadoop102: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop102.out
hadoop101: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop101.out
hadoop103: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop103.out
[whx@hadoop102 ~]$
群停所有服务器上的regionserver
[whx@hadoop102 ~]$ /opt/module/hbase/bin/hbase-daemons.sh stop regionserver
hadoop102: stopping regionserver.....
hadoop103: stopping regionserver.....
hadoop101: stopping regionserver........
[whx@hadoop102 ~]$
2.2.2 群起/群停 master®ionserver【start-hbase.sh命令、stop-hbase.sh命令】
[whx@hadoop102 ~]$ /opt/module/hbase/bin/start-hbase.sh
starting master, logging to /opt/module/hbase/bin/../logs/hbase-whx-master-hadoop102.out
hadoop103: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop103.out
hadoop101: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop101.out
hadoop102: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop102.out
[whx@hadoop102 ~]$ xcall.sh jps
[whx@hadoop102 ~]$ /opt/module/hbase/bin/stop-hbase.sh
stopping hbase..................
[whx@hadoop102 ~]$
三、HBase数据库的使用
先在HBase数据库中创建一个测试表:whx_table
hbase(main):019:0> create 'whx_table','cf_user','cf_company'
0 row(s) in 1.2170 seconds
=> Hbase::Table - whx_table
hbase(main):020:0> desc 'whx_table'
Table whx_table is ENABLED
whx_table
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf_company', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'cf_user', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.0100 seconds
hbase(main):021:0>
向whx_table表中插入数据
hbase(main):027:0> put 'whx_table','1001','cf_user:firstname','Nick'
0 row(s) in 0.0470 seconds
hbase(main):029:0> put 'whx_table','1001','cf_user:lastname','Lee'
0 row(s) in 0.0150 seconds
hbase(main):030:0> put 'whx_table','1001','cf_company:name','HUAWEI'
0 row(s) in 0.0140 seconds
hbase(main):031:0> put 'whx_table','1001','cf_company:address','changanjie10hao'
0 row(s) in 0.0080 seconds
hbase(main):033:0> get 'whx_table','1001'
COLUMN CELL
cf_company:address timestamp=1612408142513, value=changanjie10hao
cf_company:name timestamp=1612408141461, value=HUAWEI
cf_user:firstname timestamp=1612408054676, value=Nick
cf_user:lastname timestamp=1612408141421, value=Lee
1 row(s) in 0.0200 seconds
hbase(main):034:0>
四、HBase与Hive的集成
1、HBase与Hive的对比
1.1 Hive
- 数据仓库:Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
- 用于数据分析、清洗:Hive适用于离线的数据分析和清洗,延迟较高。
- 基于HDFS、MapReduce:Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
1.2 HBase
- 数据库:是一种面向列存储的非关系型数据库。
- 用于存储结构化和非结构化的数据:适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
- 基于HDFS:数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
- 延迟较低,接入在线业务使用:面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
2、HBase与Hive集成
2.1 环境准备
首先保障环境变量文件 /etc/profile 文件中配备了 Hive、HBase的环境变量
HIVE_HOME=/opt/module/hive
HBASE_HOME=/opt/module/hbase
