






其实使用python模拟浏览器完成一系列的操作,这里去实现大部分的自动化,自动代替我完成一些操作。例如录入,写博文,发表。
自己的毕业设计,也可以做成这个样子的,首先完成一个爬虫,这里python的研究,爬虫的研究,在这里可以添加网页解析的框架,多线程爬取的框架。python基于Django搭建一个web页面,然后可以把爬下来的内容展示在web页面上。
今天的任务
昨天完成了爬取两个页面的数据,今天继续看看到底是怎么爬取到的,构造了什么?
尝试爬取博客上面的内容
爬取下来后,进行正则匹配,筛选出自己需要的内容
我的这10年——从机械绘图 到 炼油 到 微软MVP 的华丽转身
http://www.cnblogs.com/asxinyu/p/CareerChangeAndConclusion.html
阅读目录
年底了,各种总结计划满天飞,有空的时候我也一直在思考这么多年,是怎么过来的。也曾经很迷茫,希望经验和经历能给大家一点带来一点正能量的东西。10年很长,10年前说实话我没有思考过现在的样子,但10年前的日子还历历在目。
回忆这10年,简单的总结一下:从一个机械设计绘图工程师 到 润滑油炼油工程师 到 国内最牛逼的快递企业之一(美国纽交所上市)IT信息中心担任开发项目经理,从一个Matlab代码爱好者成长为 微软全球最有价值专家(MVP),IT技术见证了我的成长。
且听我慢慢分解我的这10年的华丽转身。
1.第一次转身—考研
1.1 大学的美好时光
2003年上大学,由于和第一批次差了2分,又不想复读,稀里糊涂填了个专业:机械设计制造及其自动化(简称机自),就这样来到了湖北工业大学读了4年。大学期间还是勤勤恳恳,每天泡图书馆,机房,由于数学成绩非常好(数学类课程平均分97),所以优势比较多,再加上其他一点特长,混起来很爽,可以说大学是如鱼得水,包揽了3年的一等奖学金(大四没奖学金了)以及各种优秀。2016年国庆节回去,老爸从柜子里把获奖证书的壳子拿出来,我还洗了洗,堆起来,半米高。。。
大二开学,由于文化课成绩出色,学分绩点全校30名左右(那一届大概有4000人吧),班级第一可以全校任意选专业,当时很兴奋,由于大一下学期学了C语言,感觉这玩意太神奇了,就想转计算机专业,结果被班主任叫去说,我们专业全校就业率第一(工科学校的优势专业),还转啥,好好学,都一样的。我也稀里糊涂那就这样吧,我自己也拿不准。就这样第一次错过了计算机专业。
真的转折点是由于数学成绩不错,参加全校数学竞赛,当然要和数学专业的比一比,成绩还不错,顺利突围,拿到了2004年全国数学建模竞赛的入场券,经过半个月的集训,主要是Matlab使用和解决问题的思路,一时间突飞猛进,对这玩意是着迷了。那一年建模竞赛成绩一般,湖北省二等奖,比鼓励奖是好多了的最低奖,毛估估前省二等奖及以上的获奖比例是20%左右,那一年,时间太久记不清了,好像就我们一个组拿到了奖,其他全军覆没,甚是尴尬,一方面学校师资,指导也有限,还有几个数学专业的队伍。我也认识到自己还有这方面的优势,所以一直在提高自己的编程能力。
学会使用Matlab编程后,加上数学建模的抽象能力,让我在后面很多地方大展身手,在那个时候还是不多见的。别人用计算器做课程设计(很多复杂的机械设计公式计算),我就设计和开发了自动化的程序,一键生成所有结果和报表,打印出来后老师也震惊了,最后还给一帮人校验数据,计算机太快太准确。。。这就是我一直遵循的 实践驱动学习,这个过程很锻炼,很有用,可惜我机械设计绘图啥能力很差,有一个画减速箱的课程设计,我把内壁和外壁画在一条线上,还看起来挺像,老师看了好久,说你这个图不对劲啊,但一时半会说不出来,哈哈,一堆人围在哪里,最后说你这外壁和内壁是怎么画到一起的。。。。我靠,我自己也看不懂,当时那个尴尬,室友还帮我检查了好几遍,结果重画,可苦了。。。
1.2 大学考研之转变
大四上学期已经决定要考研了,思索很久,一方面基础课成绩不错,有优势,而且我是实在想不出以后我出去搞机械设计能干啥,没这个天赋。。。还是决定考吧,考啥呢,思考了很久,决定找一个计算机相关的专业,可是计算机专业专业课要求太高,数据结构,系统原理啥都很不懂,怎么办呢,到处找学校的过程中,发现了一个 上海理工的系统分析与集成 专业,考验专业课是 概率论,这可是强项,先进去再说吧,谁说得清以后怎么样呢,到哪里还得看自己的。就这样经过几个月的痛苦复习,考研360分,顺利进入上理工研究生院,还是公费。这是我这些年唯一占了国家便宜比较多的地方,每个月还有230块的补贴,够吃一个月蛋炒饭的。
