






SDRAM:Synchronous Dynamic Random Access Memory,同步动态随机存储器
,同步是指 Memory工作需要同步时钟,内部的命令的发送与数据的传输都以它为基准;动态是指存储阵列需要不断的刷新来保证数据不丢失;随机是指数据不是线性依次存储,而是自由指定地址进行数据读写。
SDRAM从发展到现在已经经历了四代,分别是:第一代SDR SDRAM,第二代DDR SDRAM,第三代DDR2 SDRAM,第四代DDR3 SDRAM。
下面是一张描述SDRAM原理的简图:
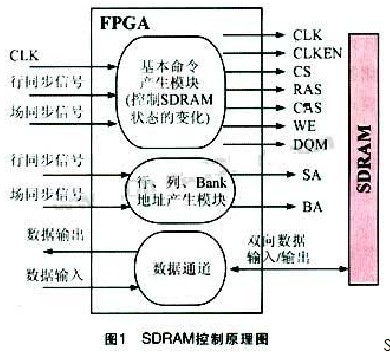
基本原理:
1.行,列&Bank
SDRAM的行地址线和列地址线是分时复用的,即地址线要分两次送出,先送行地址,再送列地址。这样导致两个结果:
- 减少了地址线数量,提高了器件性能
- 寻址过程复杂度增加
新型SDRAM的容量一般比较大,如果还采用简单的阵列结构,就会使存储器字线和位线长度,内部寄生电容以及寄生电阻都变得很大,从而严重影响存取速度。
所以,现在的SDRAM都以Bank为单位来组织,从而把SDRAM分成很多独立的小块。
一般情况下:由Bank地址线BA控制Bank的选择,行,列地址线贯穿所有Bank,每个Bank的数据位宽同整个存储器的相同。同时BA也可以使被选中的Bank处于正常工作模式,同时使没有被选中的Bank工作在低功耗模式下,这个可以降低SDRAM的功耗。
为了减少MOS管数量,降低功耗,提高集成度和存储容量,SDRAM都是利用其自身内部电容存储信息,然而电容要放电,故必须每隔一定时间给电容充电才能使存储在电容里的数据信息不丢失,这就是SDRAM的刷新。
2.SDRAM的基本信号
- 控制信号:片选(CS),同步时钟(CLK),时钟有效(CLKEN),读写选择(WE),数据有效(DQM)
- 地址选择信号:行地址选择(RAS),列地址选择(CAS),行列地址线(SA0-SAxx),分时复用,BANK块地址线(BA0-BAx);
- 数据信号:数据总线(DA0-DAxx),接收数据有效信号DQM
时钟信号:
第一代SDRAM采用单端(Single-Ended)时钟信号,第二代、第三代与第四代由于工作频率比较快,所以采用
可降低干扰的差分时钟信号作为同步时钟。
SDR SDRAM的时钟频率就是数据存储的频率,第一代Memory用时钟频率命名,如pc100,pc133则表明时钟信号为100或133MHz,数据读写速率也为100或133MHz。
之后的第二,三,四代DDR(Double Data Rate)内存则采用数据读写速率作为命名标准,并且在前面加上表示其DDR代数的符号,PC-即DDR,PC2=DDR2,PC3=DDR3。如PC2700是DDR333,其工作频率是333/2=166MHz,2700表示带宽为2.7G
结构,时序与性能的关系:
所谓的影响性能并不是指SDRAM的带宽,频率与位宽固定后,带宽也就不可更改了。但这是理想的情况,在内存的工作周期内,不可能总处于数据传输的状态,因为要有命令、寻址等必要的过程。但这些操作占用的时间越短,内存工作的效率越高,性能也就越好。
为了分析,下面列出DSP的EMIF对SDRAM的控制命令:
- DCAB 关闭所有组(bank),也成为预加载
- DEAC 关闭单个组
- ACTV 激活所选的组,并选择存储器的某一行
- READ 输入起始列地址,开始读操作
- WRT 输入起始行地址,开始写操作
- MRS 模式寄存器组,设置SDRAM模式存储器
- REFR 用内部地址进行自动刷新循环
- SLFREFR 自刷新模式
接着列出C64x系列DSP 的SDRAM 时序参数
- tRC REFR命令到ACTV,MRS或者是REFR命令之间的时间
- tRCD RAS至CAS延迟 广义的tRCD以时钟周期(tCK,Clock Time)数 为单位,比如tRCD=2,就代表延迟周期为两个时钟周期
- tCL SDRAM的CAS延迟时间(即CAS与读命令发出到第一笔数据输出之间的时间,也叫做CAS潜伏期)
- tRP DCAB/DEAC命令到ACTV,MRS或REFR命令之间的时间
非数据传输时间的主要组成部分就是各种延迟与潜伏期。有三个参数对内存的性能影响至关重要,它们是tRCD、tCL和tRP。每条正规的内存模组都会在标识上注明这三个参数值,可见它们对性能的敏感性。
以内存最主要的操作——读取为例进行说明。
tRCD决定了行寻址(有效)至列寻址(读/写命令)之间的间隔,tCL决定了列寻址到数据进行真正被读取所花费的时间,tRP则决定了相同L-Bank中不同工作行转换的速度。现在可以想象一下读取时可能遇到的几种情况(分析写入操作时不用考虑tCL即可):
1.要寻址的行与L-Bank(即LogicalBank,代表一个块)是空闲的。也就是说该L-Bank的所有行是关闭的,此时可直接发送行有效命令,数据读取前的总耗时为tRCD+tCL,这种情况我们称之为页命中(PH,Page Hit)。
2.要寻址的行正好是前一个操作的工作行,也就是说要寻址的行已经处于选通有效状态,此时可直接发送列寻址命令,数据读取前的总耗时仅为tCL,这就是所谓的背靠背(Back to Back)寻址,我们称之为页快速命中(PFH,Page Fast Hit)或页直接命中(PDH,Page Direct Hit)。
3.要寻址的行所在的L-Bank中已经有一个行处于活动状态(未关闭),这种现象就被称作寻址冲突,此时就必须要进行预充电来关闭工作行,再对新行发送行有效命令。结果,总耗时就是tRP+tRCD+CL,这种情况我们称之为页错失(PM,Page Miss)。
显然,PFH是最理想的寻址情况,PM则是最糟糕的寻址情况。上述三种情况发生的机率各自简称为PHR——PH Rate、PFDR——PFH Rate、PMR——PM Rate。
因此,系统设计人员
都尽量想提高PHR与PFHR,同时减少PMR,以达到提高内存
工作效率
的目的。
二、增加PHR的方法
显然,这与预充电管理策略有着直接的关系,目前有两种方法来尽量提高PHR。自动预充电技术就是其中之一,它自动的在每次行操作之后进行预充电,从而减少了日后对同一L-Bank不同行寻址时发生冲突的可能性。但是,如果要在当前行工作完成后马上打开同一L-Bank的另一行工作时,仍然存在tRP的延迟。怎么办? 此时就需要L-Bank交错预充电了。
VIA的4路交错式内存控制就是在一个L-Bank工作时,对下一个要工作的L-Bank进行预充电。这样,预充电与数据的传输交错执行,当访问下一个L-Bank时,tRP已过,就可以直接进入行有效状态了。目前VIA声称可以跨P-Bank进行16路
内存交错
,并以LRU算法进行预充电管理。
转载于:https://blog.51cto.com/datou97/731085















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