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin
export JAVA_HOME HADOOP_HOME HIVE_HOME FLUME_HOME HBASE_HOME PATH
2.2 创建软连接
因为我们后续可能会在操作Hive的同时对HBase也会产生影响,所以Hive需要持有操作HBase的Jar,那么接下来拷贝Hive所依赖的Jar包(或者使用软连接的形式)。在hadoop102服务器上执行以下命令,创建软连接:
ln -s $HBASE_HOME/lib/HBase-common-1.3.1.jar $HIVE_HOME/lib/HBase-common-1.3.1.jar
ln -s $HBASE_HOME/lib/HBase-server-1.3.1.jar $HIVE_HOME/lib/HBase-server-1.3.1.jar
ln -s $HBASE_HOME/lib/HBase-client-1.3.1.jar $HIVE_HOME/lib/HBase-client-1.3.1.jar
ln -s $HBASE_HOME/lib/HBase-protocol-1.3.1.jar $HIVE_HOME/lib/HBase-protocol-1.3.1.jar
ln -s $HBASE_HOME/lib/HBase-it-1.3.1.jar $HIVE_HOME/lib/HBase-it-1.3.1.jar
ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar
ln -s $HBASE_HOME/lib/HBase-hadoop2-compat-1.3.1.jar $HIVE_HOME/lib/HBase-hadoop2-compat-1.3.1.jar
ln -s $HBASE_HOME/lib/HBase-hadoop-compat-1.3.1.jar $HIVE_HOME/lib/HBase-hadoop-compat-1.3.1.jar
上面的命令是在$HIVE_HOME/lib 目录中创建 $HBASE_HOME/lib/中源文件的软连接,创建软连接替代jar文件的复制来避免服务器中的jar包冗余。
2.3 配置Hive的Zookeeper管理器
Hive读取HBase里的数据时,需要使用Zookeeper,所以在hive-site.xml中添加zookeeper的属性,如下:
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop101,hadoop102,hadoop103</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
添加后的hive-site.xml为:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<!--自定义Hive的数据仓库在HDFS中的位置。默认为:/user/hive/warehouse-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<!--实现显示当前数据库,以及查询表的头信息配置-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--Hive读取HBase里的数据时,需要用到Zookeeper-->
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop101,hadoop102,hadoop103</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
</configuration>
2.4 在Hive建表,该表需要与HBase中的数据进行映射
- 在建表时,Hive中的表字段的类型要和HBase中表列的类型一致,以避免类型转换失败造成数据丢失;
- row format 的作用是指定表在读取数据时,使用什么分隔符来切割数据,只有正确的分隔符,才能正确切分字段;
- 管理表(managed_table):由Hive的表管理数据的生命周期!在Hive中,执行droptable时,不仅将Hive中表的元数据删除,还把表目录中的数据删除;
- 外部表(external_table):Hive表不负责数据的生命周期!在Hive中,执行droptable时,只会将hive中表的元数据删除,不把表目录中的数据删除;
2.4.1 数据已经在HBase中的情况
数据已经在HBase中,只需要在Hive建表,查询即可
create external table hbase_t3(
id int,
age int,
gender string,
name string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:age,info:gender,info:name")
TBLPROPERTIES ("hbase.table.name" = "t3");
-
external 表示所创建的是外部表,因为此时的数据实在HBase里,而不是在Hive中。所以Hive只能创建外部表;
-
Storage Handlers是Hive的一个扩展模块,帮助Hive分析不在hdfs存储的数据。
- HBaseStorageHandler:存储在hbase上的数据可以使用Hive提供的对HBase的Storage Handlers(即HBaseStorageHandler)来读写HBase中的数据
- native table: 本地表。 Hive无需通过Storage Handlers就能访问的表。数据由hive负责存储,通常是存储在HDFS上。
- non-native table : 数据由其他框架存储,如果使用非本地表,在建表时,需要指定 stored by “storageHandler” 。Hive必须通过Storage Handlers才能访问非本地表。例如和HBase集成的表。
-
SERDE:SerDe是序列化器和反序列化器所在库的简写。SerDe的作用是在运行MR程序时,从输入目录中读取数据,反序列化为Mapper输入的key-value对象,或将Reducer写出的key-value对象,使用序列化存储到指定的输出目录中。输入目录或输出目录中数据的格式不同,就需要使用不同的SerDe。普通的文件数据,以及在建表时,如果不指定serde,默认使用LazySimpleSerDe!
