






https://www.freecodecamp.org/news/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe/
本章我们来学习Q-Learning。Q-Learning是一种value-based的强化学习方法。
The big picture: the Knight and the Princess
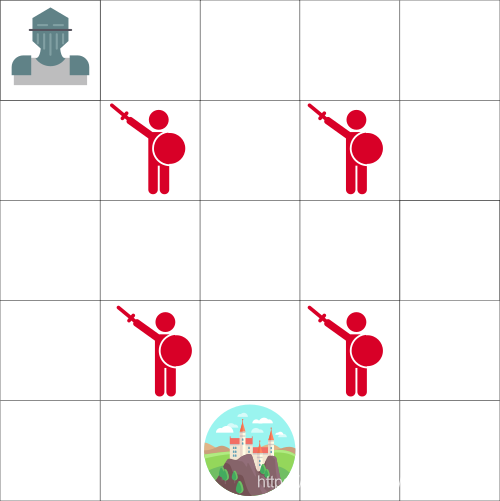
现在你是一个骑士,然后你需要救出城堡里的公主,如上图。
你每次可以移动一格。敌人不会动,但是如果你移动到了敌人的格子上,你就会死。你的目标是尽可能快的移动到城堡。这个可以用一个“计分”系统来评估。
- 每移动一步你会-1分(每一步失分会帮助我们的agent快速移动)。
- 如果你碰到了敌人,你会-100分,这次游戏就结束。
- 如果你成功到达城堡,你会+100分。
问题是:我们要怎样去创造一个可以做到上述操作的agent?
这里有第一个策略。现在我们将所有的格子都上色。绿色代表“安全”,红色代表“危险”。

然后,我们可以告诉我们的agent只能走绿色格子。
但是问题是这也没什么用。我们并不知道哪个格子是最优的,因为绿格子是相邻的,这就导致agent可能会落入一个死循环。
Introducing the Q-table
这里有第二个策略:创建一个表格,对于每个state的每个action都计算一个最大期望未来回报。
有了这个我们就知道在每个state我们应该采取哪个动作了。
每个state有4个可能的动作,也就是上下左右。

0代表不可能的移动(因为你不能移动出去)
方便计算,我们可以将网格转换成表格。
这就叫做Q-table(“Q”代表动作的"quality")。每一行代表states。每个单元格代表给定的state和action后,所得到的最大期望未来reward。
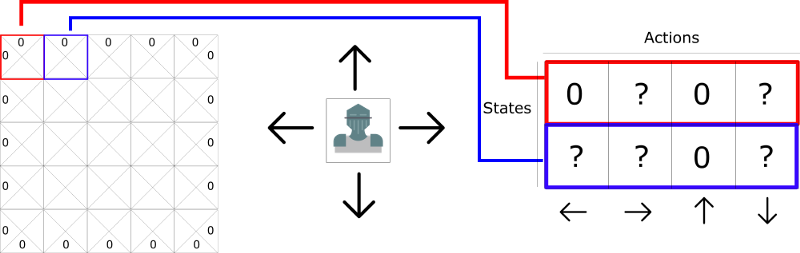
每个Q-table的分数都代表了最大期望未来reward,如果我能在该state采取使用最优的给定policy下的动作。
为什么我要强调“给定policy”?这是因为我们没有policy。而我们是通过改进我们的Q-table来总是选择最优action。
我们可以将Q-table看做是一个"cheat sheet"。因为有了它,我们可以简单选择每个state下面最高分数的action。
哇哦!这样我们就解决了营救问题!但是等等,最重要的一点是我们如何计算Q-table的每个元素的值呢?
为了计算Q-table的每个值,我们就要用到Q-Learning 算法。
Q-learning algorithm: learning the Action Value Function
动作价值函数(或者“Q-function”)有两个输入:“state”和“action”,返回的是该state下该action的期望未来报酬。
Q
π
(
s
t
,
a
t
)
=
E
[
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
.
.
.
∣
s
t
,
a
t
]
Q^{\pi}(s_t,a_t)=E[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+...|s_t,a_t]
Qπ(st,at)=E[Rt+1+γRt+2+γ2Rt+3+...∣st,at]
我们可以将Q函数看做是一个阅读器,它在Q-table里面搜索找到对应的行和列,然后返回匹配的单元格的Q值。这就是“期望未来报酬”。

但是在我们探索环境之前,Q-table被赋予同样的随机值。当我们不断的对环境进行探索,通过使用bellman公式迭代更新Q(s,a),Q-table会逐渐逼近最优解。
The Q-learning algorithm Process


上面是Q-learning算法的伪代码
Step 1: Initialize Q-values
建立Q-table,m列(动作个数)和n行(state个数),进行0初始化。

