







李竹君 2011211964 0401115班
1.使用C语言。
2.整体思路:首先将一篇文章分词,分词的方法是将逐字符的判断一篇文章,如果该字符的ASCII码在“A~Z”或“a~z”之间(区分大小写),则该字符属于一个单词的一部分,如果该字符不在“A~Z”或者“a~z”,则该字符为两个单词之间的分隔符(多个标点或者空格相连的情况下在3.讲)。将分隔下来的单词和该单词的长度存入结构体,将所有结构体构成链表,将表头的单词与除表头外的所有单词进行比较,如果出现一个单词和原节点单词相等,则将该节点删掉,以此类推,直到最后一个节点,记录相等节点数目,并存入该节点结构体,然后再将表头的下一个节点单词与该节点的后续节点比较,以此类推,直到所有节点都比较完毕。再对所有链表节点内的相等节点数目进行升序排序,取前十位,则得到结果。
3.具体实现细节:1)多个标点或空格:在形成链表的过程中,若出现多个标点或空格,则判断该节点内的单词是否为'\0',若为'\0',则原文中此处出现多个标点或空格相连。将该节点删去即可。2) 将节点的单词长度记录下来是为了在比较过程中提高效率,即单词长度不等则单词肯定不等。
4.采用“选择排序”。
5.原文档303kb.
6.运行结果:
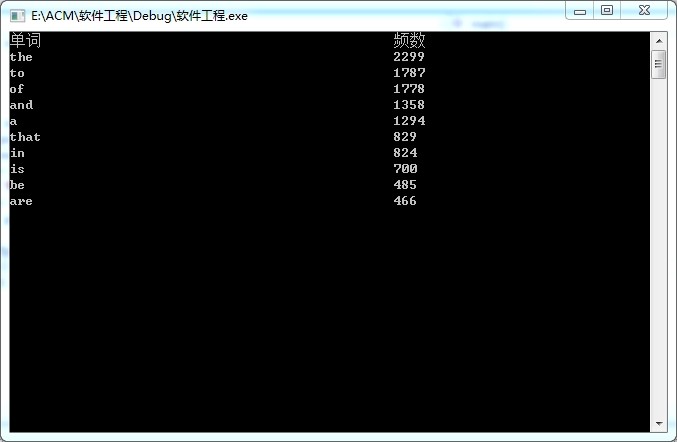
7.性能分析:


可以看到,总共程序运行1.6s,在单独工作的函数中,除主函数外,pre_sort()是占用时间百分比最多的,在pre_sort中,主要实现的是对于单词链表的处理,即使链表节点的单词不重复,并记录该单词出现的次数,其次是sort(),该函数主要是节点频数进行排序,如果要优化过程的话,可以从对排序进行优化,当单词数目较多时,改用快速排序,可以降低运行时间,优化代码。
8.心得:写完程序之后,我感觉技术性的工作就好比变魔术,其实原理是非常简单的,甚至可以说简单的可笑,但是当你就是做出这么一个简单的东西出来之后,一些外行们有时候会用崇拜的眼光看着你,觉得你很厉害,很高深莫测。但是制作的过程他们却不知道,也许知道之后他们只是会哑然失笑,原来这个东西的制作过程是如此的简单。这个可以说就是技术的魅力了。















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