- 纯文本: row format delimited ,默认使用LazySimpleSerDe
- JSON格式: 使用JsonSerde
- ORC: 使用读取ORC的SerDe
- Paquet: 使用读取PaquetSerDe
例如: 数据中全部是JSON格式
{"name":"songsong","friends":["bingbing","lili"]} {"name":"songsong1","friends": ["bingbing1" , "lili1"]}错误写法:
create table testSerde( name string, friends array<string> ) ROW FORMAT DELIMITED fields terminated by ',' collection items terminated by ',' lines terminated by '\n';如果指定了row format delimited ,此时默认使用LazySimpleSerDe,而LazySimpleSerDe只能处理有分隔符的普通文本。现在数据是JSON,格式{},只能用JSONSerDE
create table testSerde2( name string, friends array<string> ) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' STORED AS TEXTFILE -
WITH SERDEPROPERTIES (“hbase.columns.mapping” = “:key,info:age,info:gender,info:name”) 表示HBase与Hive之间字段的一对一对应;
Hive字段 HBase字段 备注 id :key :key 代表 HBase里的 rowkey,即使用 id 作为主键 age info:age info:age 表示 列族info里的age列 gender info:gender info:gender表示列族info里的gender列 name info:name info:name 表示列族info里的name列 -
TBLPROPERTIES (“hbase.table.name” = “t3”) 表示所创建的Hive表“hbase_t3”所对应的HBase表名为“t3”
2.4.2 数据还尚未插入到HBase的情况
数据还尚未插入到hbase,可以在hive中建表,建表后,在hive中执行数据的导入,将数据导入到hbase,再分析。
在Hive中创建表
CREATE TABLE `hbase_emp`(
`empno` int,
`ename` string,
`job` string,
`mgr` int,
`hiredate` string,
`sal` double,
`comm` double,
`deptno` int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,
info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "emp");