读研导师见面,选方向,我的导师是搞理科,研究数学最优化方面的,公式那个吓人,当时那个尴尬,吓死我了。。。不过他说我比较特殊,说有一个年轻的导师第一年带研究生,面试的时候就看中了我以前大学和毕业设计的计算机背景,暂时只是挂靠到他名下,那个导师的一些手续还没办好,当时悬着的心算是落下了。后来才知道,这个导师非常厉害,是众多本校保研和考研想投靠的对象,可惜我是开门弟子,就复试面试的时候确定了就带我一个。后来我选择的方向是"信息安全-密码算法研究",就这样我一个机械绘图的,转眼间就要投身神神秘秘的加密算法研究,感觉好高大上,实际上当时根本没有考虑就业等因素,后来毕业才知道,这玩意找对口工作比机械设计还难。。。就这样黯然开启3年的研究生生涯。
大学还有一件不得不说的事情,就是2005年下半年阴差阳错选了一门选修课 C#.NET,第一节课,老师用VS做了个播放器,瞬间惊呆了。。。。然后的时间泡在图书馆的C#书籍中。。。不过都是理论和小程序,没有实践做过大项目,为10年后埋下了伏笔。
2.第二次转身—炼油
2.1 研究生的历练
研究生期间,虽然以前专业基础不强,但数学基础,逻辑思维都还可以,所以经过半年的基础补习,很快就入门了,但是怎么选择课题的任务导师交给我了,自己找个课题,对我来说,真的是万幸,因为有足够的自由和空间,最后我选择的是 基于混沌的流密码研究,经过1年的努力,密码算法设计,安全测试都自己用C#代码写了一遍,算法和写代码的功底大大增强,这在读研的时候也是一个很明显的优势,一年下来,发表了3篇论文(2篇核心期刊的有点技术含量,一篇会议是真的打酱油凑数),而且毕业论文的大部分工作都做完了,所以读研是比较轻松的搞定了。读研期间,朋友推荐在一个软件公司搞系统维护,业务时间给几家公司维护系统和网络,赚点生活费,就是装系统,装打印机,解决网络共享等蛋疼的问题,其实很多都是临时百度,一回生二回熟。。。现在想起来都不敢说自己会装系统,真怕了。读研三开始陆续在一些论坛逛,发现了一些外包的活,收益可观,第一次实战是给一个软件公司做一个Excel翻译插件,用的是VSTO,要集成一些vba脚本,坑爹的excel 2003和xp补丁,把我折腾得死去活来。虽然项目最后很成功,暑假花了2个星期,,至此之后再也不碰VSTO,不敢玩了。这个项目也是第一次比较正规的实战,解决问题的过程翻遍了国内外论坛和微软官方资料,英文资料也是啃了一堆又一堆,后来拿钱闪人了,由于公司付款不及时,我催款的时候还有点不耐烦,初来乍到,不知道这么玩,还好我也是学加密算法的,给他搞了个到期不能用,留了一手。
2.2 炼油的那些日子
2010年,又到找工作的季节,读研几年也看到读博是没啥前途了,也是农村出来的,不能让父母老操心,虽然读研后没找父母要过钱,但总归要给他们点希望。各个招聘会也去跑了一下,投的都是开发测试岗位啥,发现每一个收留的,后来经人介绍,有一个创业公司,不过是做润滑油的,关系有点复杂就不说了,看起来还比较有前景,基于各方面考虑,打算还是拼一下,而且IT技术也用得上,所以毕业后直奔宁波,去了当然是各种困难,公司投资大,有一些核心技术,发展蒸蒸日上,我去了是最高学历,但职位是技术员,刚开始负责DCS系统的维护,后面又做化验员,化验室主管,销售没人,继续开拓市场,各方面信息缺乏,只要又冲上去干了一阵子,最后公司稳定后,又回来搞技术,润滑油调和配方,实验方案等等。。。摸爬打滚,起早摸黑,那个日子是真他妈辛苦,润滑油实验环境条件艰苦,又脏又累,最后技术质量部成立后,担任经理,算是轻松了一些,陪领导做做方案,负责化验,产品配方等工作,一线啥都干过,啥都清楚,所以很清闲。
由于润滑油市场这个特殊行业被过国企垄断,虽然也有些路子,但各方面环境不好,导致企业效益一直不理想,直到2014-2015年国际油价狂泻不止,压力巨大,公司停工一年,每天吓折腾,其中也有很多其他因素,就不一一说了。在润滑油行业干了5年,很宝贵,虽然工作是润滑油,但还是没有放弃IT,一方面自己业余时间还是跟随技术潮流,每天逛逛博客园,信息量很大,至少没有落伍,一方面企业发展也需要一些IT技术支持,虽然都很小,但也让我有些进步。例如刚到销售部,急需客户资料,靠人工每天复制太累了,我就花时间做了个管理软件,直接从阿里巴巴采集全国各地的客户资料,然后业务员从系统里面进行联系和维护,相当于一个简易版的 客户管理系统;化验过程有很多复杂的计算,靠计算器出错几率大,而且慢,同时化验员文化水平低,怎么办,那就做软件,研究了国家标准和文献,做了一个简易版的化验室常规计算以及油品配合调和工具,这样简单了,好用,40多岁的大姐也会玩了,工具可以加快配方调和的速度,快速出方案;后来各种检测数据太多,靠纸质维护,没有参考性和可比性,我又用开源的工具做了一个简易版的实验室数据管理系统,BS的,这样每天化验员前台录入数据,领导和我自己查数据,管理就方便多了,至今运行稳定。。。数据量不大,界面也很丑,但实用是最大的目标。
