






概述
本文主要描述基本的数据结构:LSM-Trees和B-tree,其中LSM-Trees构成了leveldb、rocksdb等的基础,B-tree是大多数关系型数据库的基础。我们先来看一个最简单的数据库的雏形:
write() {echo "$1,$2" >>file}read(){grep "^$1," file |sed -e "s/^$1,//" | tail -n 1}
这个数据库的write功能是很简单但是很强大,因为它只需要append-only。与write类似,好多数据库内部使用append-only的log,大型数据库可能需要解决并发控制、磁盘加载和容错处理。
这个数据库的read性能很差,每次查询都需要O(n)的时间。加索引可以解决这个问题。在本文我们会分析几种常见的索引,基本思想都是保存额外的metadata来辅助查询。如果你想通过多种方式来查询,你可能需要做不同的索引。
索引一般来源于数据库的primary数据,这个不会影响数据库的内容,但是会带来额外的开销,尤其是对write操作,因为每次write都需要更新索引。所以索引是一个读写的折中:索引可以增加度的性能,但是会减少写的性能。这一般交给使用者来决定怎么加索引。
哈希索引
最简单的索引结构是key-value结构,类似于大多数语言里的HashMap结构。这种结构将数据的key和offset保存在内存里,真是数据可以存储在disk中,从而突破内存大小的限制。Bitcask就使用了这一结构,一次读根据索引只会有一次磁盘查询。如果数据刚好在缓存里,一次读根本不需要访问磁盘。Bitcask适合key总数小但是更新频繁的情况,否则内存无法承载所有索引。
append-only结构存在超过磁盘大小的风险。一个解决方法是将log拆分成小的segment,当segment大小超过设置时再起一个新的segment来写。然后,我们可以对这些segment做compaction,旨在去除重复的key,保持每隔key的最新值。如下所示:
segment 1a:1b:2c:3d:delete
segment 2a:2b:1c:4d:5
merged segment 1 and segment 2a:1b:2c:3
compaction可以使segment更小,我们可以同时合并多个compaction。另外,segment是不可更改的文件,compaction不会影响正常的读写操作。当compaction在后台线程进行,使用旧的segment进行读。一旦合并操作完成,我们将读操作切换到新的segment,这个时候旧的segnent可以被删除了。
这个时候,每个segment在内存中都有自己的hash table结构了。对于一个查询,我们先从最新的segment的hash table结构查询,如果没有再查询次新的hash table。由于合并过程使得segment个数变少,所以我们并不需要查询过多的文件。但是在实际生产中,还有许多细节要考虑:
- 文件格式。csv并不是最好的格式,二进制格式会更快和更简单。二进制格式会首先编码value的大小,然后跟一个原始的字符串。
- 删除数据。由于采用了append-only的方式,删除数据需要特殊标记,在compaction的时候再真正删除。
- 宕机恢复。如果数据库重启,内存中的哈希索引需要丢失重建,如果从原始数据重建,由于数据量大会很慢,从而导致回复很慢。所以,需要定期的对索引做快照到disk。
- 部分写操作。如果数据写了一半数据库宕机了,需要通过checksums来检查数据的完整性,对不完整的数据进行丢弃。
- 并发控制。由于写操作具有严格的时序性,所以常见的实现方式是单线程来完成。由于segment不可更改,所以可以多线程共同读。
为什么使用append-only而不是原地更新呢?原因如下:
- appending和compaction是顺序操作,远比随机写快得多,尤其是在磁性旋转盘硬盘驱动器上,在flash-based solid state drivers(SSDs)也是如此。
- 并发控制和宕机恢复会很简单。比如,不使用append-only,宕机时你正在写,会导致写一半的状况,使得数据部分新部分旧。
- 合并旧的segment避免了文件碎片。
但是,此时的hash table也会有一些限制:
- hash table必须呆在内存里。当key数量过多时,无法全部保存在内存里。原则上,你可以将hash table保存在disk上,但是实际操作上比较困难,这会需要很多随机IO,当磁盘满了时很难扩充,hash碰撞也会比难处理。
- scan会很困难。比如扫描000-999之间的数据,实际上需要查看所有的hash table。
下面我们会介绍不受这些约束的索引结构。
SSTables和LSM-Trees
