






1. 写在前面
“JVM 解剖公园”是一个持续更新的系列迷你博客,阅读每篇文章一般需要5到10分钟。限于篇幅,仅对某个主题按照问题、测试、基准程序、观察结果深入讲解。因此,这里的数据和讨论可以当轶事看,不做写作风格、句法和语义错误、重复或一致性检查。如果选择采信文中内容,风险自负。
Aleksey Shipilёv,JVM 性能极客
推特 @shipilev
问题、评论、建议发送到 aleksey@shipilev.net"">aleksey@shipilev.net
2. 问题
有 512MB 可用内存,参数设为-Xms512m -Xmx512m,为什么虚拟机会报告“内存不足无法继续”启动失败?
3. 理论
JVM 是本地应用程序,维持和存储内部数据结构需要占用内存,包括程序代码、生成的机器代码、堆元数据、类元数据、内部统计数据等等。这些没有包括在 Java 堆中,因为大多数是本地程序,用 C 语言在堆中申请或者通过 mmap 进行内存映射。JVM 做了很多工作,期望应用程序在长时间运行过程中能加载更多类、支持更多的生成代码。在内存受限的情况下,这些默认值对运行时间较短的应用显得过高。
从 OpenJDK 8 开始加入了一个很好的虚拟机内部特性,称为“本地内存跟踪(Native Memory Tracking NMT)”:监测所有虚拟机内部分配的内存,包括分类信息、内存分配者等等。对于理解虚拟机如何使用内存非常有价值。
配置 -XX:NativeMemoryTracking=summary 选项可以启用 NMT。可以使用 jcmd 转储当前 NMT 数据,也可以使用 -XX:+PrintNMTStatistics 在 JVM 中止时请求数据转储。加上 -XX:NativeMemoryTracking=detail 选项可以获取 mmap 内存映射和 malloc 回调。
大多数时候summary信息就足够了。当然也可以通过detail查看详细日志,了解由谁分配了内存以及用途,阅读虚拟机源代码,配合虚拟机不同选项查看带来的影响。以 “Hello World” 为例:
public class Hello {
public static void main(String... args){
System.out.println("Hello");
}
}
很明显,在已分配的内存中 Java 堆占了很大一部分,让我们配置 -Xmx16m -Xms16m 查看具体使用情况:
Native Memory Tracking:
Total: reserved=1373921KB, committed=74953KB
- Java Heap (reserved=16384KB, committed=16384KB)
(mmap: reserved=16384KB, committed=16384KB)
- Class (reserved=1066093KB, committed=14189KB)
(classes #391)
(malloc=9325KB #148)
(mmap: reserved=1056768KB, committed=4864KB)
- Thread (reserved=19614KB, committed=19614KB)
(thread #19)
(stack: reserved=19532KB, committed=19532KB)
(malloc=59KB #105)
(arena=22KB #38)
- Code (reserved=249632KB, committed=2568KB)
(malloc=32KB #297)
(mmap: reserved=249600KB, committed=2536KB)
- GC (reserved=10991KB, committed=10991KB)
(malloc=10383KB #129)
(mmap: reserved=608KB, committed=608KB)
- Compiler (reserved=132KB, committed=132KB)
(malloc=2KB #23)
(arena=131KB #3)
- Internal (reserved=9444KB, committed=9444KB)
(malloc=9412KB #1373)
(mmap: reserved=32KB, committed=32KB)
- Symbol (reserved=1356KB, committed=1356KB)
(malloc=900KB #65)
(arena=456KB #1)
- Native Memory Tracking (reserved=38KB, committed=38KB)
(malloc=3KB #41)
(tracking overhead=35KB)
- Arena Chunk (reserved=237KB, committed=237KB)
(malloc=237KB)