- 表必须是管理表(managed non-native table) ;
- WITH SERDEPROPERTIES (“hbase.columns.mapping” = “:key,info:ename,info:job,info:mgr,
info:hiredate,info:sal,info:comm,info:deptno”) 表示HBase与Hive之间字段的一对一对应;Hive字段 HBase字段 备注 empno :key 代表 HBase里的 rowkey,即使用 empno 作为主键 ename info:ename info:ename 表示 列族info里的ename列 job info:job info:job 表示 列族info里的job列 mgr info:mgr info:mgr 表示 列族info里的mgr列 hiredate info:hiredate info:hiredate 表示 列族info里的hiredate列 sal info:sal info:sal 表示 列族info里的sal列 comm info:comm info:comm 表示 列族info里的comm列 deptno info:deptno info:deptno表示 列族info里的deptno列 - TBLPROPERTIES (“hbase.table.name” = “emp”) 表示所创建的Hive表“hbase_emp”所对应的HBase表名为“emp”
使用insert向Hive的表里导入数据,导入的数据就保存在HBase里了。
insert into table hbase_emp select * from emp
向关联了HBase的Hive中导入数据不能使用load,因为load导入数据是一个put操作,而insert操作则会调用MapReduce向HBase里插入数据。
导入成功后:
- HBase做在的HDFS目录/HBase目录下就有了所插入的数据;
- Hive所在的HDFS目录/hive下会多一个hbase_emp空文件夹,里面没有数据;
2.5 Hive与HBase版本适配问题
| HBase版本 | Hive版本 | Hadoop版本 |
|---|---|---|
| 0.94 | 1.2.1 | ** |
| 1.3.1 | 2.x | 2.5.2 |
| 如果所用的Hive版本是1.2.1,而HBase的版本是1.3.1,则二者不匹配。 |
需要重新编译Hive(1.2.1) 的源码里的hive-hbase-handler-1.2.1.jar(因为只有这一部分不适配)。
- 将Hive的源码文件压缩包apache-hive-1.2.1-src.zip里的hbase-handler文件夹解压出来
- 将解压出来的hbase-handler文件夹导入到IntellJ里(Maven工程),导入时禁止pom.xml里的依赖自动下载;
- 创建一个与src目录同级的lib目录
- 在lib目录下放与HBase的1.3.1版本匹配的jar包
- 编译,将src重新打包成jiar包,名称依旧为hive-hbase-handler-1.2.1.jar,覆盖原来的hive-hbase-handler-1.2.1.jar