在基于log结构的segment中,数据是一系列的key-value结构,这些数据对没有顺序可言。现在,我们要求这些数据对有序,这样的数据格式被称为SSTable(Sorted String Table)。另外,每个key在segment中要求只出现一次,compaction可以确保做到。SStable有很多优势,如下:
- 合并segment简单且高效,即使是在文件大于内存的情况下。可以采用一种类似mergesort的算法(同时开始读取输入文件的第一个key,将最小的key拷贝到输出文件,repeat),从而产生一个新的segment。如果key出现在多个文件中,将使用最新的值。
- 对于读操作,不需要在内存中记录所有的key,只需要记录一些粗力度的索引即可。比如,在一个segment中要查找一个key,可以先定位到具体的block(block是对segment进一步的划分),然后遍历即可。(如果所有的key-value大小一样,可以进行二分查找,但是实际情况每条数据大小并不相同)
- Block可以进行压缩,减少磁盘大小和磁盘IO。
构建SSTable
对于有序segment,依靠append-only是无法构建的,但是可以首先在内存中构建(采用红黑树、AVL树)。SSTable的构建过程如下:
- 当来了一个write操作,将数据插入到内存的平衡树结构中(memtable)。
- 当memtable大小超过设置(一般MB),将memtable写出到磁盘的SSTable。这可以很高效地做到,因为memtable是有序的。这个SSTable会成为最新的SSTable。在写memtable到SSTable的同时,可以令起一个实例来写memtable。
- 当来了一个read操作,先在memtable中查询,再按照新旧顺序在SSTable中查询。
- 后台有一个合并的compaction在合并文件。
为了防止宕机丢memtable的数据,每个写操作需要append到一个disk上的log文件,用于宕机恢复。当memtable写到SSTable后,就可以将对应的log删除了。
LSM-tree的由来
构建SSTable的算法被使用在levelDB和RocksDB中,一种可嵌套key-value存储引擎。levelDB可以在Riak中替代Bitcask,类似的存储引擎被应用到Cassandra和HBase中,二者都是受谷歌BigTable论文的启发。
最开始,这种索引结构出现在Partrick O'Neil et al.的Log-Structured Merge-Tree(LSM-Tree)中,所以后续的基于这种合并、compaction的有序文件都被称作LSM存储引擎。
Lucene是Elasticsearch和Solr使用的全文本搜索技术,虽然全文本索引比较复杂,但是思想类似,它会保存一个key-list的结构,其中list中是所有包含key的文档ID。
性能优化
实际生产中有很多细节需要考虑以提升性能。例如,LSM-tree的算法在查找不存在的key时会很慢,因为需要遍历所有文件。针对这种问题,存储引擎使用了Bloom filters来优化,这是一种逼近所有内容的内存结构,它可以告诉你key是否存在。
针对SSTable的compaction和合并,也有许多策略,最常见的是按照size-tiered和level。levelDB和RocksDB使用level的compaction,HBase使用size-tiered的,Cassandra都支持。在size-tiered中,新的和小的SSTable被合并成老的和大的SSTable。在level中,key 范围被分成更小的SSTable,老的数据被移到单独的level,从而允许增量compaction和减少磁盘空间。
B-Trees
前面讨论了基于log结构的索引,它们被广泛地接受,但是B-Tree还是当前使用最广泛的索引系统。自1970年被引入以来,它被广泛的应用在各种关系型和非关系型数据库中。LSM-Tree将数据库分成了更小的segment,采用顺序写的方式。B-Tree则相反,它将数据库切分成固定大小的blocks(或者叫page),一般是4KB大小(可能更大)。这种设计更贴合硬件系统,因为磁盘也是被组织成固定大小的block。
B-Tree中每一页都有一个地址,允许其他页引用,类似于指针,但是存储在磁盘上。我们可以使用这些页引用构建一个树形页,如下图所示:
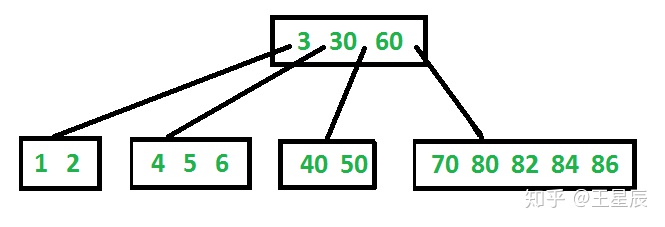
如果要查询一个key,从根节点开始。页里包含了key和到子页的引用,每个引用负责的内容由它前后的key来指定。比如,我们要查找key=40的内容,先在根页中定位到30-60的索引,进入子页继续查询,就能查到key=40的内容。
如果要更新一个已经存在的key,先定位到包含key的页,改变key的value,再将页写回到磁盘(任何引用都不会失效)。