好吧,对于16MB Java 堆来说占用75MB内存显然是出乎意料之外。
4. 缩减内存:常见方法
让我们遍历 NMT 的输出结果,看看哪些部分否可以调优。
先从熟悉的部分下手:显,在已分配的内存中 Java 堆占了很大一部分,让我们配置 -Xmx16m -Xms16m 查看具体使用情况:
- GC (reserved=10991KB, committed=10991KB)
(malloc=10383KB #129)
(mmap: reserved=608KB, committed=608KB)
这里描述了 GC 本地结构。日志中可以看到,GCmalloc内存约10MBmmap内存约0.6MB。如果这些结构与堆相关,像 Marking Bitmap、Card Table、Remembered Set 等,可以预见随着堆大小增加,这部分占用的内存也会随之增大。实际结果也的确如此:
# Xms/Xmx = 512 MB
- GC (reserved=29543KB, committed=29543KB)
(malloc=10383KB #129)
(mmap: reserved=19160KB, committed=19160KB)
# Xms/Xmx = 4 GB
- GC (reserved=163627KB, committed=163627KB)
(malloc=10383KB #129)
(mmap: reserved=153244KB, committed=153244KB)
# Xms/Xmx = 16 GB
- GC (reserved=623339KB, committed=623339KB)
(malloc=10383KB #129)
(mmap: reserved=612956KB, committed=612956KB)
malloc分配的内存很可能是用 C 分配的堆空间,用作并行 GC 中任务队列;mmap分配的内存存储了 bitmap。随着堆大小增加,这部分占用的内存会占到配置堆大小的3%至4%。这会带来实际部署问题,就像文章一开始提出的:配置的堆大小会获取所有可用物理内存,超过内存限制。可能会触发内存交换,也可能会引起 OOM 异常 JVM 停止运行。
但是这种开销还依赖于使用的 GC,不同的 GC 会用不同的方式表示 Java 堆。例如,使用-XX:+UseSerialGC让 OpenJDK 切换到最轻量级 GC 后,在我们的测试用例上运行会得到戏剧化的结果:
-Total: reserved=1374184KB, committed=75216KB
+Total: reserved=1336541KB, committed=37573KB
-- Class (reserved=1066093KB, committed=14189KB)
+- Class (reserved=1056877KB, committed=4973KB)
(classes #391)
- (malloc=9325KB #148)
+ (malloc=109KB #127)
(mmap: reserved=1056768KB, committed=4864KB)
-- Thread (reserved=19614KB, committed=19614KB)
- (thread #19)
- (stack: reserved=19532KB, committed=19532KB)
- (malloc=59KB #105)
- (arena=22KB #38)
+- Thread (reserved=11357KB, committed=11357KB)
+ (thread #11)
+ (stack: reserved=11308KB, committed=11308KB)
+ (malloc=36KB #57)
+ (arena=13KB #22)
-- GC (reserved=10991KB, committed=10991KB)
- (malloc=10383KB #129)
- (mmap: reserved=608KB, committed=608KB)
+- GC (reserved=67KB, committed=67KB)
+ (malloc=7KB #79)
+ (mmap: reserved=60KB, committed=60KB)
-- Internal (reserved=9444KB, committed=9444KB)
- (malloc=9412KB #1373)
+- Internal (reserved=204KB, committed=204KB)
+ (malloc=172KB #1229)
(mmap: reserved=32KB, committed=32KB)
这里 “GC” 和 “Thread” 部分得到了改善。前者由于分配的元数据更少,后者是因为从默认的 Parallel GC 变为 Serial GC 后,需要的 GC 线程也随之减少。这意味着可以通过调整 Parallel、G1、CMS、Shenandoah 等 GC 的线程数量改进性能。接下来会讨论线程栈。注意,更换 GC 或者更改 GC 线程数量将影响性能,通过修改可以在时间、空间上找到合适的平衡点。