五、HBase的优化
1、HBase的高可用配置(配置多个HMaster)
在HBase中Hmaster负责监控RegionServer的生命周期,均衡RegionServer的负载。如果Hmaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对Hmaster的高可用配置。
- 关闭HBase集群(如果没有开启则跳过此步)
[whx@hadoop102 hbase]$ bin/stop-hbase.sh - 在conf目录下创建backup-masters文件
[whx@hadoop102 hbase]$ touch conf/backup-masters - 在backup-masters文件中配置高可用HMaster节点
hadoop101 hadoop102 hadoop103 - 将backup-masters文件分发到其他节点
[whx@hadoop102 conf]$ xsync.sh backup-masters - 重启HBase后,可以看到hadoop101、hadoop102、hadoop103都为HMaster,HBase会从3个HMaster中挑选一个作为Active状态,其余为Standby状态。
[whx@hadoop102 conf]$ /opt/module/hbase/bin/start-hbase.sh starting master, logging to /opt/module/hbase/logs/hbase-whx-master-hadoop102.out hadoop102: starting regionserver, logging to /opt/module/hbase/logs/hbase-whx-regionserver-hadoop102.out hadoop101: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop101.out hadoop103: starting regionserver, logging to /opt/module/hbase/bin/../logs/hbase-whx-regionserver-hadoop103.out hadoop103: starting master, logging to /opt/module/hbase/bin/../logs/hbase-whx-master-hadoop103.out hadoop101: starting master, logging to /opt/module/hbase/bin/../logs/hbase-whx-master-hadoop101.out hadoop102: master running as process 8814. Stop it first. [whx@hadoop102 conf]$ xcall.sh jps 要执行的命令是jps ----------------------------hadoop101---------------------------------- 6032 HMaster 5621 DataNode 6213 