







学习java.nio软件包,我们先从Buffer类开始,学会它的用法。
Buffer对象可以看作是存储数据的容器,对于每个非布尔数据类型都有一个对应的子类,例如IntBuffer。
下面看一个简单的使用IntBuffer的例子。
package com.henrysun.javaSE.niostudy;
import java.nio.IntBuffer;
public class IntBufferTest {
/**
* @param args
*/
public static void main(String[] args) {
// 分配新的int缓冲区,参数为缓冲区容量
// 新缓冲区的当前位置将为零,其界限(限制位置)将为其容量。它将具有一个底层实现数组,其数组偏移量将为零。
IntBuffer ib=IntBuffer.allocate(8);
for(int i=0;i<ib.capacity();++i)
{
int j=2*(i+1);
// 将给定整数写入此缓冲区的当前位置,当前位置递增
ib.put(j);
}
// 重设此缓冲区,将限制设置为当前位置,然后将当前位置设置为0
ib.flip();
// 查看在当前位置和限制位置之间是否有元素
while (ib.hasRemaining()) {
// 读取此缓冲区当前位置的整数,然后当前位置递增
int j = ib.get();
System.out.print(j + " ");
}
}
}


如果是对于文件读写,上面几种Buffer都可能会用到。但是对于网络读写来说,用的最多的是ByteBuffer。
缓冲区基础
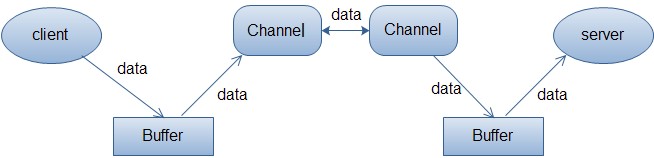
缓冲区是包在一个对象内的基本数据元素数组。Buffer 类相比一个简单数组的优点是它将关于数据的数据内容和信息包含在一个单一的对象中。Channel提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由Buffer。具体看下面这张图就理解了:
属性
容量(capacity):能够容纳数据元素的最大数量,在缓冲区创建时指定,且无法改变。
上界( Limit):指定还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入 数据(在从通道读入缓冲区时)。
位置( Position):下一个要被读或写的元素索引。位置会自动由相应的 get( )和 put( )函数更新。
标记( Mark):一个备忘位置。调用 mark( )来设定 mark = postion。调用 reset( )设定 position =mark。 标记在设定前是未定义的(undefined)。
这四个属性之间总是遵循以下关系:
0 <= mark <= position <= limit <= capacity
下图展示了一个新创建的容量为 10的 ByteBuffer 逻辑视图

位置被设为 0,而且容量和上界被设为 10,刚好经过缓冲区能够容纳的最后一个字节。标记最初未定义。容量是固定的,但另外的三个属性可以在使用缓冲区时改变。
现在我们可以从通道中读取一些数据到缓冲区中,注意从通道读取数据,相当于往缓冲区中写入数据。如果读取4个自己的数据,则此时position的值为4,即下一个将要被写入的字节索引为4,而limit仍然是10,如下图所示:

下一步把读取的数据写入到输出通道中,相当于从缓冲区中读取数据,在此之前,必须调用flip()方法,该方法将会完成两件事情:
1. 把limit设置为当前的position值
2. 把position设置为0
由于position被设置为0,所以可以保证在下一步输出时读取到的是缓冲区中的第一个字节,而limit被设置为当前的position,可以保证读取的数据正好是之前写入到缓冲区中的数据,如下图所示:

现在调用get()方法从缓冲区中读取数据写入到输出通道,这会导致position的增加而limit保持不变,但position不会超过limit的值,所以在读取我们之前写入到缓冲区中的4个自己之后,position和limit的值都为4,如下图所示:

在从缓冲区中读取数据完毕后,limit的值仍然保持在我们调用flip()方法时的值,调用clear()方法能够把所有的状态变化设置为初始化时的值,如下图所示:

用代码来验证这个过程:
package com.henrysun.javaSE.niostudy;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* Buffer的重要属性学习
* @author henrysun
*
*/
public class BufferShuXing {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
FileInputStream fin=new FileInputStream("C:\\Users\\henrysun\\Desktop\\test.txt");
FileChannel fc=fin.getChannel();
ByteBuffer buffer=ByteBuffer.allocate(10);
output("初始化", buffer);
fc.read(buffer);
output("调用read", buffer);
buffer.flip();
output("调用flip()", buffer);
while (buffer.remaining() > 0) {
byte b = buffer.get();
// System.out.print(((char)b));
}
output("调用get()", buffer);
buffer.clear();
output("调用clear()", buffer);
fin.close();
}
public static void output(String step, Buffer buffer) {
System.out.println(step + " : ");
System.out.print("capacity: " + buffer.capacity() + ", ");
System.out.print("position: " + buffer.position() + ", ");
System.out.println("limit: " + buffer.limit());
System.out.println();
}
}

缓冲区的分配
在创建一个缓冲区对象时,会调用静态方法allocate()来指定缓冲区的容量,其实调用 allocate()相当于创建了一个指定大小的数组,并把它包装为缓冲区对象。我们也可以直接将一个数组,包装为缓冲区对象。
public class BufferWrap {
public void myMethod()
{
// 分配指定大小的缓冲区
ByteBuffer buffer1 = ByteBuffer.allocate(10);
// 包装一个现有的数组
byte array[] = new byte[10];
ByteBuffer buffer2 = ByteBuffer.wrap( array );
}
} 缓冲区分片
即根据现有的缓冲区对象来创建一个子缓冲区,也就是在现有缓冲区上切出一片来作为一个新的缓冲区,但现有的缓冲区与创建的子缓冲区在底层数组层面上是数据共享的,也就是说,子缓冲区相当于是现有缓冲区的一个视图窗口。调用slice()方法可以创建一个子缓冲区。
package com.henrysun.javaSE.niostudy;
import java.nio.ByteBuffer;
/**
* 缓冲区分片
* @author henrysun
*
*/
public class BufferSlice {
/**
* @param args
*/
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate( 10 );
// 缓冲区中的数据0-9
for (int i=0; i<buffer.capacity(); ++i) {
buffer.put( (byte)i );
}
// 创建子缓冲区
buffer.position( 3 );
buffer.limit( 7 );
ByteBuffer slice = buffer.slice();
// 改变子缓冲区的内容
for (int i=0; i<slice.capacity(); ++i) {
byte b = slice.get( i );
b *= 10;
slice.put( i, b );
}
buffer.position( 0 );
buffer.limit( buffer.capacity() );
while (buffer.remaining()>0) {
System.out.println( buffer.get() );
}
}
}