再加上平时研究开源比较多,时间空闲经常写写文章,总结一下,并在2014-2015年开始做足球赛事数据和预测方面的研究,有些成果,开发能力也有些提升,在决定辞职后,找了几家单位,本来想去杭州一家互联网公司的,同时阴差阳错一直认识吉日嘎拉老师,听说他在杭州,打听了一下杭州的情况,结果他就建议我去上海看一下,搞快递的,他们也缺人,机会也很多,吉日老师也很诚恳,来不来没关系,来看看再说,这样我请假就去面试了,先去杭州,顺便第二天去了上海,到现在的公司看了看,这边领导也极力认可,回来后,对比了一下,杭州的互联网公司正好碰上行业整顿,一直没业务,所以也不紧张,我也急需想换个环境,所以就选择了现在的快递行业,转来转去,2015年,5年后,大上海我又回来了。。。
又一次转身,这一次很多人认为非常遗憾,也许单位再熬几年,也很轻松。。。但人生就是不断的冒险和调整,×××逸了,会消磨自己,这一次转身,我也很犹豫,怕自己做不好,毕竟这是一个曾经梦想但实际没来过的行业。。。
3.第三次转身—程序猿
就这样虽然放弃了5年的行业,但经验都是通的,自己有成长才是真的重要。来到新公司,这个数据量和业务让我很吃惊,一方面以前没这么大数据量,一方面自己的全栈开发能力太弱,还好新来吉日老师给我安排的工作是我擅长的后台数据统计。还好技术功底不错,经过过这么多行业,抽象能力以及自己在研究足球数据方面积累了一些架构能力,经过几个月的努力,新项目顺利上线,这是一个全新的挑战和进步,具体技术方面就不说了,经历了双十一高峰期业务量的考验,为上级提供数据决策支持。由于业务发展需求,以及自身积累的技术力量,我的团队也不断壮大,我也从程序猿走到了项目经理的角色,对几个关键的统计系统进行重构,虽然代码没写那么多了,但各个技术角角落落,从产品,需求,开发,测试和上线,维护都全程参与。。。
其实只要我们用心,每个脚印都会是冥冥之中的安排,来了现在公司也是缘分,因为认识吉日嘎拉也是缘分和巧合,在进入公司1个月后,我意外收到了 来自微软总部的 "全球最有价值专家大礼包" ,由于自己失误,邮件直接进垃圾箱。意外,也是惊喜,这一刻,是我开始认识C#的第10年,刚好10年。。。有人说,种一棵树最好的时间是10年前,其次是现在。。10年前的种子现在发芽了,谁知道10年后发生什么呢,努力,一切皆有可能!2016年10月,如期收到了微软官方"全球最有价值专家"的连任邮件,从一年级新生到二年级老兵,目标是向10年老兵看齐。
现在开发工作越来越少了,也带了一些新人,在慢慢教他们思维习惯,培养团队氛围,这几个月下来,发现管理团队的确是比较累人,自从少写代码,失眠都多了, 虽然在上一家公司,下面也有10多个人的团队,但是文化水平,制度,业务要求都和现在相差太远。压力更大了,上面要打通各个部门的沟通和做好需求,一旦走偏,影响业务,是非常严重的,一方面新人要培养,技术要进步,项目要上线,会有各种问题,各种折腾。
4.这些年的感悟
说说经历这么多蛋疼的事情的一些感悟吧,对技术人员是个参考,对大家也是个鼓励,经验是个人的,每个人环境,成长,特长不一样,不一定都适用,终究是找准自己的方向,然后拼命干。
4.1 业务驱动技术,提高解决问题的能力
没有学过专业的计算机课程体系,也没有受过专业的软件开发培训,我的经验基本都来自于实践,通过良好的数学基础和抽象能力,把编程作为一个工具,来解决实际问题。在解决问题的过程中,会碰到大量的问题或者开发问题,就要借助搜索引擎,要站在巨人的肩膀上,这样才能看得更远(解决自己的问题)。比如在前面提到的做实验室石化计算工具,并不是那么简单,需要数学插值拟合算法,通过分段函数拟合公式,来进行计算;在采集阿里巴巴客户数据的时候,用到开源的组件,要学会XPath语法,要学会去查找组件提供的一些接口函数,不断调整满足自己的要求;不懂数据库,大学的时候自学考试过三级数据库技术(很多同学考三级网络技术,死记硬背,作为考证的工具),我是想以后自己有点作用,后来不断自学找到入门之道,再后来,学会使用ORM工具,直接在代码层面解决绝大部分数据库操作(这个时候性能并不是我最主要考虑的因素,想一下现在的硬件条件,处理一个每天几百条数据的系统,ORM足够解决问题),当然并不是说数据库性能不重要,是要在合适的时候,在有限的精力下面做合适的事情(现在公司每日处理千万级的订单数据,数据记录5千万+,就需要各个环节考虑性能问题)。
如果有时间可以多学点技术,如果没时间,那就从现有的工作中来学习,不要犯重复错误,尽量总结,举一反三,这样才能不断积累解决问题的能力,同时也要逐步接触新知识,新技术,可能刚开始很痛苦,但这也是学习过程,遇到问题就解决,哪怕后来不用,很多解决问题的过程都是值得学习的。
4.2 投资自己:时间+汗水+人民币
为什么投资自己?给自己投资什么呢?