Step 2: For life (or until learning is stopped)
我们会依次循环步骤3-5直到达到最大episodes数或者我们手动停止训练。
Step 3: Choose an action
根据当前state的Q-value估计来选择action。
但是最初的动作,如何选择呢,因为每个Q-value都是0?
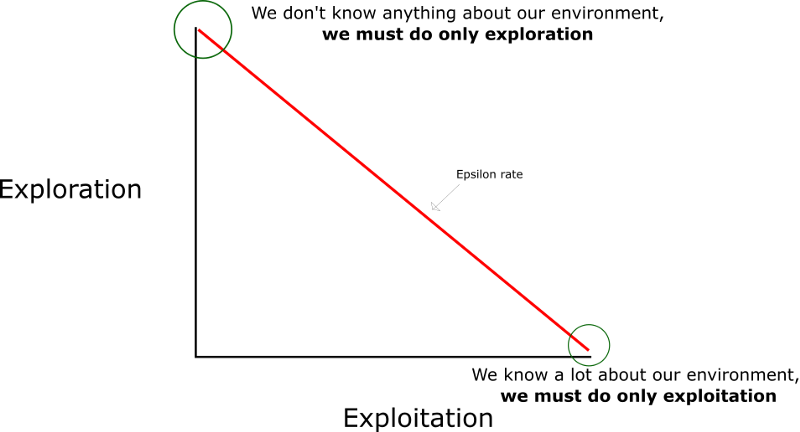
这里就需要用到我们上一章提到的探索/利用权衡了。
这个思想是在训练的一开始,我们使用epsilon greedy strategy:
- 我们定义一个探索率 ϵ \epsilon ϵ,在最开始我们设置其为1。也就是我们随机选择动作。在最开始,这个几率一定是处于最大值,因为这个时候我们对Q-table的值一无所知。这就意味着我们需要做很多的探索,通过随机选择我们的动作。
- 我们随机生成一个数。如果这个数大于 ϵ \epsilon ϵ,那么我们就做"exploitation"(这就意味着我们已知每一步的最优动作),反之,我们做"exploration"。
- 整个思想就是,在Q-function的训练的最开始,我们必须使用一个大的
ϵ
\epsilon
ϵ,然后当agent对Q-values的预测置信度越来越高的时候,我们逐渐地减小
ϵ
\epsilon
ϵ。
Step 4-5: Evaluate!
采取action a,然后观察输出state s和reward r。现在更新函数Q(s,a),使用bellman公式
New
Q
(
s
,
a
)
=
Q
(
s
,
a
)
+
α
[
R
(
s
,
a
)
+
γ
max
Q
′
(
s
′
,
a
′
)
−
Q
(
s
,
a
)
]
\text{New }Q(s,a)=Q(s,a)+\alpha[R(s,a)+\gamma \max Q'(s',a')-Q(s,a)]
New Q(s,a)=Q(s,a)+α[R(s,a)+γmaxQ′(s′,a′)−Q(s,a)]
New Q value = Current Q value + lr * [Reward + discount_rate * (highest Q value between possible actions from the new state s’ ) — Current Q value ]
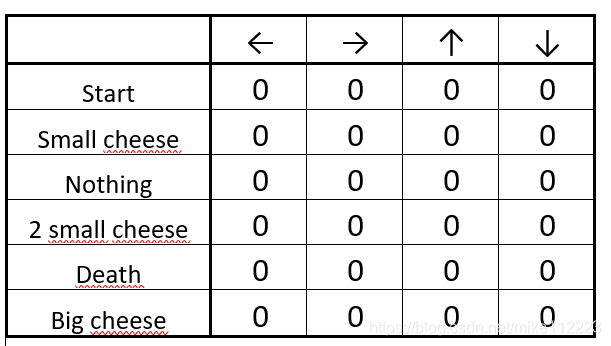
举个例子:

- 一个起司 +1
- 两个起司 +2
- 大块起司 +10(episode结束)
- 毒药 -10(episode结束)
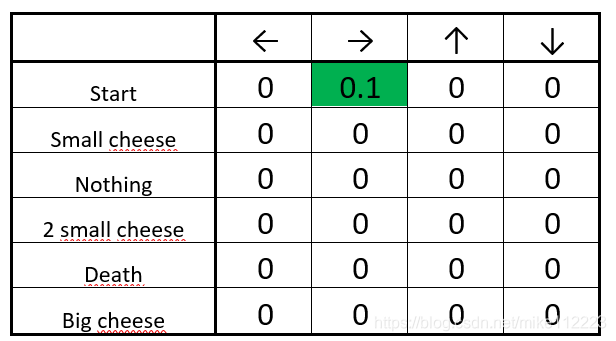
Step 1: We init our Q-table
Step3: Choose an action
从起始位置开始,你可以选择下或者右。因为我们有一个大的
ϵ
\epsilon
ϵ,所以我们随机选择。例如,向右。


我们找到了一块起司(+1),现在我们可以使用bellman公式更新Q-value了。
Steps 4–5: Update the Q-function
New
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
=
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
+
α
[
Δ
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
]
Δ
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
=
R
(
s
t
a
r
t
,
r
i
g
h
t
)
+
γ
m
a
x
Q
′
(
1
c
h
e
e
s
e
,
a
′
)
−
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
Δ
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
=
1
+
0.9
m
a
x
(
Q
′
(
1
c
h
e
e
s
e
,
l
e
f
t
)
,
Q
′
(
1
c
h
e
e
s
e
,
r
i
g
h
t
)
,
Q
′
(
1
c
h
e
e
s
e
,
d
o
w
n
)
)
−
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
Δ
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
=
1
+
0.9
∗
0
−
0
=
1
New
Q
(
s
t
a
r
t
,
r
i
g
h
t
)
=
0
+
0.1
∗
1
=
0.1
\begin{aligned} & \text{New }Q(start,right)=Q(start,right)+\alpha[\Delta Q(start,right)] \\ & \Delta Q(start,right)=R(start,right)+\gamma maxQ'(1cheese,a')-Q(start,right) \\ & \Delta Q(start,right)=1+0.9max(Q'(1cheese,left),Q'(1cheese,right),Q'(1cheese,down))-Q(start,right) \\ & \Delta Q(start,right)=1+0.9*0-0=1 \\ & \text{New }Q(start,right)=0+0.1*1 = 0.1 \end{aligned}
New Q(start,right)=Q(start,right)+α[ΔQ(start,right)]ΔQ(start,right)=R(start,right)+γmaxQ′(1cheese,a′)−Q(start,right)ΔQ(start,right)=1+0.9max(Q′(1cheese,left),Q′(1cheese,right),Q′(1cheese,down))−Q(start,right)ΔQ(start,right)=1+0.9∗0−0=1New Q(start,right)=0+0.1∗1=0.1














 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









