







本文为 AI 研习社编译的技术博客,原标题 :
Diving deeper into Reinforcement Learning with Q-Learning
作者 | Thomas Simonini
翻译 | 斯蒂芬•二狗子
校对 | 斯蒂芬•二狗子 审核 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.freecodecamp.org/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe
深度强化学习从入门到大师:通过Q学习进行强化学习(第二部分)

本文是 Tensorflow 深度强化学习课程的一部分。 ️点击这里查看教学大纲。
今天我们将学习 Q-Learning。 Q-Learning 是一种基于数值的强化学习算法。
本文是关于深度强化学习的免费系列博客文章的第二部分。有关更多信息和更多资源,请查看 课程的教学大纲。 请参阅 此处的第一篇文章。
在本文中,您将学习:
什么是 Q-Learning
如何用Numpy实现它
大图:骑士和公主
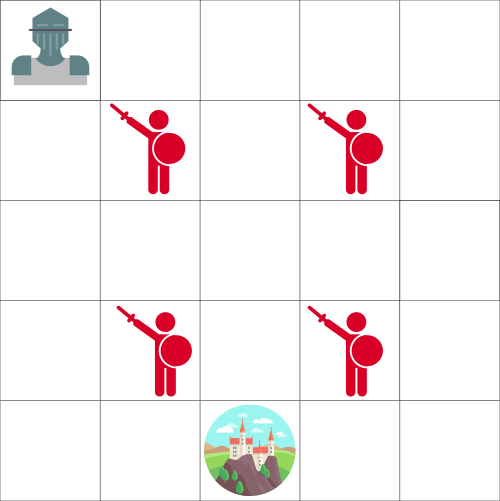
假设你是一名骑士,你需要拯救被困在上面地图上所示城堡中的公主。
您可以一次移动一个图块。敌人不能移动,但是骑士和敌人落在同一块地砖上就会死。目标是使骑士尽可能以最快的路线前往城堡。这可以使用“积分”系统来评估。
骑士每走一步都减去1分 (使用每一步-1策略有助于我们的Agent快速到达终点)。
如果 骑士 触碰一个敌人,将失去100分,然后这一集结束。
如果 骑士 在到达城堡并获胜,将得到100分。
问题是:如何做才能创建一个的 Agent 完成这个任务?
这里的第一个策略:让 Agent 不断尝试移动到每个瓷砖上,然后为每个瓷砖着色。绿色表示“安全”,红色表示“不安全”。

相同的地图,但着色显示哪些瓷砖可以安全访问
然后,我们可以告诉 Agent 只在绿色瓷砖上移动。
但问题是这样做并没有对问题有帮助。当绿色瓷砖彼此相邻时,我们无法分辨哪个瓷砖更好。所以 Agent 在试图找到城堡过程会因此陷入死循环!
介绍Q表
这是第二个策略:创建一个表格,我们将计算每种状态 state 下采取的每种行动 action的最大的未来预期奖励。
多亏了这个策略,我们将知道对每种状态采取的最佳行动是什么。
每个 state(瓷砖片)允许四种可能的动作。它们分别是向左,向右,向上或向下移动。
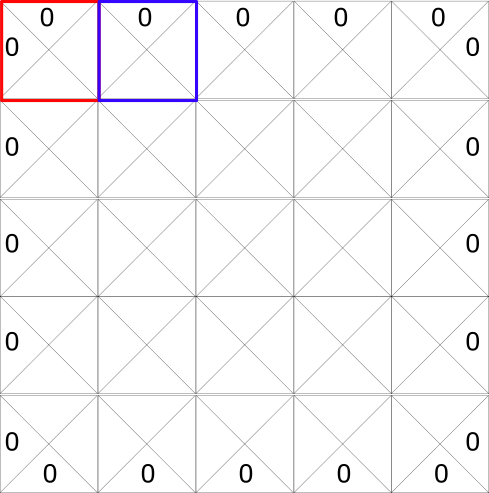
0表示不可以执行的动作(如果你在左上角你不能向左或向上!)
在计算方面,我们可以将此网格转换为表格。
这个表格被称为 Q 表(“Q”表示动作的“质量”)。列表示是四个动作(左,右,上,下)。行表示的是状态。每个单元格的值将是该给定状态和行动的最大未来预期奖励。
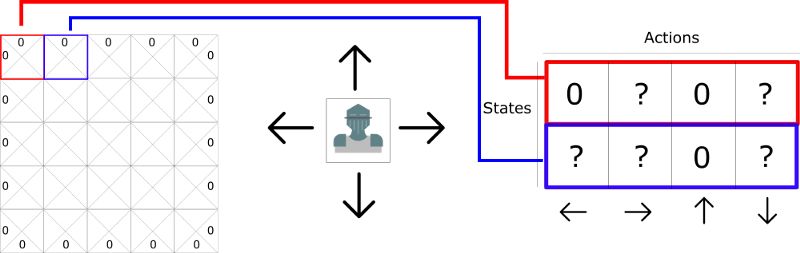
如果在 state 状态下给定的行动 action 是最佳策略,那么每个 Q 表评分为未来奖励的最大期望。
为什么我们说“根据策略给出?”这是因为我们不能直接给出这种策略。而是通过改进我们的 Q 表以始终选择最佳行动 action。
可以把这个 Q-table 认为是一个游戏的“备忘单”。通过找到“备忘单”行中的最高分,我们知道每个状态(Q 表中的每一行)最好的行动是什么。
Yeah!我们解决了城堡问题!但是等等......我们如何计算 Q 表中每个元素的值?
要给出此 Q 表的每个值,可以使用 Q-learning 算法。
Q学习算法:学习动作值函数
动作值函数(或“ Q 函数”)有两个输入:“状态”和“动作”。它返回该动作在该状态下的预期未来奖励。
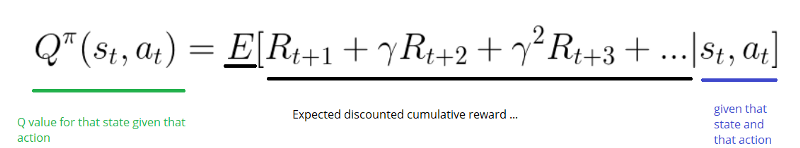
我们可以把这个 Q 函数作为一个阅读指南,通过滚动 Q 表找到与我们的状态相关的行,以及与我们的动作相关联的列。它返回匹配的 Q 值。这个值就是“预期的未来奖励”。