首先我认为是时间。想要比别人更强,那就要拿出宝贵的时间,甚至业余的时间。时间挤挤总归有的,如果不花费时间,其他都白搭,一定要在关键时候沉下心来研究技术,当然上班就不用说了,要把自己的工作做好。以前在老单位的时候,长期停工,每日工作任务有限,上班1-2个小时完成所有的工作后,别人可能看看新闻,打打游戏,炒炒股,我就在写写代码,领导并没有要求我一定要做个系统啥,奉献自己也会收获自己的东西。在帮助自己,帮助网友解决问题的过程中,也会学到很多东西。有一次台风来了,工厂需要值班,台风没来就只能坐在办公室等着,正好碰到一个朋友要做一个考试题库学习的软件,正好没事,花了一个晚上,就做了个Demo,后来有空优化了一下,还是比较好用的,虽然不是个啥商业工具,但很快做出来,并不是几个人能做,每一件事情都有着存在的意义,不是现在,也许是很久以后。所以投资你的业余时间,不要让时间浪费;
其次是付出汗水。光有时间,不加把劲怎么行,有没有坚持不懈的钻研精神,有没有不到黄河心不死的气魄,坚持,加加班,努努力,柳暗花明又一村的时候是很爽的。
有时候也要付出人民币。2010年刚毕业的时候,吉日嘎拉老师的权限管理组件刚开始商业化,我正好看到博客,研究了很久,觉得很好玩,很有用。虽然那个时候学习版很便宜,我还是把我半个月蛋炒饭的钱给拿出来了买了份源码,对我这一生的职业来说,绝对是个奇迹,虽然我没并有把权限管理实际使用,但源代码经常拿出来看看,学到了不少东西,有时候甚至直接扣代码出来。后来还在他的群里搞了个简单的算法问题,3倍回报瞬间收回,5年后,我想换工作,阴差阳错的让吉日知道后,介绍我来现在单位,到现在一切顺风顺水,可以说我的职业转换成功,离不开吉日的帮助。非常感谢,所以关键时候投资点东西,若干年以后或许有些意想不到的回报。2016年,我也在开始关注微软Power BI技术,对一些基础技术也恶补了一下,花钱报了一些课程,一共报了3门课程,2门收货很大,顺利完成各种作业,从头到位,有一门monogdb的课程要求高一些,设计到数据库维护层面的东西,没时间学习,自己是想学的,只学了几节课,太偏DBA和运维方向,后来跟不上了,总的来说虽然花钱了,但感觉到值。2017年,我在天善智能社区报了一个SVIP的会员,明年可以看各种团购视频,有一些是非常不错的,学习别人的经验,关键点是很重要的,也许现在1-2年可能看不到效果,但我相信也许某一天会有作用。不是没机会,是机会来了的时候,你准备好了吗?所以适当的投资有必要。
4.3 发挥长处,补齐短板,逆境中成长
很多人说木桶原理,你的高度不是取决于最长的那一块,而是最短的那个地方。实际上是比较扯的,要辩证的看这个问题。对大公司,大团队来说,各个环节当然要平衡。但是具体到个体,就应该分工合作。我认为一个团队总体各个技术方向技术能力要平衡,但每个人都首先要发挥自己的长处,在做好自己本职工作的基础上,加强学习,补齐短板,这样不断进步。我的技术能力虽然每个方向不够深,但实际可能方向比较广,什么都懂一点,加上自己的业务理解抽象能力,在这样的环境下,我是不可能解决所有技术问题的,在团队中必须要互相配合才能整体前进,通过自己的知识和经验,做业务和技术的粘合剂,例如:
我虽然懂一点MVC,但涉及到JS东东,我就不懂了,前期我只要负责后台数据的统计,所以我们组找了一个前台开发高手,顺利解决碰到的一些MVC前端的效果功能模块问题;
我虽然懂一点SQL,写几个简单的select ,where 和join还行,但是复杂一点的,就搞不定了,所以我们组有一个SQL数据库开发高手,号称我们组SQL小王子;
很多地方需要用到接口,架构层面,技术细节层面都不是很懂,而我们一点准备都没有,自己是没时间学,要打通业务,要沟通需求,要把握产品方向,怎么办,所以我又通过朋友,找了一个接口开发高手,比我搞起来快多了;
业务太多,我没时间一一了解情况,不能熟悉每一个细节,所以我找了一个系统支持的朋友,给我解决问题,我们数据的价值不仅仅是解决自己的问题,还要解决别人的问题,这就是价值;
专业的人做专业的事情,就应该这样。通过开发任务的细分,让每个人做好自己的一部分,熟悉业务后,在不断往其他方面发展,今年,我也在要求团队成员进行项目和技术方向的交叉,互相***;
给别人机会就是自己的机会,也是团队成长的机会,既然自己不能做,就把机会留给别人,靠5个指头的单兵作战是很难打赢一个拳头的。当然团队的管理和成长也会碰到各种问题,一定要摸索和总结,不要怕犯错误,要用于承认和及时调整。
越是艰难处,越是修心时,所有的事情是有代价的,想提高自己和提升团队,就要付出代价。
4.4 种一颗树,10年后乘凉
种一棵树最好的时间是十年前,其次是现在。这是我在2016年喝的最有营养的一碗鸡汤。10年前我想不到现在的我,现在的我也不敢想象10年后的我。但是想在10年后在大树下乘凉,现在不种一棵树,去哪里乘凉?
所以把这句话总给大家共勉,勤勤恳恳,努力奋斗,到乘凉的时候你会感受到种树时的明智。
5.上图环节,卷起袖子加油干吧
每一天都是自己的,都是特殊的无可替代。同样我的2016年每一天都匆匆忙忙,所以转眼2017年了,不记得有多少次加班,不记得有多少次主动解决用户问题,不记得有多少次抗争。。。但都不重要,下面的这些时光记录了辉煌的2016,期待更好的2017!
1.2016年3月广州,微软最有价值专家大中华峰会。这些老兵都是我们学习的榜样!