只读缓冲区
只读缓冲区可以读取它们,但是不能向它们写入数据。可以通过调用缓冲区的asReadOnlyBuffer()方法,将任何常规缓冲区转换为只读缓冲区,这个方法返回一个与原缓冲区完全相同的缓冲区,并与原缓冲区共享数据,只不过它是只读的。如果原缓冲区的内容发生了变化,只读缓冲区的内容也随之发生变化。
package com.henrysun.javaSE.niostudy;
import java.nio.ByteBuffer;
/**
* 只读缓冲区
* @author Sam Flynn
*
*/
public class BufferReadonly {
/**
* @param args
*/
public static void main(String[] args) {
ByteBuffer buffer=ByteBuffer.allocate(10);
//缓冲区的数字0到9
for(int i=0;i<buffer.capacity();++i)
{
buffer.put((byte)i);
}
//创建只读缓冲区
ByteBuffer readonly=buffer.asReadOnlyBuffer();
//改变原缓冲区的内容
for(int i=0;i<buffer.capacity();++i)
{
byte b=buffer.get(i);
b*=10;
buffer.put(i,b);
}
readonly.position(0);
readonly.limit(buffer.capacity());
//只读缓冲区的内容也跟着改变
while(readonly.remaining()>0)
{
System.out.println(readonly.get());
}
}
}
如果尝试修改只读缓冲区的内容,则会报ReadOnlyBufferException异常。只读缓冲区对于保护数据很有用。在将缓冲区传递给某个 对象的方法时,无法知道这个方法是否会修改缓冲区中的数据。创建一个只读的缓冲区可以保证该缓冲区不会被修改。只可以把常规缓冲区转换为只读缓冲区,而不能将只读的缓冲区转换为可写的缓冲区。
直接缓冲区
直接缓冲区是为加快I/O速度,使用一种特殊方式为其分配内存的缓冲区,JDK文档中的描述为:给定一个直接字节缓冲区,Java虚拟机将尽最大努 力直接对它执行本机I/O操作。也就是说,它会在每一次调用底层操作系统的本机I/O操作之前(或之后),尝试避免将缓冲区的内容拷贝到一个中间缓冲区中 或者从一个中间缓冲区中拷贝数据。要分配直接缓冲区,需要调用allocateDirect()方法,而不是allocate()方法,使用方式与普通缓冲区并无区别。
package com.henrysun.javaSE.niostudy;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* 直接缓冲区
* @author Sam Flynn
*
*/
public class BufferDirect {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
try {
FileInputStream fis=new FileInputStream("F:\\Users\\Sam Flynn\\Desktop\\test1.txt");
FileChannel fcin=fis.getChannel();
FileOutputStream fos=new FileOutputStream("F:\\Users\\Sam Flynn\\Desktop\\test12.txt");
FileChannel fcout=fos.getChannel();
//使用allocateDirect,而不是allocate
ByteBuffer buffer=ByteBuffer.allocateDirect(10);
while (true) {
buffer.clear();
int r = fcin.read( buffer );
if (r==-1) {
break;
}
buffer.flip();
fcout.write( buffer );
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
内存映射文件I/O
内存映射文件I/O是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的I/O快的多。内存映射文件I/O是通过使文件中的数据出现为 内存数组的内容来完成的,这其初听起来似乎不过就是将整个文件读到内存中,但是事实上并不是这样。一般来说,只有文件中实际读取或者写入的部分才会映射到内存中。
package com.henrysun.javaSE.niostudy;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
/**
* 内存映射文件IO
* @author Sam Flynn
*
*/
public class BufferMapped {
static private final int start = 0;
static private final int size = 1024;
/**
* @param args
*/
public static void main(String[] args) {
RandomAccessFile raf;
try {
raf = new RandomAccessFile( "F:\\Users\\Sam Flynn\\Desktop\\test.txt", "rw" );
FileChannel fc = raf.getChannel();
MappedByteBuffer mbb;
try {
mbb = fc.map( FileChannel.MapMode.READ_WRITE,
start, size );
mbb.put( 0, (byte)97 );
mbb.put( 1023, (byte)122 );
raf.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
API
以下是Buffer类的方法签名
package java.nio;
public abstract class Buffer {
public final int capacity( )
public final int position( )
public final Buffer position (int newPositio
public final int limit( )
public final Buffer limit (int newLimit)
public final Buffer mark( )
public final Buffer reset( )
public final Buffer clear( )
public final Buffer flip( )
public final Buffer rewind( )
public final int remaining( )
public final boolean hasRemaining( )
public abstract boolean isReadOnly( );
}这些函数大多数会返回到它们在( this)上被引用的对象。这是一个允许级联调用的类设计方法。级联调用允许这种类型的代码:
buffer.mark( );
buffer.position(5);
buffer.reset( );
被简写为:buffer.mark().position(5).reset( );
注意:缓冲区都是可读的,但并非都可写,每个具体的缓冲区类都通过执行 isReadOnly()来标示其是否允许该缓存区的内容被修改。
推荐阅读:















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