不仅如此,由于元数据表示方式少有不同 “Class” 部分也得到了改进。我们还能继续提升 “Class” 性能吗?可以试试类数据共享(Class Data Sharing CDS),使用-Xshare:on开启:
-Total: reserved=1336279KB, committed=37311KB
+Total: reserved=1372715KB, committed=36763KB
-- Symbol (reserved=1356KB, committed=1356KB)
- (malloc=900KB #65)
- (arena=456KB #1)
-
+- Symbol (reserved=503KB, committed=503KB)
+ (malloc=502KB #12)
+ (arena=1KB #1)
在共享内存中加载预解析表示,这样又节省了0.5MB内部符号表空间。
接下来关注线程,相关日志如下:
- Thread (reserved=11357KB, committed=11357KB)
(thread #11)
(stack: reserved=11308KB, committed=11308KB)
(malloc=36KB #57)
(arena=13KB #22)
仔细查看日志内容,可以看到 “Thread” 大部分内存被线程堆栈占用。用 -Xss 选项可以把堆栈大小从默认值缩小到示例中的1M。注意:这样修改可能会产生 StackOverflowException 风险。如果确实需要修改,请务必测试软件各种配置检查可能带来的不良影响。试着用 -Xss256k 选项设为256KB,结果如下:
-Total: reserved=1372715KB, committed=36763KB
+Total: reserved=1368842KB, committed=32890KB
-- Thread (reserved=11357KB, committed=11357KB)
+- Thread (reserved=7517KB, committed=7517KB)
(thread #11)
- (stack: reserved=11308KB, committed=11308KB)
+ (stack: reserved=7468KB, committed=7468KB)
(malloc=36KB #57)
(arena=13KB #22)
还不错,又少了4MB。当然,对于线程多的应用效果更明显。线程很可能是仅次于 Java 堆的第二大内存消费者。
继续看线程部分,JIT 编译器本身也用到了线程。这就解释了为什么即使把堆栈大小设置为256KB,但上面的数据仍然显示堆栈大小是7517 / 11 = 683 KB。使用-XX:CICompilerCount=1减少编译器线程数,设置-XX:-TieredCompilation只启用最新编译层:
-Total: reserved=1368612KB, committed=32660KB
+Total: reserved=1165843KB, committed=29571KB
-- Thread (reserved=7517KB, committed=7517KB)
- (thread #11)
- (stack: reserved=7468KB, committed=7468KB)
- (malloc=36KB #57)
- (arena=13KB #22)
+- Thread (reserved=4419KB, committed=4419KB)
+ (thread #8)
+ (stack: reserved=4384KB, committed=4384KB)
+ (malloc=26KB #42)
+ (arena=9KB #16)
喔,三个线程和它们的堆栈都没有了!同样,这种方式会影响性能:编译器线程越少意味着预热越慢。
在内存受限情况下,减少虚拟机占用内存的常见方法包括,减小 Java 堆大小、选择合适的 GC、减少虚拟机线程的数量、减小 Java 线程堆栈大小和减少线程数量。通过这些办法,16MB Java 堆测试的优化结果如下:
-Total: reserved=1373922KB, committed=74954KB
+Total: reserved=1165843KB, committed=29571KB
5. 缩减内存:大胆实验
这一部分提出的建议有点疯狂。使用有风险,请不要在家里自行尝试。
这一部分的优化,包括调整虚拟机内部设置,不保证优化有效,有可能会出现崩溃和其他意外。比如,虽然可以通过编码控制 Java 应用的堆栈大小,但我们并不知道 JVM 内部究竟发生了什么,因此减少虚拟机线程的堆栈大小是很危险的。不过,用-XX:VMThreadStackSize=256尝试一下还是很有意思的。