2.2016年4月广东,我负责的系统第一次在全国最大的省份进行上线前的推广演示
内部系统就不做展示,这是今年最重要的一个项目,开发周期超过5个月,成功解决长期以来系统面临的技术难点和业务痛点,并稳定运行至今,经过双11双12,几倍压力高峰考验,不仅积累了大量的处理类似数据的经验,也对业务过程有了更深的理解,数据驱动业务,业务提出新的数据要求,未来,数据将更加重要,继续努力中。
3.2016年10月,收到微软官方邮件和大礼包,进入MVP2年级

4.2016年10月,杭州,和同事一起参加阿里云栖大会,阿里是个大公司,技术也很强,虽然吹牛的技术也不差,至少很多地方值得敬仰。

5.2016年10月,公司在纽交所上市,这是很多人的期待和未来奋斗的动力

6.2016年12月,北京,2016年微软技术大会,主要目的就是看Power BI

7.2016年12月,世界编程一小时活动,技术改变生活,小朋友的潜力很大,未来,IT前景将更加广阔

6.2017加油干吧
2017年已经来到,不仅是工作还是个人发展,都有了自己的目标。一方面管理好团队,做好自己的本质工作,让几个核心系统尽快上线,一方面学习更多数据统计分析方面的技术,更数据更加有价值。



最小的爬取样本
# -*- coding:utf-8 -*-
__author__ = 'ZHONGZHIKUN408'
import urllib
import urllib2
url = 'http://pws.paic.com.cn/m/'
req = urllib2.Request(url) #这里需要设置为security才是登录后的网页
print(req)
#<urllib2.Request instance at 0x000000000258EC88>
response = urllib2.urlopen(req)
print(response)
#<addinfourl at 43649160L whose fp = <socket._fileobject object at 0x00000000027EEB10>>
the_page = response.read()
print(the_page)
with open('test.txt','w') as f:
f.write(the_page)
#这个是正常爬取的内容,我的电脑在爬取外网的内容的时候是不可以的,可能是防火墙的限制
#http://stackoverflow.com/questions/5022945/urllib2-urlerror-urlopen-error-errno-11004-getaddrinfo-failed
#所以以后要练手,只能找平安的内部网
cookielib模块
cookielib模块一般与urllib2模块配合使用,主要用在urllib2.build_oper()函数中作为urllib2.HTTPCookieProcessor()的参数。
由此可以使用python模拟网站登录。
#!/usr/bin/env python
#-*-coding:utf-8-*-
import urllib
import urllib2
import cookielib
#获取Cookiejar对象(存在本机的cookie消息)
cj = cookielib.CookieJar()
#使用build_openper方法自定义opener,并将opener跟CookieJar对象绑定
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
#安装opener,此后调用urlopen()时都会使用安装过的opener对象
urllib2.install_opener(opener)
url = "http://www.baidu.com"
urllib2.urlopen(url)
参考
#http://www.cnblogs.com/sysu-blackbear/p/3629770.html
流程:先用cookielib获取cookie,再用获取到的cookie,进入需要登录的网站。
标准库(standard library)
“battery included”,Python 的一大好处在于它有一套很有用的标准库(standard library)。
标准库是随着 Python 一起安装在你的电脑中的,是 Python 的一部分
利用已有的类(class)和函数(function)进行开发,可以省去你从头写所有程序的苦恼。
这些标准库就是盖房子已经烧好的砖,要比你自己去烧砖来得便捷得多。
基本的urlopen()函数不支持验证、cookie或其他HTTP高级功能。
要支持这些功能,必须使用build_opener()函数来创建自己的自定义Opener对象。
学习网站
http://www.nowamagic.net/academy/detail/1302879
http://www.nowamagic.net/academy/category/13
零基础写python爬虫之爬虫编写全记录
http://blog.csdn.net/hmy1106/article/details/45113211
https://www.zhihu.com/question/21358581
对于主题爬虫,它的功能就是将与主题相关的网页下载到本地,将网页的相关信息存入数据库。
网页解析模块要实现两大功能:
1.从页面中提取出子链接,加入到爬取url队列中;
2.解析网页内容,与主题进行相关度计算。
由于网页内容解析需要频繁地访问网页文件,如果通过url访问网络获取文件的时间开销比较大
所以我们的做法是将爬取队列中的网页统统下载到本地,对本地的网页文件进行页面内容解析,最后删除不匹配的网页。
而子链接的提取比较简单,通过网络获取页面文件即可。
对于给定url通过网络访问网页,和给定文件路径访问本地网页文件,htmlparser都是支持的!
HTMLParser
from HTMLParser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print "a start tag:",tag,self.getpos()
parser=MyHTMLParser()
parser.feed('<div><p>"hello"</p></div>')
例子里HTMLParser是基类,重载了他的handle_starttag方法,输出了一些信息.
parser是MyHTMLParser的实例,调用feed方法开始解析函数.
值得注意的是,不需要显示调用handle_starttag方法就会执行.
HTMLParser含有的方法分为两类,一类是需要显式调用的,而另一类不需显示调用.
不需显式调用的方法
下面的这些函数在解析的过程中会触发,但是默认情况下不会产生任何副作用,因而我们要根据自己的需求重载.
1.HTMLParser.handle_starttag(tag,attrs):
解析时遇到开始标签调用,如<p class='para'>,参数tag是标签名,这里是'p',
attrs为标签所有属性(name,value)列表,这里是[('class','para')]
2.HTMLParser.handle_endtag(tag):
遇到结束标签时调用,tag是标签名
3.HTMLPars.handle_data(data):
遇到标签中间的内容时调用,如<style> p {color: blue; }</style>,参数data为开闭标签间的内容.
