







Hive-Web是我司Web端查询Hive数据的服务,功能上比较简单,用户在Web上写一个SQL,Hive-Web将SQL提交到后端的服务执行查询,得到结果的hdfs路径,然后通过hadoop的fs读取文件,将其返回给用户。
这样简单地一个应用最近经常OldGC次数超多,用户反映说网页上日志不刷新了,查询还在Running,但是状态确实Failed的了,总之就是服务端不响应请求了。
性能调优上我一直比较懵,这次也一样,没辙,仔细查吧~
主机:dw-hive-web02.nh
心跳时间:2016-05-24 20:03:31
查看了当时告警机器的CAT心跳,发现catalina-exec线程数120个,正常情况下为10个。
其中:
BLOCKED:35个
RUNNABLE:32个
TIMED_WAITING:32个
WAITING:21个
BLOCKED的线程都卡在这里:
145: "catalina-exec-411" Id=172907 BLOCKED on org.apache.log4j.spi.RootLogger@625fc53f owned by "catalina-exec-542" Id=174535
at org.apache.log4j.Category.callAppenders(Category.java:204)
- blocked on org.apache.log4j.spi.RootLogger@625fc53f
at org.apache.log4j.Category.forcedLog(Category.java:391)
at org.apache.log4j.Category.log(Category.java:856)
at org.slf4j.impl.Log4jLoggerAdapter.error(Log4jLoggerAdapter.java:517)
at com.dianping.cache.memcached.MemcachedClientImpl.get(MemcachedClientImpl.java:801)
at com.dianping.avatar.cache.CacheServiceContainer.get(CacheServiceContainer.java:401)
at com.dianping.avatar.cache.CacheServiceContainer.get(CacheServiceContainer.java:372)
at com.dianping.avatar.cache.DefaultCacheService$8.execute(DefaultCacheService.java:199)catalina-exec-542如下:
194: "catalina-exec-542" Id=174535 RUNNABLE
at java.io.FileOutputStream.writeBytes(Native Method)
at java.io.FileOutputStream.write(FileOutputStream.java:282)
at sun.nio.cs.StreamEncoder.writeBytes(StreamEncoder.java:202)
at sun.nio.cs.StreamEncoder.implFlushBuffer(StreamEncoder.java:272)