Jps 5501 NameNode 5773 QuorumPeerMain 5903 HRegionServer ----------------------------hadoop102---------------------------------- 9304 Jps 8984 HRegionServer 8601 QuorumPeerMain 8301 DataNode 8814 HMaster ----------------------------hadoop103---------------------------------- 6210 SecondaryNameNode 6085 DataNode 6328 QuorumPeerMain 6841 Jps 6462 HRegionServer 6591 HMaster [whx@hadoop102 conf]$ - 通过Web浏览器,输入 hadoop102:16010,可以通过hadoop102查看HMaster信息
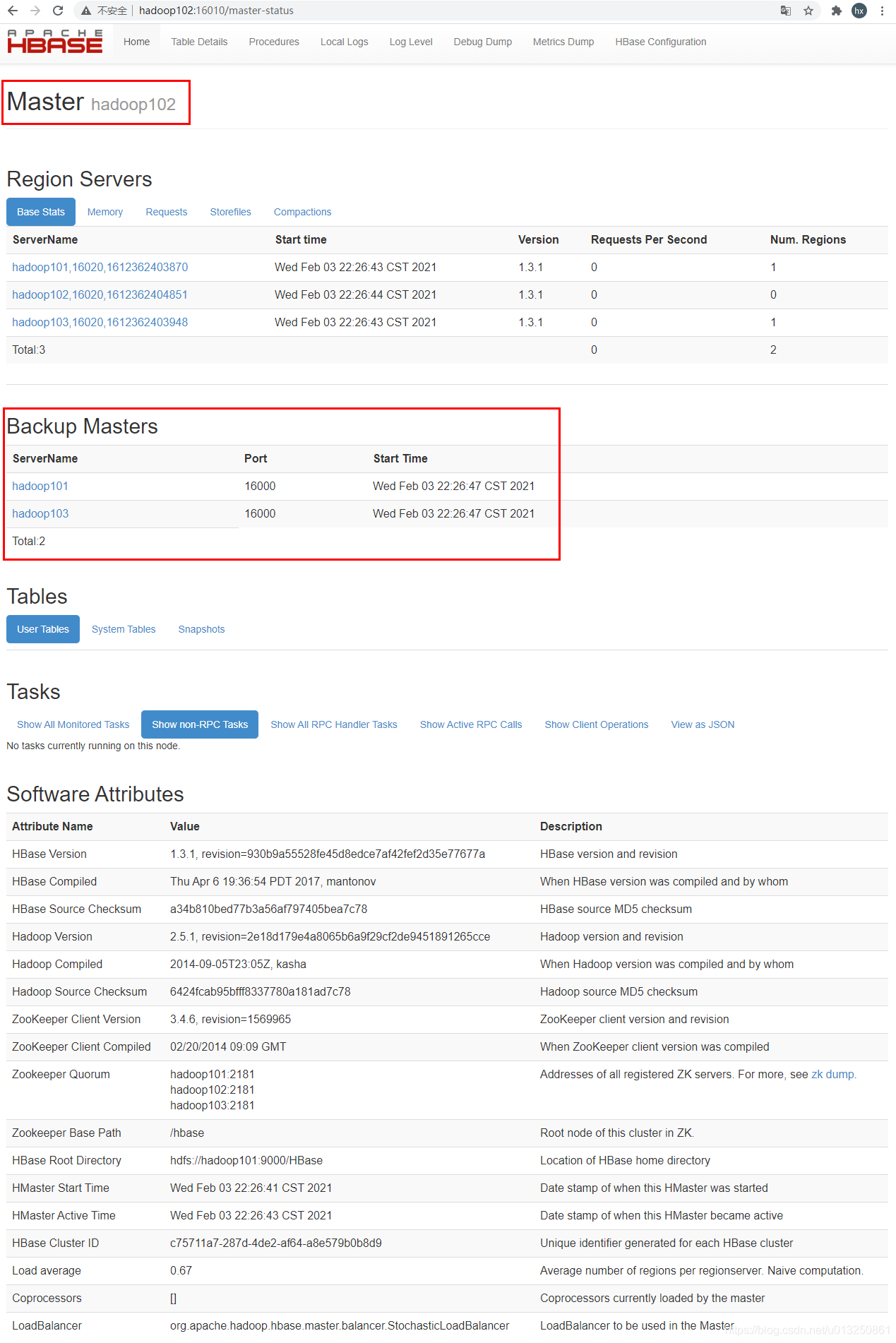
- 通过Web浏览器,输入 hadoop101:16010,可以通过hadoop102查看HMaster信息
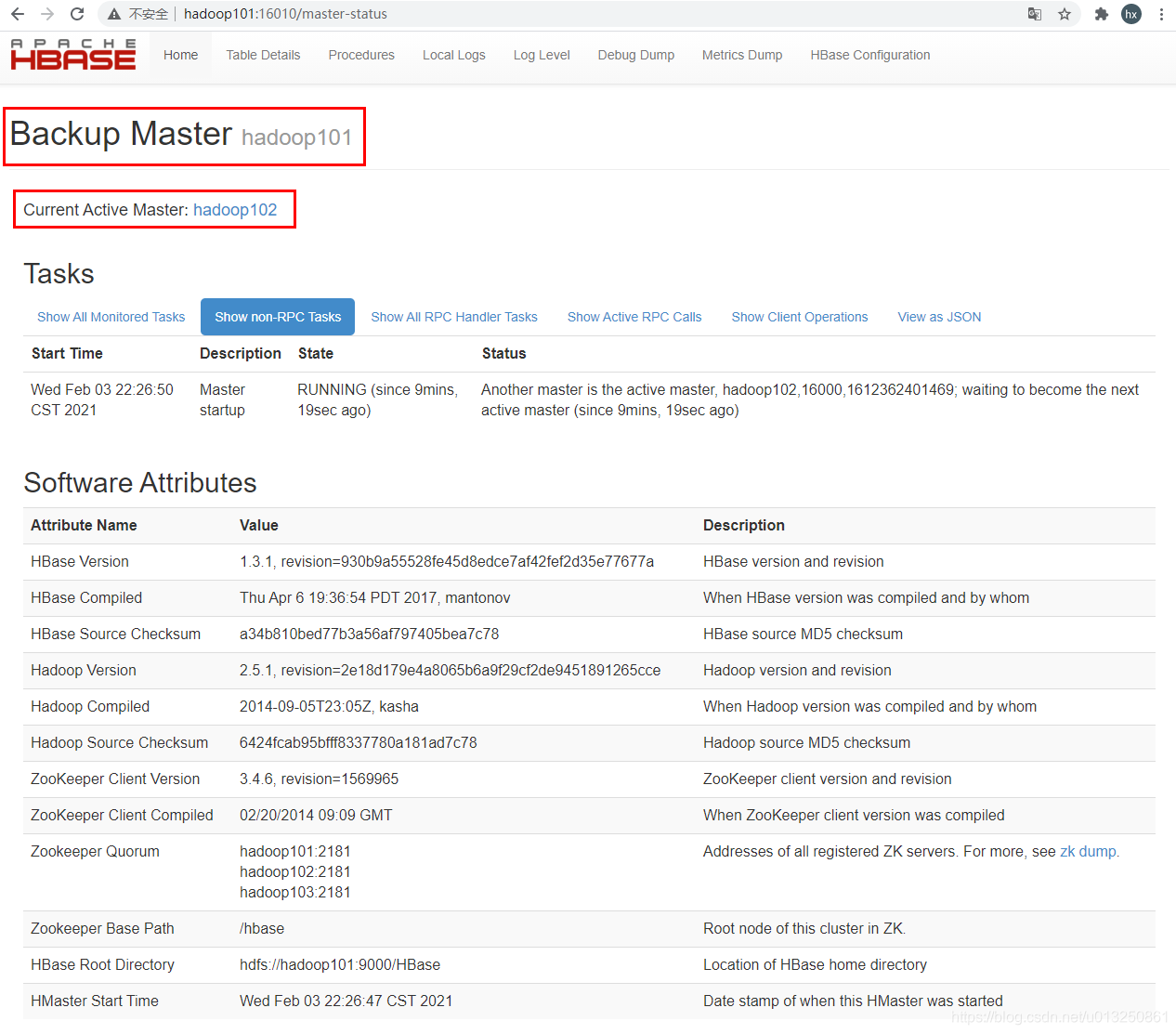
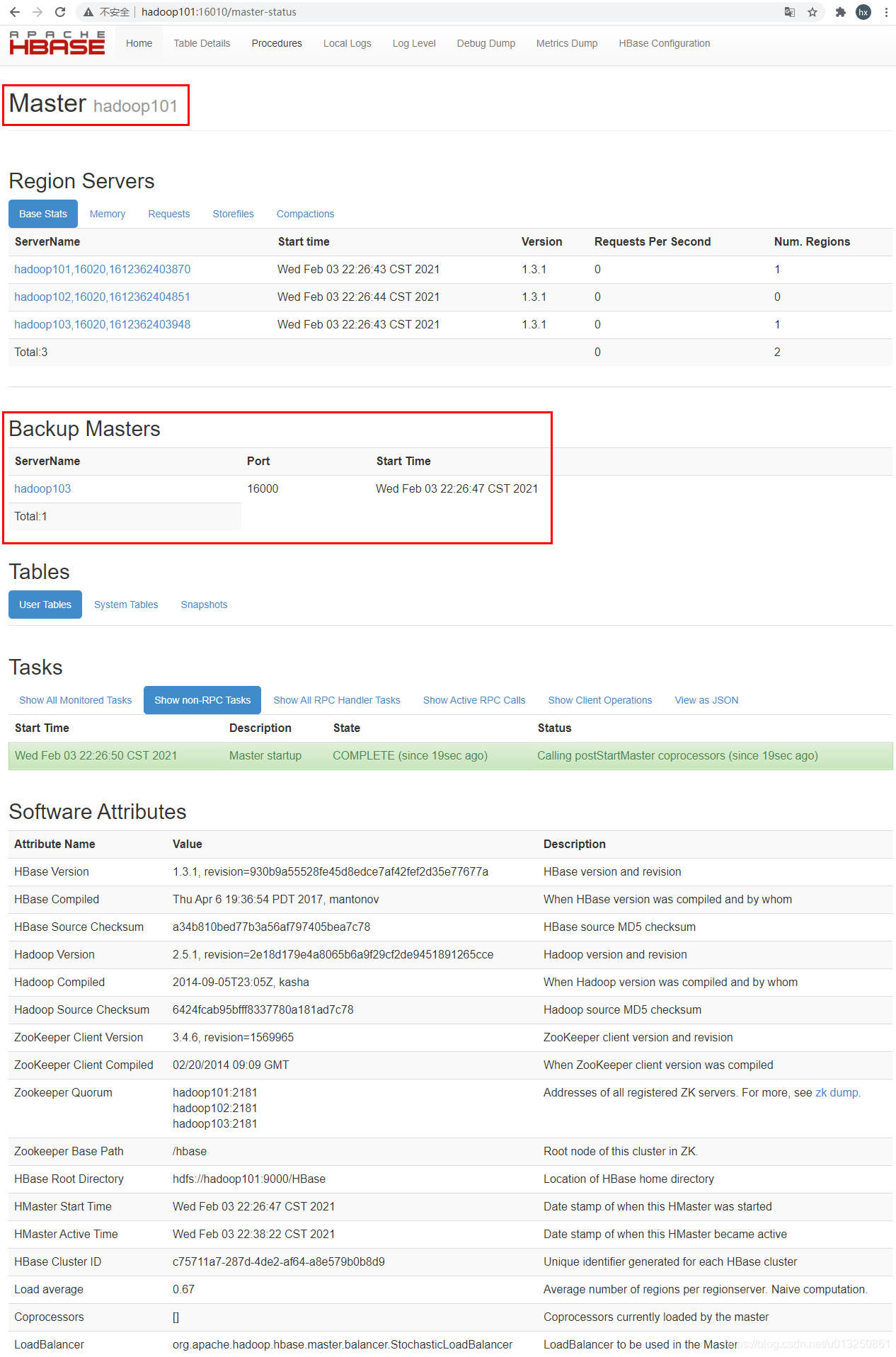
- 模拟处于Active状态的HMaster所在的节点hadoop102出现故障
此时,hadoop101由Standby状态变为Active状态,hadoop102节点的HMaster进程即使恢复,hadoop102也只能为Standby状态[whx@hadoop102 conf]$ xcall.sh jps 要执行的命令是jps ----------------------------hadoop101---------------------------------- 6032 HMaster 5621 DataNode 6213 Jps 5501 NameNode 5773 QuorumPeerMain 5903 HRegionServer ----------------------------hadoop102---------------------------------- 9304 Jps 8984 HRegionServer 8601 QuorumPeerMain 8301 DataNode 8814 HMaster ----------------------------hadoop103---------------------------------- 6210 SecondaryNameNode 6085 DataNode 6328 QuorumPeerMain 6841 Jps 6462 HRegionServer 6591 HMaster [whx@hadoop102 conf]$ kill -9 8814 [whx@hadoop102 conf]$
2、预分区
通常情况下,每次建表时,默认只有一个region!随着这个region的数据不断增多,region会自动切分!