值得注意的是在形如<div><p>...</p></div>的位置,并不会在div处调用,而是只在p处调用
显式调用的方法
1.HTMLParser.feed(data): 参数为需要解析的html字符串,调用后字符串开始被解析
2.HTMLParser.getpos(): 返回当前的行号和偏移位置,如(23,5)
3.HTMLParser.get_starttag_text(): 返回当前位置最近的开始标签的内容
更详细的方法
http://blog.csdn.net/uestcyao/article/details/7876686
HTMLParser是Python用来解析html的模块。
它可以分析出html里面的标签、数据等等,是一种处理html的简便途径。
HTMLParser采用的是一种事件驱动的模式,当HTMLParser找到一个特定的标记时,它会去调用一个用户定义的函数,以此来通知程序处理。
它主要的用户回调函数的命名都是以handler_开头的,都是HTMLParser的成员函数。
当我们使用时,就从HTMLParser派生出新的类,然后重新定义这几个以handler_开头的函数即可。这几个函数包括:
handle_startendtag 处理开始标签和结束标签
handle_starttag 处理开始标签,比如<xx>
handle_endtag 处理结束标签,比如</xx>
handle_charref 处理特殊字符串,就是以&#开头的,一般是内码表示的字符
handle_entityref 处理一些特殊字符,以&开头的,比如
handle_data 处理数据,就是<xx>data</xx>中间的那些数据
handle_comment 处理注释
handle_decl 处理<!开头的,比如<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
handle_pi 处理形如<?instruction>的东西
以从网页中获取到url为例,介绍一下。要想获取到url,肯定是要分析<a>标签,然后取到它的href属性的值。
下面是代码:
#-*- encoding: gb2312 -*-
import HTMLParser
class MyParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
def handle_starttag(self, tag, attrs):
# 这里重新定义了处理开始标签的函数
if tag == 'a':
# 判断标签<a>的属性
for name,value in attrs:
if name == 'href':
print value
if __name__ == '__main__':
a = '<html><head><title>test</title><body><a href="http://www.163.com">链接到163</a></body></html>'
my = MyParser()
# 传入要分析的数据,是html的。
my.feed(a)
第二个示例程序:找图片链接
# -*- coding:utf-8 -*-
# file: GetImage.py
#
import Tkinter
import urllib
import HTMLParser
class MyHTMLParser(HTMLParser.HTMLParser): # 创建HTML解析类
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.gifs = [] # 创建列表,保存gif
self.jpgs = [] # 创建列表,保存jpg
def handle_starttag(self, tags, attrs): # 处理起始标记
if tags == 'img': # 处理图片
for attr in attrs:
for t in attr:
if 'gif' in t:
self.gifs.append(t) # 添加到gif列表
elif 'jpg' in t:
self.jpgs.append(t) # 添加到jpg列表
else:
pass
def get_gifs(self): # 返回gif列表
return self.gifs
def get_jpgs(self): # 返回jpg列表
return self.jpgs
class Window:
def __init__(self, root):
self.root = root # 创建组件
self.label = Tkinter.Label(root, text = '输入URL:')
self.label.place(x = 5, y = 15)
self.entryUrl = Tkinter.Entry(root,width = 30)
self.entryUrl.place(x = 65, y = 15)
self.get = Tkinter.Button(root,
text = '获取图片', command = self.Get)
self.get.place(x = 280, y = 15)
self.edit = Tkinter.Text(root,width = 470,height = 600)
self.edit.place(y = 50)
def Get(self):
url = self.entryUrl.get() # 获取URL
page = urllib.urlopen(url) # 打开URL
data = page.read() # 读取URL内容
parser = MyHTMLParser() # 生成实例对象
parser.feed(data) # 处理HTML数据
self.edit.insert(Tkinter.END, '====GIF====\n') # 输出数据
gifs = parser.get_gifs()
for gif in gifs:
self.edit.insert(Tkinter.END, gif + '\n')
self.edit.insert(Tkinter.END, '===========\n')
self.edit.insert(Tkinter.END, '====JPG====\n')
jpgs = parser.get_jpgs()
for jpg in jpgs:
self.edit.insert(Tkinter.END, jpg + '\n')
self.edit.insert(Tkinter.END, '===========\n')
page.close()
root = Tkinter.Tk()
window = Window(root)
root.minsize(600,480)
root.mainloop()
HTMLParser的源代码:
参考代码:
knows_eg
#coding:utf-8
import cookielib
import HTMLParser#用于 html 网页的解析,转换(Transformation) 以及网页内容的抽取 (Extraction)
import urllib
import urllib2
import sys
import os
import threading
import multiprocessing
#像线程一样管理进程,这个是mutilprocess的核心,他与threading很是相像,对多核CPU的利用率会比threading好的多。
from multiprocessing import Process,Queue,Pool
from Queue import Queue
#Queue是python标准库中的线程安全的队列(FIFO)实现,提供了一个适用于多线程编程的先进先出的数据结构,即队列
#用来在生产者和消费者线程之间的信息传递
from docx import Document #用来把爬下的内容存储到doc文件里
from docx.shared import Inches
import time
reload(sys)
sys.setdefaultencoding('gb18030')
#用来模拟网络登录的访问
def Cookie():
_cookie = cookielib.CookieJar()
#获取Cookiejar对象(存在本机的cookie消息)
_opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(_cookie))
#使用build_opener方法自定义opener,并将opener跟CookieJar对象绑定
_opener.addheaders = [
('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'),
('User-Agent', 'Mozilla/5.0,(Windows NT 6.1; WOW64; rv:42.0) Gecko/20100101 Firefox/42.0')
]
urllib2.install_opener(_opener)
def URL():#取得网页的内容
url1 = 'http://knows.paic.com.cn/knows/' #url1 需要登录的主页的网址
urllib2.Request(url1)
urllib2.urlopen(urllib2.Request(url1)).read()
#这个函数,写队列,主要就是不断的写入,要爬取的相应的页面
#如http://knows.paic.com.cn/knows/page/viewPage.shtml?pid=00005824
def writeQ(q):
#lock.acquire()
for i in range(1,10000):
q.put('http://knows.paic.com.cn/knows/page/viewPage.shtml?pid=%08d' %i)
#lock.release()
#用来解析网页
class MyHTMLParser(HTMLParser.HTMLParser):
index = False
Tail = False
word = False
href_value = ""
#a_info = []
Title = ""
VAlue = False
Content = []
Error = False