at sun.nio.cs.StreamEncoder.implFlush(StreamEncoder.java:276)
at sun.nio.cs.StreamEncoder.flush(StreamEncoder.java:122)
at java.io.OutputStreamWriter.flush(OutputStreamWriter.java:212)
at org.apache.log4j.helpers.QuietWriter.flush(QuietWriter.java:59)
dw-hive-web主机上tomcat配置的最大线程数为120个,排队数最大30个,超过maxQueueSize会拒绝请求:
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="120" maxQueueSize="30" minSpareThreads="10" maxIdleTime="60000"/>
<Connector executor="tomcatThreadPool" protocol="org.apache.coyote.http11.Http11Protocol"
port="8080" URIEncoding="UTF-8" compression="off" enableLookups="false" maxPostSize="0"
maxKeepAliveRequests="20" bufferSize="8192" connectionTimeout="5000"
redirectPort="8443" server="DPServer" emptySessionPath="true"/>bug修复前的tcp链接数:
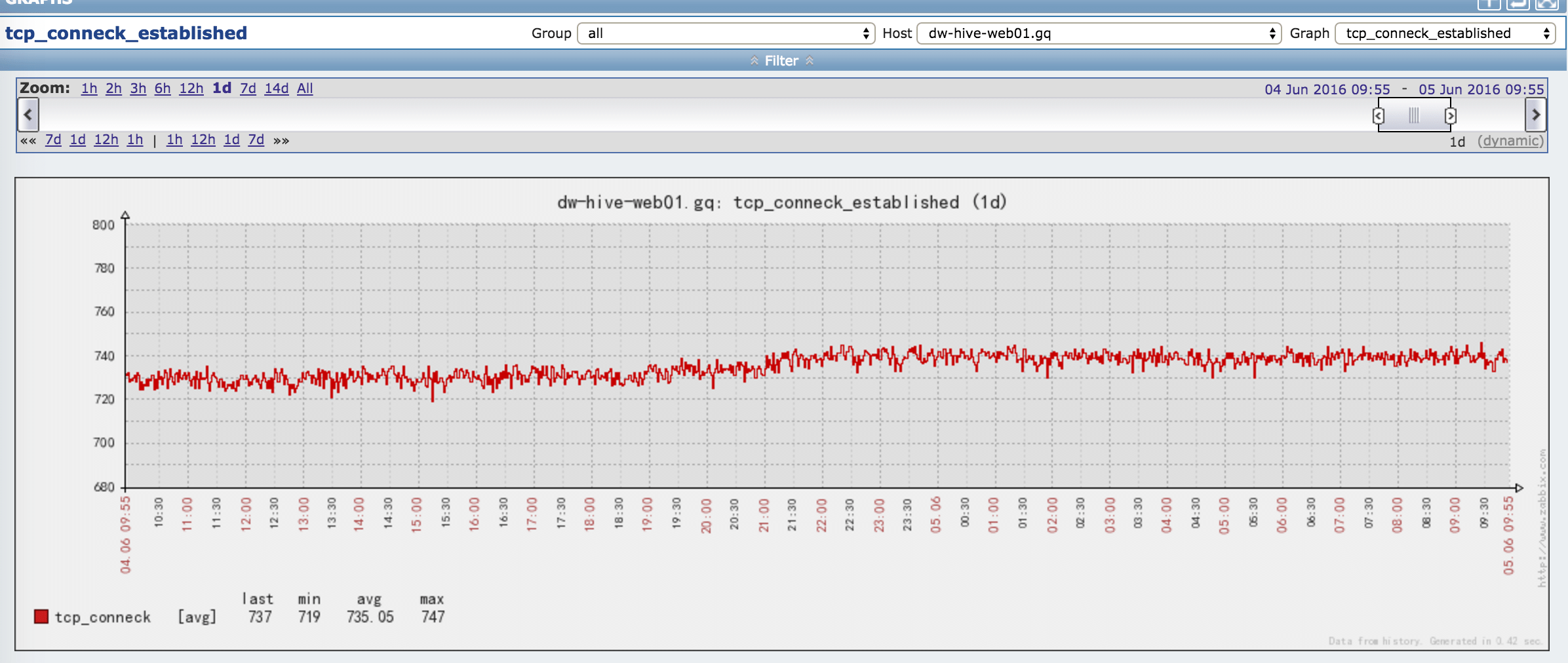
bug修复之后,tcp减少的很明显:

代码修改如下,finally中的代码是后加的,之前的bufferedReader没有close:
原因猜想是没有关闭的bufferReader占用了内存,链接的释放时间是20分钟,负载高的时候这部分堆内存短时间是释放不掉的,内存逐渐吃紧引起了Old GC(欢迎看到博客的小伙伴拍砖,对于JVM调优之类的我简直就是小白)
后记:
1、修改之前每台机器上有3000+处于CLOSE_WAIT的TCP连接(而且处于接收队列的数据量都不为0),都是连到hadoop的,TCP断开的四次挥手中说是hadoop端主动断开了链接,没有收到本应用的FIN,于是连接处于CLOSE_WAIT状态。
2、认真写代码真的很重要,生产环境中任何一个小bug都可能引起严重问题,而定位问题之路还挺漫长,少给后人挖坑是一个程序员的终极追求之一~
3、谁能告诉我怎么修改博客的模板,整个模板都很难看有木有!
refer:
1、https://tomcat.apache.org/tomcat-6.0-doc/config/executor.html
2、TCP连接断开过程-四次挥手:http://blog.163.com/guixl_001/blog/static/4176410420128310597692/















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