在我们探索环境之前,Q 表中的值是固定的初始值(一般为0)。在我们探索环境时,通过使用Bellman方程迭代更新Q(s,a),Q 表中的值将趋近于更好(见下文!)。
Q学习算法过程
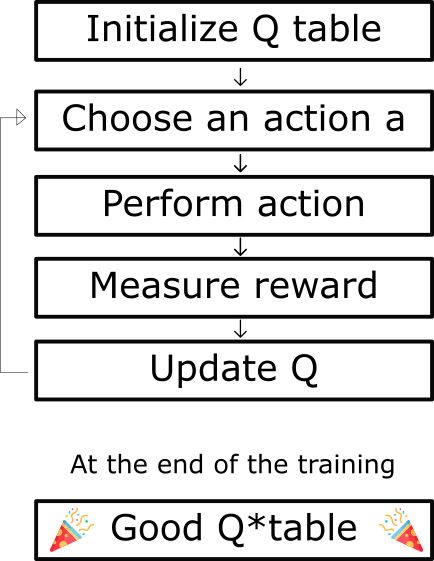

Q-Learning算法的伪代码
步骤1:初始化Q值
我们构建一个Q表,有 m 列 (m = 行动数)和 n 行(n =状态数)。我们将值初始化为0。

第2步:终身学习(或直到学习停止)
该过程将重复步骤3到5,直到算法运行次数为的 episode 的最大值(由用户指定)或直到我们手动停止训练。
步骤3:选择操作
根据当前的Q值 选择 当前状态下行动 Action a。
但是......如果每个Q值都是零,那么在该采取什么行动?
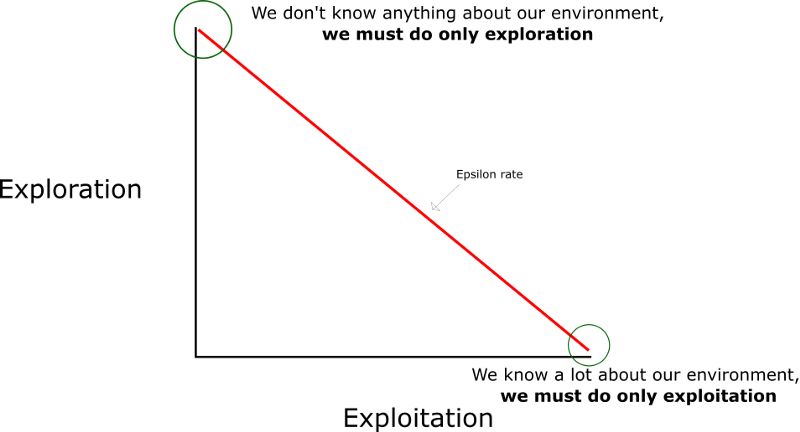
这就是我们在上一篇文章中谈到的探索/使用权衡的重要性。
我们的想法是,在开始时,我们将使用epsilon贪心策略:
我们指定一个探索率“epsilon”,我们在开始时设置为1,即随机执行的step的速度。刚开始学习时,这个速率必须是最高值,因为我们对Q表的取值一无所知。这意味着我们需要通过随机选择我们的行动进行大量探索。
生成一个随机数。如果这个数字> epsilon,那么我们将进行“ 使用”(这意味着我们使用已知的方法来选择每一步的最佳动作)。否则,我们会进行探索。
我们的想法是,在Q函数训练开始时我们必须有一个较大的epsilon。然后,随着Agent变得做得越来越好,逐渐减少它。
步骤4-5:评估!
采取行动action a 并观察结果状态 s' 和奖励 r。 并更新函数Q(s,a)。
我们采取我们在步骤3中选择的操作,然后执行此操作将返回一个新的状态s'和奖励r(正如我们在第一篇文章中的看到的强化学习过程那样)。
然后,使用Bellman方程更新Q(s,a):
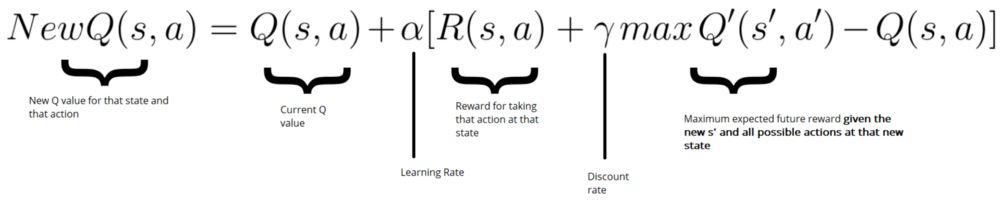
更新Q(state,action)代码可以写成如下所示:
New Q value =
Current Q value +
lr * [Reward + discount_rate * (highest Q value between possible actions from the new state s’ ) — Current Q value ]
我们来举个例子:

一个奶酪= +1
两个奶酪= +2
大堆奶酪= +10(剧集结束)
如果吃到鼠毒= -10(剧集结束)
第1步:初始化Q表
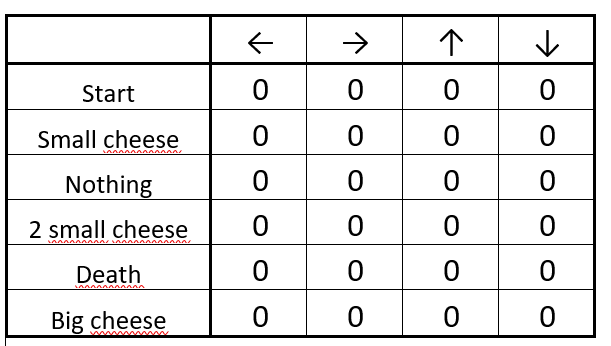
初始化的Q表
步骤2:选择操作
从起始位置,您可以选择向右还是向下。我们有一个大的epsilon率(因为我们对环境一无所知),采用随机选择的方式。例如......向右移动。


我们采用随机移动(例如,右)
发现了一块奶酪(+1),则更新的Q值并记录向右的行动。通过Bellman方程来进行计算。
步骤4-5:更新Q函数

首先,计算Q值的变化ΔQ(start, right)
然后将Q值与ΔQ(start, right)的和乘以学习率。
学习率可以看视为该学习网络更新Q值的速度。如果学习率为1,则新估计值将是新的Q值。

更新后的Q表
好!我们刚刚更新了我们的第一个Q值。现在我们需要一次又一次地这样做,直到学习停止。
实现Q学习算法
我们制作了一个视频,我们实现了一个学习与Numpy一起玩Taxi-v2的Q学习代理。
使用numpy和OpenAI Taxi-v2 进行Q学习(教程)
现在我们知道Q-Learning是如何工作的,我们将逐步实现Q学习算法。代码的每个部分在下面的Jupyter笔记本中都能找到。
您可以在Deep Reinforcement Learning Course repo中访问它 。
或者您可以直接在Google Colaboratory上访问它:
Q-learning实现Frozen Lake
colab.research.google.com
回顾......
Q-learning是一种基于数值的强化学习算法,用于使用q函数找到最优的动作选择策略。
它根据动作值函数评估要采取的动作,该动作值函数确定处于某种状态的值并在该状态下采取某种动作。
目标:最大化Q函数(给定状态和行动的预期未来奖励)。
Q表帮助我们找到每个状态的最佳行动。
通过选择所有可能的最佳行动来最大化预期奖励。
Q表示来自特定状态下某个动作的质量。
函数Q(state, action) → return该状态下该动作的预期未来奖励。
可以使用Q学习来估计该函数,Q学习使用Bellman方程迭代地更新Q(s,a)
在我们探索环境之前:Q表给出了相同的任意值进行初始化→但是当我们探索环境时→Q给了我们更好的近似值。
就这样!不要忘记自己实现代码的每个部分 - 尝试修改我给你的代码非常重要。
尝试添加epoch,改变学习速度,并使用更复杂的环境(例如使用8x8瓷砖的Frozen-lake)。玩得开心!
下次我们将开展深度Q学习,这是2015年深度强化学习的最大突破之一。我们将训练一个智能体玩Doom,并杀掉敌人!
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【深度强化学习从入门到大师:通过Q学习进行强化学习(第二部分)】:
https://ai.yanxishe.com/page/TextTranslation/1394
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网雷锋网(公众号:雷锋网)雷锋网
【点击跳转】深度强化学习从入门到大师:简介篇(第一部分)
用PyTorch来做物体检测和追踪
用 Python 做机器学习不得不收藏的重要库
初学者怎样使用Keras进行迁移学习
一文带你读懂 WaveNet:谷歌助手的声音合成器
等你来译:
强化学习:通往基于情感的行为系统
如何用Keras来构建LSTM模型,并且调参
高级DQNs:利用深度强化学习玩吃豆人游戏
用于深度强化学习的结构化控制网络 (ICML 论文讲解)














 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