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.a_info = []
def handle_starttag(self,tag,attrs):
if tag == 'div':
# self.index = True
#print 'The start tag:',tag
for name,value in attrs:
# print 'Title:',name
# print 'Value:',value
if value == 'divContent':
self.index = True
#print value,tag
#self.index = True
elif tag == 'input':
for name,value in attrs:
if value == 'menuName':
self.VAlue = True
if self.VAlue and name == 'value':
self.Title = value
elif tag == 'a':
self.word = True
for name, value in attrs:
if name == 'href':
# print("href => [{href}]".format(href=value))
if value.startswith('/knows/'):
value = "http://knows.paic.com.cn{value}".format(value=value)
self.href_value = value
elif tag =='title':
Error = True
def handle_data(self,data):
if self.index and self.Tail :
if data.strip():
if u'标签' in data.strip().decode('gb18030') :
#if u'±ê' in data.strip().decode('gb18030') :
self.index = False
else:
self.Content.append(data.strip())
if self.word:
if '.' in data:
file_ext = data.split('.')[-1]
if file_ext in ['doc', 'docx', 'pdf', 'ppt', 'pptx','jpg']:
if self.href_value.startswith('/knows/'):
self.href_value = 'http://knows.paic.com.cn' + self.href_value
# save data to attribute with unicode
self.a_info.append([self.href_value.decode('gb18030'), data.decode('gb18030')])
def handle_endtag(self,tag):
if self.index and tag in ['p','a']:
self.Tail = True
def __del__(self):
del self.Content[:]
#del self.a_info[:]
#这个函数返回爬取回的网页回应,供 download_links 函数里面读取,网页为file_links
def _url_open(url, form=None, headers=None):
encoded_form = None
if form != None :
encoded_form = urllib.urlencode(form)
if headers == None: headers = {}
request = urllib2.Request(url, encoded_form, headers)#这里构造了request
response = urllib2.urlopen(request)#发送请求得到内容
return response
#获取文件的链接
def get_file_links(response):
parser = MyHTMLParser()
parser.feed( response.read() )
file_links = parser.a_info
return file_links
#这个函数在Th(q)里面执行了
def download_links(file_links, dir_name):
for (link, file_name) in file_links:
link = link.encode('gb18030')
file_name = file_name.encode('gb18030')
file_name = dir_name + '\\' + file_name
data = _url_open(link).read()
print("Save file {file_name}".format(file_name=file_name))
with open(file_name, 'wb') as fh:
fh.write(data)
#创建目录in Th(q)
def MKDIR(object):
try:
os.mkdir('D:\\Knows')
except:
pass
try:
os.mkdir('D:\\Knows\\%s' %object)
except:
pass
# os.chdir('D:\\Knows\\%s' %object.strip())
#
def Th(q):
while True:
if not q.empty():
url3 = q.get(False)
req1 = urllib2.urlopen(url3)
print url3
My = MyHTMLParser()
My.feed(req1.read())
Title = My.Title
Content = My.Content
My.close()
try:
MKDIR(Title.strip())
except IndexError:
sys.exit()
#os.chdir('D:\\Knows\\%s' %Title.strip())
dir_name = 'D:\\Knows\\%s' %Title.strip()
document = Document()
#document.add_heading('HTML:http://profile.paic.com.cn/profile/log/viewlog.shtml?id=%d\n' %i,0)
for i in Content:
if u'标签' in i.decode('gb18030'):
break
else:
document.add_paragraph('%s' %i.decode('gb18030'))
# document.save('%s.doc' %Title.strip())
try:
document.save("{dir_name}\\{title}.doc".format(dir_name=dir_name, title=Title.strip()))
except:
pass
# fetch doc information
doc_url = (url3)
doc_response = _url_open(doc_url)
# get file download links
file_links = get_file_links(doc_response)
# download link
try:
download_links(file_links, dir_name)
except Exception:
pass
print '*' * 30
print Title.strip()
#print url3
else:
break
def main():
manager = multiprocessing.Manager() #多进程模块
q = manager.Queue()
writeQ(q)
threads = []
#定义用户名和密码
Username = 'rongweiwei799'
Password = 'XXX'
#要提交的用户名密码
postdate = {'j_username':Username,'j_password':Password}
url2 = 'http://knows.paic.com.cn/knows/j_security_check'#url2为 j_security_check
Cookie()#设置对应的cookie
URL()#取得网页的内容
req = urllib2.Request(url2,urllib.urlencode(postdate))#注意这里为 url2,为登录需要验证密码的页面
urllib2.urlopen(req)
Lock = threading.Lock()
#num_of_threads = 5 这里是进行多线程爬取
for i in range(10):
t = threading.Thread(target=Th, args=(q,))#在这里的参数使用了Th
#t.setDaemon(True)
if Lock.acquire(2):
t.start()
#time.sleep(1)
Lock.release()
if __name__ == '__main__':
main()
#这次完全换了一种方式来写,并加入了多线程使爬取速度更快
#所有的Knows文章已经放到共享文件夹,如果文档中有附件会将附件和文章放在同一文件夹下
学习学习方法的网站
http://www.nowamagic.net/academy/category/68/
今天的总结:
大家都很努力,毕竟公司不是白养你,是给钱给你做事的。
我必须要做出一些成绩来
要超出大家的期望
我要加班加点完成,同时增长自己的技能
我的编程能力还真的很弱,连野路子的人都还比不上
摘录
你的第一桶金是如何赚到的?

面向工资编程
想来到现在走出校园已经5年了。
当时卡上躺着100w现金,还是蛮激动的。
大三的时候“混进”一家叫豆瓣的小公司实习,中午和几个小伙伴吃饭,那时候就在想,他们好厉害。一个月7~8千,但怎么好像跟我差不多……
当时挺苦的,合租在一间特别小的房子里,夏天,屋子里没有风扇,只好找一条毛巾弄湿了,披在身上,还是挺凉快的。
当时我就在想:虽然现在过得好“艰苦”,但许多年后我一定会怀念这段时光的!