如果要插入一条新数据,需要首先找到能够包含新数据的页,并把新数据插入。如果没有足够的空间来插入,这个页会切分成两个页,同时更新父页。如下所示,插入F:
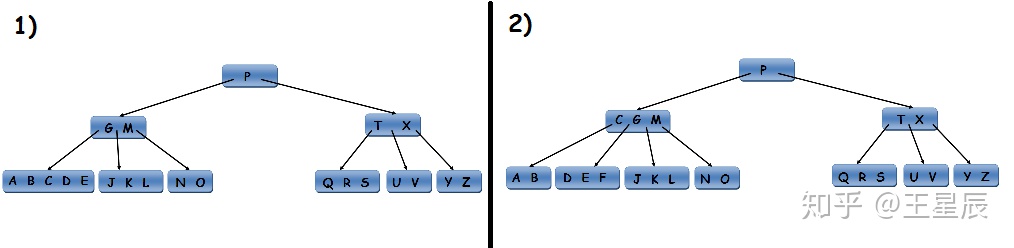
这种算法确保了树的平衡性:n个key的树会有一个O(n)的深度。大部分数据库会有三到四层深度,比如一个4层树,每页大小4KB,每页引用为500,可以存储256TB的数据。
使B-Tree可信赖
B-Tree的写需要覆盖disk的旧页,地址不会变,其他页对它的引用也不会变。可以认为overwriting是一个硬件操作,在一般的磁盘中,先将磁盘头移到正确的位置,等待旋转盘上的正确位置出现,然后overwriting合适的sector。至于SSDs,会更复杂一些,因为SSDs必须擦除和重写存储芯片的一大块。LSM-trees则没有这个问题。
有些操作可能需要同时更新多个页,比如上面提高的的插入分裂操作,这种操作必须确保原子性,否则宕机恢复后会出现孤立页的情况。B-Tree采用了一种额外的数据结构来保证——write-ahead log(WAL,或者叫做redo log),这是一种append-only的文件,需要在具体操作前写入。当出现宕机恢复时,这个log可以确保将B-Tree恢复到一致性的状态。
并发访问也会造成问题。B-Tree采用了一个叫做latches的轻量锁来保证并发访问时的一致性。
B-Tree优化
B-Tree历史悠久,有很多优化,如下所示:
- 一些数据库使用copy-on-write技术来取代WAL。一个更改页被写到另外的地方,同时在父页中创建一个针对此页的新版本。这种方法也可以用于并发控制。
- 我们可以不存储完整的key,可以只存储key的缩写,只要能区分查找边界即可。
- 一般来说,页可以存储在磁盘上的任意空间。对于跨页的scan,这种存储方式很低效。一些数据库尝试将相邻页存在一起。但是实际上做起来比较困难,随着树的增长。LSM-trees则没有这个问题。
- 额外的数据结构允许子页指向父页,可以方便的过渡到相邻页。
- B-Tree中的fractal tree借鉴了日志结构的思想来减少磁盘seek。
B-Tree与LSM-Tree的对比
尽管B-Tree实现起来更自然,但是LSM-Tree也有一定的性能优势。总的来说,LSM-Tree写很快,B-Tree读很快。
LSM-Tree的优势
B-Tree每写一次数据需要额外再写一次WAL,每次更改需要重写整个页。当宕机恢复时,有可能还需要重写一次。LSM-Tree的compaction也会写多次数据。对数据库的一次写导致的多次写磁盘,被称作write amplification。在SSDs中,write amplification更需要关注,因为SSDs的block写是有寿命次数的。在写频繁的操作中,过大的write amplification会影响写性能。LSM-Tree相比B-Tree,能承载更高的写入量,一方面是因为具备更低的write amplification,另外一方面是因为顺序写更快,这种效果在非SSDs的普通磁盘上更加明显。
LSM-Tree可以更好地被压缩,从而节省磁盘IO和磁盘容量。B-Tree在页变更时可能会导致磁盘碎片,导致有些空间不可利用。
SSDs的某些固件采用了日志结构的算法来讲随机写转变成顺序写,更低的write amplification和更少的磁盘碎片显然对SSDs更有利。
LSM-Tree的不足
LSM-Tree的不足主要在于compaction可能会影响系统的性能。磁盘资源有限,很容易发生请求被阻塞在磁盘昂贵的compaction操作中。对吞吐量和平均反应时间的影响通常很小,但是在更高的百分位数上会很高,相比B-Trees的可预测性。
当写入量很大时,compaction可能会对此造成影响。磁盘的写入带宽是有限的,这时需要初始写入(logging和flush)、compaction共享带宽。随着数据量的变大,compaction可能需要更多的磁盘带宽。
如果写入量很大,但是compaction配置的不合理,会发生compaction跟不上写入量的情况,有可能会导致disk耗尽。通常, LSM-Tree不会限制写入吞吐,如果compaction跟不上写入量,需要用户检查并进行相应的配置。
B-Trees的优势是key只存在一个地方,而LSM-Tree则可能多处存在相同的key。对于强事务性的数据库来说,选择B-Trees更好一些,更加容易加锁。
B-Trees可以更好的保持数据一致性,所以不会轻易退出历史舞台。但是对一些新的数据库,LSM-Tree则变得越来越有吸引力。















 5708
5708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