-Total: reserved=1165843KB, committed=29571KB
+Total: reserved=1163539KB, committed=27267KB
-- Thread (reserved=4419KB, committed=4419KB)
+- Thread (reserved=2115KB, committed=2115KB)
(thread #8)
- (stack: reserved=4384KB, committed=4384KB)
+ (stack: reserved=2080KB, committed=2080KB)
(malloc=26KB #42)
(arena=9KB #16)
是的,又少了2MB编译器和 GC 线程栈大小。
继续在编译器代码上下功夫:为什么不试着减少初始代码缓存(即生成的代码区域)大小呢?输入-XX:InitialCodeCacheSize=4096(字节):
-Total: reserved=1163539KB, committed=27267KB
+Total: reserved=1163506KB, committed=25226KB
-- Code (reserved=49941KB, committed=2557KB)
+- Code (reserved=49941KB, committed=549KB)
(malloc=21KB #257)
- (mmap: reserved=49920KB, committed=2536KB)
+ (mmap: reserved=49920KB, committed=528KB)
- GC (reserved=67KB, committed=67KB)
(malloc=7KB #78)
一旦编译的工作加重,占据的内存会马上膨胀起来,但目前为止还不错。
仔细看一下 “Class” 部分,可以看到 Hello World 程序占用的(Committed)4MB内存中大部分存储的是元数据。可以使用-XX:InitialBootClassLoaderMetaspaceSize=4096(字节)减少大小:
-Total: reserved=1163506KB, committed=25226KB
+Total: reserved=1157404KB, committed=21172KB
-- Class (reserved=1056890KB, committed=4986KB)
+- Class (reserved=1050754KB, committed=898KB)
(classes #4)
- (malloc=122KB #83)
- (mmap: reserved=1056768KB, committed=4864KB)
+ (malloc=122KB #84)
+ (mmap: reserved=1050632KB, committed=776KB)
- Thread (reserved=2115KB, committed=2115KB)
(thread #8)
执行了所有这些大胆的优化后,Java 堆大小更接近16MB,最多只浪费8.5MB。
-Total: reserved=1165843KB, committed=29571KB
+Total: reserved=1157404KB, committed=21172KB
如果在构建 JVM 时进行优化应该可以更进一步。
6. 总结
有趣的是,可以看到本地开销如何随着 Java 堆大小发生变化:
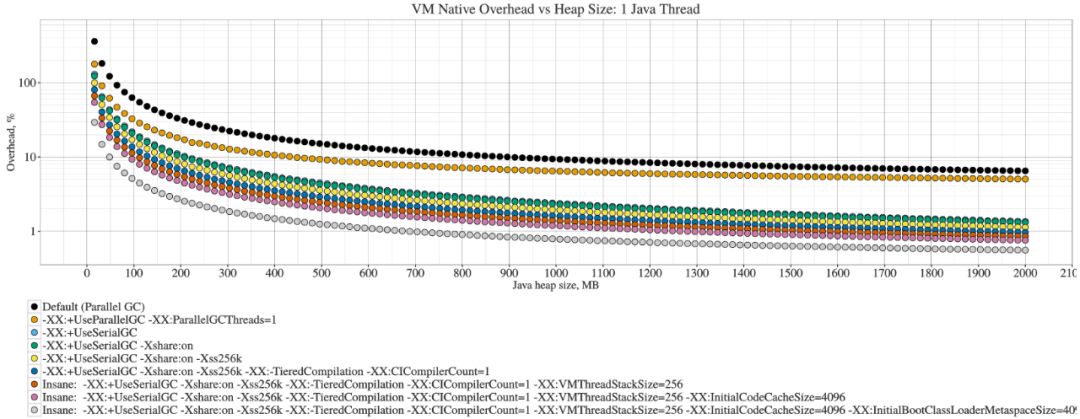
上图证实了我们的直觉,即 GC 开销与 Java 堆大小之前比例为常数关系。当虚拟机成为内存总开销一部分时,虚拟机本地开销才会在小堆空间上起作用。上面的图片忽略了第二重要因素——线程栈。
7. 观察
JVM 的默认配置通常是为长时间运行的服务器应用准备的,包括 GC、内部数据结构的初始大小、堆栈大小等也是如此,因此可能不适用于短时间运行的内存受限应用程序。了解当前 JVM 配置条件下哪些部分占用内存最多,有助于在主机上加入更多 JVM。
用 NMT 探索虚拟机内存分配情况是一种非常具有启发性的练习,能让我们立刻知道从哪里入手优化应用占用的内存。在性能管理系统加入 NMT 在线监视,非常有助于在应用实际生产环境中调整 JVM 参数。比起解析 /proc/$pid/maps 中不透明的内存映射来确定 JVM 究竟在做什么要容易得多。
还可以参考阅读 Christine Flood 的 “OpenJDK 与容器”。
developers.redhat.com/blog/2017/04/04/openjdk-and-containers/















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