这样又阿Q般充满了干劲。
大学毕业进入了初中就一直神往的公司:Baidu。
本科毕业当时一个月9000块,周围的小伙伴都震惊了,当时心里还是高兴了好几个月。
当时女朋友是异地,我北漂北京上班,虽然平时基本没什么花销,但有钱就买机票,所以两年下来也没攒到什么钱,的确是学到了很多东西。
当时工作努力到:每周工作7x12小时,为了不给周围的同事压力,大家下班我就带电脑回去继续,周末也不怎么出去,在家继续写代码。
后来我的领导跳槽走了,天天请我吃饭,吃了好几次,领导跟我说:“我这边不错,过来吧。”
当时觉得他人挺好就答应他了……
清楚的记得,当时卡上也就20000块钱。
于是跳槽到了另外一家也还是很有影响力的公司,当时谈薪资的时候HR给我两种选择:
1. 多给薪水。
2. 给公司的期权。
当时想的是就算多几千块钱,还是依旧什么都买不起,干脆就要期权,就当×××了
于是又是埋头苦干,别人一个月才能搞定的,我加班加点一周搞定……
期间公司发生了好多事情,股价一路上涨(后来才知道的,平时也不关心),我也被大领导委任了更重要的事情……
有一天,查了查自己的期权账户,:-O……好像有100万了……兴奋了好几周……
后来卖期权、股票,卖过的同学都知道,缴税,那叫一个肉疼!
结束了?不,故事才刚刚开始:
由于项目需求,大概是三年前的一个周末,研究加密算法、Grid Computing,接触到了“比特币”,碰巧之前翻过一本书货币的非国家化 (豆瓣) (后来跟比特币圈子里几个资深的人交流,惊奇的发现,我们好多人都是受这本书的影响),当时就觉得这个点子真是太妙了,当时就买了一些,大概是一个比特币8块钱的样子。
搞自动化交易(此处有故事)
组装比特币矿机(至今家里还有价值好几万的显卡)
和教主一起做比特币交易市场(http://42btc.com)
基本把比特币的整个产业链折腾了一圈……当时也没认真算过自己手里有多少钱,几百万账面应该是有的,当时喝了马化腾没有买房所以有了腾讯的鸡汤,也没卖。
结束了?不,故事才刚刚开始:
后来经历了比特币的各种崩盘,心也累了,就丢在Mtgox不管了。
有一天中午吃饭,我的自动化交易程序(没有利用任何漏洞,纯属模拟人去发交易请求)报告:以10块钱一个的价钱买入了260个比特币(当时市价440左右吧),后来就引发了这件事,一下子跟http://btcchina.com的老板死逼了几天,后来禁不住他们的各种威胁,“和解”了:
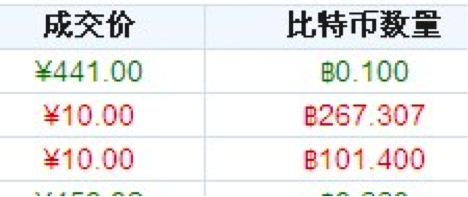
今天不断刷新网页的时候发现有人挂单卖比特币,要价10¥,数量是368.707BTC。
没多想迅速的下单全部买下,最终成交了267.307BTC左右
另外101.4BTC被另外一个买家买下
由于之前btcchina用户名密码泄漏的原因,我有习惯把大量BTC转移出btcchina的习惯。
所以我跟客服申请将我原来的150BTC的限额提升到300BTC,连同我之前的20个BTC转到了 http://blockchain.com 上。
好像是去年还是前年,比特币突然火遍中国大江南北,颇像当年荷兰的郁金香事件,当时一度被爆炒到8000多一个币,然后我就全抛了……
再后来,央行出了各种红头文件,我就不干了。也没怎么跟家里打招呼,在北京买了个房。
其实最后由于Mtgox倒闭,赔了不少。要说收获就是,现在对于钱心态特别淡定了。
好多朋友觉得我是瞎编的,大家可以check我常用的两个钱包的历史盈余:
http://blockchain.info/address/1MC9PnJAu2RceJMz8ERDqc8o1UuyJg89Tw
http://blockchain.info/address/1Auxten9cxKKjbuNhUea3RZQ2XgzrGPDzQ
结束了?不,故事才刚刚开始。
========2015-10-10更新========
经历了种种投机,我静下来思考了很长时间,总结了几条经验吧:
之前在比特币上赚的钱全是利用的消息的不对等,作为一个对金融感兴趣的程序员,能比其他人更早的了解比特币的本质,能在市场还不完善的时候用自己的专业知识做自动化交易,从中牟利。
纯的投机、拼“头脑”几乎是赚不到钱的,因为这件事没有任何门槛。所以,当大众都来炒比特币,这件事在短期就是零和博弈,没有特殊技能的你不要指望你能比别人更聪明。
后来我和我的朋友发现了另外一个稳赚的点:“套利”。
其实就是在各个市场创建资金池,通过市场之间波动和价差赚取差价。
当然 这一切都是,通过程序自动化交易的。很快,应该也有别的玩家也在进行类似的事情,差价变得很小,只能通过比拼程序的速度才能赚取少量的利润。
我们就把目光转向了国际市场间的差价,这个领域利润较为丰厚,但由于我国的×××限制(每人每年5w刀的限制),还算是一片蓝海。
由于资金流转的很快,我和几个伙伴的×××额度没几天就用光了。
当时也想了很多别的办法。但是在研究了×××管理局的几个红头文件后,发现里面还是有很大的政策风险,所以,很快也就作罢了。细节我这里就不展开说了。
关于比特币的故事基本就到这里了,但我的故事才刚刚开始。
转载于:https://blog.51cto.com/nowforme/1900779















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