- 自动切分: 讲当前region中的所有的rowkey进行排序,排序后取start-key和stopkey中间的rowkey,由这个rowkey一分为二,一分为二后,生成两个region,新增的Region会交给其他的RS负责,目的是为了达到负载均衡,但是通常往往会适得其反!
- 为例避免某些热点Region同时分配到同一个RegionServer,可以在建表时,自己提前根据数据的特征规划region!
- 每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。
- 如果使用HexStringSplit算法,随机生成region的边界。在插入一条数据时,rowkey必须先采取HexString,转为16进制,再插入到表中。
2.1 预分区方式①:手动设定预分区
HBase> create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']
2.2 预分区方式②:生成16进制序列预分区
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
2.3 预分区方式③:按照文件中设置的规则预分区
创建splits.txt文件内容如下:
aaaa
bbbb
cccc
dddd
然后执行:
create 'staff3','partition3',SPLITS_FILE => 'splits.txt'
2.4 预分区方式④:使用JavaAPI创建预分区
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建HBaseAdmin实例
HBaseAdmin hAdmin = new HBaseAdmin(HBaseConfiguration.create());
//创建HTableDescriptor实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过HTableDescriptor实例和散列值二维数组创建带有预分区的HBase表
hAdmin.createTable(tableDesc, splitKeys);
3、RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内。
设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。
3.1 RowKey常用的设计方案①:生成随机数、hash、散列值
原本rowKey为1001的,SHA1后变成:dd01903921ea24941c26a48f2cec24e0bb0e8cc7
原本rowKey为3001的,SHA1后变成:49042c54de64a1e9bf0b33e00245660ef92dc7bd
原本rowKey为5001的,SHA1后变成:7b61dec07e02c188790670af43e717f0f46e8913
在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的rowKey来Hash后作为每个分区的临界值。
3.2 RowKey常用的设计方案②:字符串反转
时间戳的反转:
20170524000001转成10000042507102
20170524000002转成20000042507102
这样也可以在一定程度上散列逐步put进来的数据。
3.1 RowKey常用的设计方案③:字符串拼接
20170524000001_a12e
20170524000001_93i7
使用字符串拼接设计Rowkey,原则:
- Rowkey作为数据的唯一主键,需要紧密和业务相关,从业务中选择某个代表性的字段作为Rowkey
- 保证Rowkey字段选取时的唯一性,不重复性
- Rowkey足够散列,负载均衡
- 让有业务关联的Rowkey尽量分布到一个Region中
例如: 转账的场景
| 流水号 | 转入账户 | 转出账户 | 时间 | 金额 | 用户 |
|–|–|–|–|–|–|–|
| *** |*** |*** |*** |*** |*** |
流水号适合作为RowKey,将流水号再拼接字符串,生成完整的RowKey
格式:
- 流水号+时间戳
- 时间戳+流水号
- 流水号+随机数
- 随机数+流水号
如果流水号在设计时,足够散列,可以使用流水号在前,拼接随机数。
如果流水号不够散列,可以使用函数计算其散列值,或拼接一个散列的值。
举例:如何让一个月的数据,分布到同一个Region!可以取月份的时间,作为计算的参数,使用hash运算,将运算后的字符串,拼接到Rowkey前部。
4、内存优化
-
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给HBase的Java堆。但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~48G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
-
在/opt/module/hbase/conf/hbase-env.sh 中,编写regionserver进程启动时的JVM参数!
