






神经模型搜索(Neural Architecture Search,NAS)是一种自动化的模型结构搜索方法,旨在代替深度学习专家选择最优的网络模型结构。传统的NAS方法都是针对小规模数据库设计的,直接迁移到大型数据库上无法保证模型的预测效果。针对这一缺陷,华中科大与地平线合作提出了一种针对大规模NAS问题的弹性结构迁移方法EAT-NAS,该方法大大加快了在如ImageNet这种大型数据库上的搜索进程。与现有的大规模NAS方法相比,EAT-NAS在八块Titan X配置的机器上仅需要5天就可以完成整个搜索过程,显著减少了搜索时间,并且得到的最优模型仍具有较高的准确度。我们对该方法做了简要介绍,本文是AI前线第67篇论文导读。
背景
由人类专家设计神经网络架构,通常需要繁琐的实验过程还容易出现错误。为了让这个过程更加高效化,许多神经结构搜索方法(Neural Architecture Methods,NAS)被提出。先不说结果如何,大部分NAS方法都需要非常昂贵的计算资源。例如2017年ICLR的论文《Neural architecture search with reinforcement learning》使用了800块GPU在CIFAR-10图像分类任务上花费了28天的时间进行搜索。CIFAR-10只是一个非常小规模的数据库,而实际应用的情景往往都是大规模的数据,因此NAS方法在大规模数据库上的局限性成为了阻碍其发展的关键因素。
许多现有的NAS方法通过在小规模数据库上进行结构搜索,然后针对大规模数据库对深度和宽度进行手动调整。这一机制广泛的应用于NAS领域。但是由于大规模数据库与小规模数据库之间域的不同,在小规模数据库上的模型搜索算法应用于大规模数据库时,并不能保证其效果。
在这篇论文中,作者针上述的限制,提出了一种更合理的解决方案。作者使用迁移学习的方法从将针对小规模任务的结构应用到大规模任务上并进行微调。更详细地,作者使用了基于弹性框架的NAS方法——联赛选择,即首先使用现有的方法在小数据库上搜索神经框架,然后将上一步得到的框架作为初始化种子再在大型数据库上进行搜索。
总得来说,这篇文章的亮点主要可概括为:
提出一种弹性结构迁移机制(Elastic Architecture Transfer Machanism)用来弥补大规模任务和小型任务上进行结构搜索的差异。
由于使用了小规模数据库上的最优模型作为大型任务的初始化种子,该方法有效节省了在大规模数据库上进行模型搜索的时间。
在节省了计算资源的情况下,最终的模型仍然能达到不错的性能。
相关方法
本文提出的EAT-NAS方法,是在基于进化算法(Evolutionary Algorithm,EA)的NAS方法上进行改进的。进化算法在NAS领域的应用非常广泛,其详细算法如下表所示:

该算法首先在搜索空间中使用随机生成的P模型对种群进行初始化,随后将每个模型在数据库上进行训练和评估以获得模型的准确率。在每个进化周期里,S是从种群中随机采样的模型。其中分数最高的模型M_best和分数最低的模型M_worst会被选出进行下一步处理。对M_best添加一些变换即可得到变异的模型,变异的模型会被添加到种群中进行训练、评价,同时M_worst会被移除。上述的搜索进程便被称为联赛选择算法。最终,再对前k个效果最好的模型进行重训练,选择其中最好的模型即可完成整个搜索过程。
本文算法
在将模型结构用于大规模数据库时,许多NAS方法只不过是依赖人类专家的先验知识,手动地修改模型的宽度和深度。与这些方法不同,EAT-NAS对基本模型结构的各个元素进行微调得到最终可以适应大规模数据库的模型,这些元素包括结构、尺度、操作等。通过使用在小规模数据库上搜索得到的基本模型,EAT算法可以有效地加速大规模任务上模型的搜索进程。
1 算法框架

EAT-NAS的基本思想如上图所示,首先使用进化算法在小型任务上搜索最优模型,然后将其作为第二阶段的初始化种子,再使用进化算法对大规模任务进行搜索。由于使用了小任务上的最佳模型对大任务的初始种群做初始化,在大规模任务上的搜索进程明显会比从零开始的收敛速度快得多。作者使用了种群质量判别函数(Population Quality)以便在进化过程中对模型种群做出更好的评价。此外,作者在第二阶段使用了后代结构生成器(offspring architecture generator)来产生新的结构。为了同时对模型的准确度和尺寸进行优化,作者使用了Pareto优化进行求解,Pareto优化是多目标优化问题中一种求最优解集的方法。
2 搜索空间
对于结构搜索来说,确定一个好的搜索空间是非常必要的。作者使用了MobileNetV2作为骨架网络,整个网络的结构如下图所示:

网络被分为了多个block,每个block的结构彼此不同,它们各自包含了多个层,每个层表示一种在当前block中进行的多次的操作。对于每个block,作者给出了更详细的选择条件:
卷积操作:深度可分离卷积(SepConv)、膨胀率为{3,6}的移动反转瓶颈卷积(MBConv)。
卷积核大小:3X3,5X5,7X7
跳跃连接:每层之间是否添加跳跃连接。
宽度因子:输出相对于输入的宽度扩张比率[0.5, 1.0, 1.5, 2.0]
深度因子:每个block包含的层数[1, 2, 3, 4]
其中,每个block的第一层默认丢弃降采样和宽度扩张操作。
作者在搜索空间中使用了编码的方式表示网络结构,以便对神经结构进行操作。整个网络可以使用一个block集合来表示:
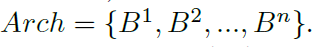
每个block包含了上述的五个元素,因此使用一个元组对其进行表示:
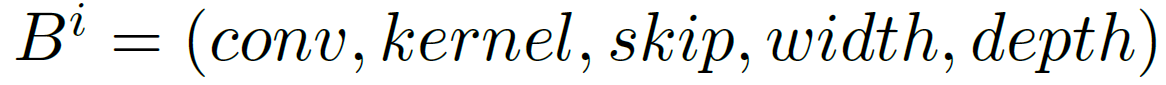
所有对网络结构进行的操作都通过改变编码的形式进行。
3 种群质量
在训练过程中,仅根据模型预测的精确度不足以判断其是否收敛。尤其是在搜索空间中,参数是共享的,这就更加难以判断精度的提高是由于参数共享还是由于更好的模型性能。因此作者提出了一种自定义的函数近似地评估模型种群质量:
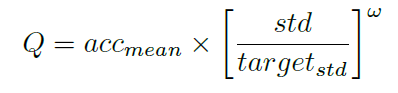
其中,acc_mean表示种群中模型的平均精确度,std表示模型精度的标准差,w是由超参数进行控制的权重因子:
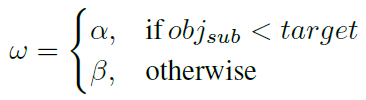
4 规模搜索
许多NAS方法都会基于先验知识,将模型的规模设为一个固定值。EAT-NAS则在深度和宽度层面上,都对模型的结构进行了搜索。为了加速搜索的过程,作者使用了两种不同的方法分别在深度和宽度层面进行参数共享。
- 宽度层面的共享算法如下表所示,除了共享的参数以外,K_l的其余参数均使用随机初始化。

- 深度层面的共享方法如下所示,其中U和W分别是含有l_u层的两个相关的block的参数,这里使用W的参数对U进行共享。
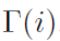 是一个服从正态分布的参数随机初始化函数。
是一个服从正态分布的参数随机初始化函数。
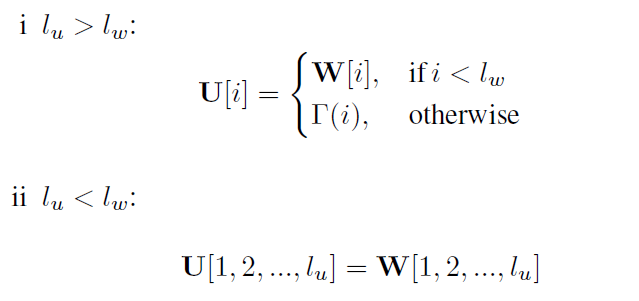
5 后代结构生成器
在完成了基础模型结构的搜索后,需要将基本结构迁移到大规模任务上。作者使用了后代结构生成器(Offspring Architecture Generator,OAG)从模型种群中生成新的模型种群,OAG会将基础模型作为新种群的初始化种子。同时,作者还定义了一个新的变换函数,通过添加一些扰动,使得输入框架可以更加轻量并同质化。算法3是该变换函数的详细过程:

在使用后代结构生成器产生新的种群后,再使用算法1中的进化算法进行最优化搜索,最终即可得到适用于大规模任务的模型结构。
实验结果
在CIFAR-10数据库上进行搜索
在CIFAR-10上的实验可以分为两步:结构搜索和结构进化。CIFAR-10包含5w张训练图像和1w张测试图像。作者对原始训练集进行2/8划分,分别作为验证集和训练集。CIFAR-10的测试集仅用来在完成最后的模型搜索后进行测试。实验过程中使用了标准的预处理和数据增强步骤。所有的图像都使用了通道均值与标准差进行白化。训练过程的详细参数可以参阅论文。
作者最终选择了前8个训练好的模型进行重训练,挑选其中精确度最高的作为基本结构。最终基本结构达到了96.42%的平均测试精度,模型参数大小仅为2.04M,平均精度的标准差为0.05。
迁移到ImageNet数据库
这里使用了上一步得到的基础模型作为ImageNet任务的种子来生成新的模型。搜索进程在整个ImageNet数据库上进行。作者使用OAG在基本结构的基础上产生了64个新的结构。CIFAR-10上得到的基本结构和迁移到ImageNet上网络结构如下图所示:

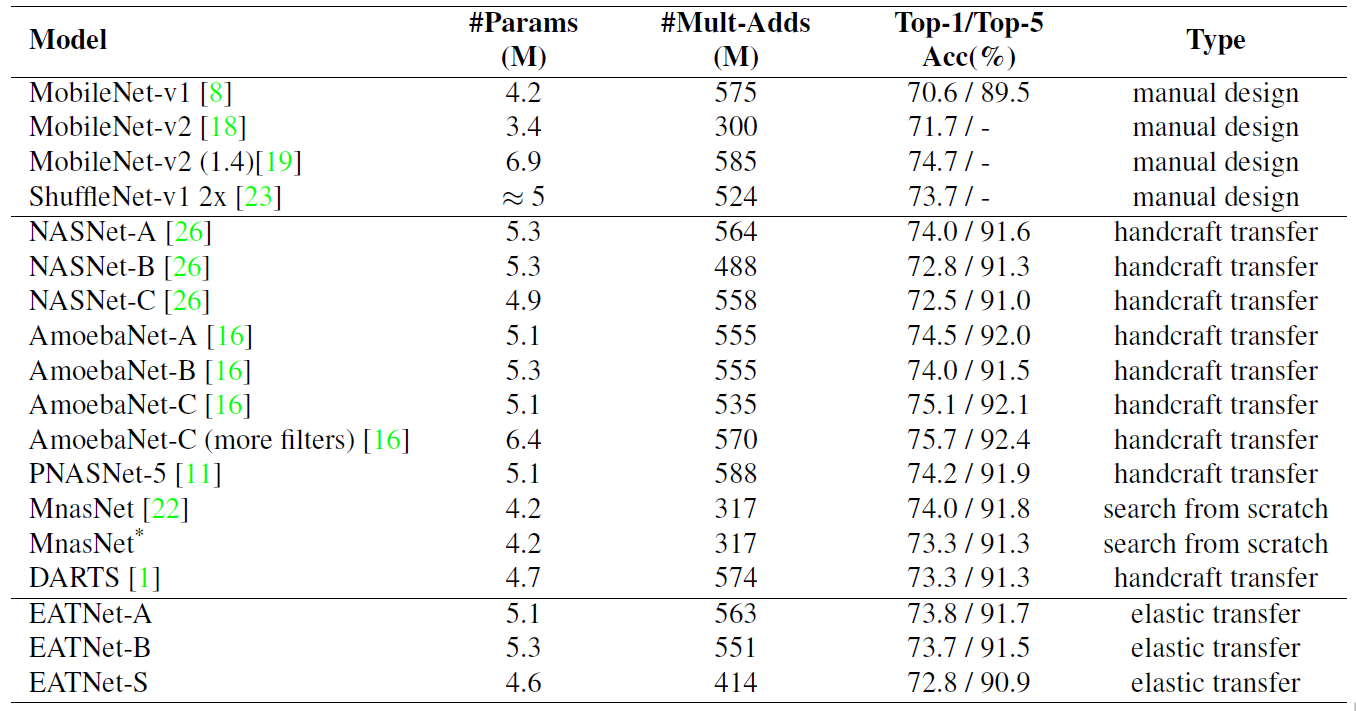
在ImageNet数据库上,整个进化过程经过100次突变循环即达到了收敛。也就是说,在基本模型的基础上,算上最开始的64个模型,仅采样了164个模型即找到了最优模型。而在类似的MnasNet中则需要采样约8k个模型才可达到最优,是EAT-NAS的50倍。最终的模型精度如下表所示,EATNet表示本文提出方法得到的模型。
总结
总的来说,EAT-NAS算法使用了一种很巧妙的设计,将模型在小规模数据库上学习到的信息用于大规模数据库上的模型搜索。作者将迁移学习的思想与进化算法相结合,在基本没有损失模型性能的基础上,极大地加速了整个优化进程。
论文原文链接:
EAT-NAS: Elastic Architecture Transfer for Accelerating Large-scale Neural Architecture Search














 950
950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