- -Xms : JVM堆的起始值
- -Xmx : JVM堆的最大值
- export HBASE_HEAPSIZE=1G 或 export HBASE_OPTS=“-XX:+UseConcMarkSweepGC”
5、基础优化
5.1 允许在HDFS的文件中追加内容(hdfs-site.xml、HBase-site.xml)
- 属性:dfs.support.append
- 解释:开启HDFS追加同步,可以优秀的配合HBase的数据同步和持久化。默认值为true。
此处dfs.support.append如果设置为false,则HBase的所有功能则没法实现。所以一定设置为true。
5.2 优化DataNode允许的最大文件打开数(hdfs-site.xml)
- 属性:dfs.datanode.max.transfer.threads
- 解释:HBase一般都会同一时间开启大量IO线程来操作大量的文件,根据集群的数量和规模以及数据动作,设置IO线程数量为4096或者更高。默认值:4096
5.3 优化延迟高的数据操作的等待时间(hdfs-site.xml)
- 属性:dfs.image.transfer.timeout
- 解释:如果对于某一次数据操作来讲,延迟非常高,socket需要等待更长的时间,建议把该值设置为更大的值(默认60000毫秒,即1分钟),以确保socket不会被timeout掉。
- 比如:如果项目是一个高并发场景,而且RegionServer的性能也不是很好,可以把参数调大一些,防止数据操作失败。
5.4 优化数据的写入效率(mapred-site.xml)
- 属性:
- mapreduce.map.output.compress
- mapreduce.map.output.compress.codec
- 解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec或者其他压缩方式。
5.5 设置RPC监听数量(hbase-site.xml)
- 属性:HBase.regionserver.handler.count
- 解释:默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
5.6 优化HStore文件大小(hbase-site.xml)
- 属性:HBase.hregion.max.filesize
- 解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
5.7 优化HBase客户端缓存(hbase-site.xml)
- 属性:HBase.client.write.buffer
- 解释:用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
5.8 指定scan.next扫描HBase所获取的行数(hbase-site.xml)
- 属性:HBase.client.scanner.caching
- 解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
5.9 flush、compact、split机制
当MemStore达到阈值,将Memstore中的数据Flush进Storefile;compact机制则是把flush出来的小文件合并成大的Storefile文件。split则是当Region达到阈值,会把过大的Region一分为二。
- HBase.hregion.memstore.flush.size:134217728
即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。 - HBase.regionserver.global.memstore.upperLimit:0.4
- HBase.regionserver.global.memstore.lowerLimit:0.38
即:当MemStore使用内存总量达到HBase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于lowerLimit
六、HBase中设置布隆过滤器
HBase中通过“列族”设置过滤器,HBase支持两种布隆过滤器: ROW|ROWCOL
注意: 旧版本,只有get操作,才会用到布隆过滤器,scan用不到! 1.x之后,scan也可用用布隆过滤器,稍微起点作用!
启用布隆过滤器后,会占用额外的内存,布隆过滤器通常是在blockcache和memstore中!
1、ROW布隆过滤器
ROW布隆过滤器在计算时,使用每行的Rowkey作为参数,进行判断。举例:info1列族、info2列族:
- info1 storefile1: (r1,info1:age,20) ,(r2,info1:age,20)
- info2 storefile2: (r3,info2:age,20) ,(r4,info2:age,20)
查询 r1 时,如果命中,判断storefile2中一定没有r1的数据,在storefile1中可能有!
2、ROWCOL布隆过滤器
ROWCOL 布隆过滤器在计算时,使用每行的rowkey和column一起作为参数,进行判断!举例: info info1
- info1 storefile1: (r1,info1:age,20) ,(r2,info1:age,20)
- info2 storefile2: (r3,info2:age,20) ,(r4,info2:age,20)
查询rowkey=r1,只查info1:age=20 列时,如果命中,判断storefile2中一定没有此数据,在storefile1中可能有!
3、举例: 执行 get ‘t1’,‘r1’
-
扫描r1所在region的所有列族的memstore,扫memstore时,先通过布隆过滤器判断r1是否存在,如果不存在,就不扫!可能存在,再扫描!
-
扫描Storefile时,如果storefile中,r1所在的block已经缓存在blockcache中,直接扫blockcache,在扫描blockcache时,先使用布隆过滤器判断r1是否存在,如果不存在,就不扫!可能存在,再扫描!
七、HBase在商业项目中的能力(每天)
-
消息量:发送和接收的消息数超过60亿
-
将近1000亿条数据的读写
-
高峰期每秒150万左右操作
-
整体读取数据占有约55%,写入占有45%
-
超过2PB的数据,涉及冗余共6PB数据
-
数据每月大概增长300千兆字节
参考资料:
分布式NoSQL列存储数据库HBASE(二)














 4100
4100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









