






我目前正在做图像数据增强的深度和有效性的研究。这项研究的目的是学习怎样增加只有有限或少量数据的数据集大小,增强训练的卷积网络模型的鲁棒性。
需要列出所有可以想到的图像增强的方法,并将这些方法进行组合,尝试和改善图像分类模型的性能。一些较简单的增强方法有翻转,平移,旋转,缩放,分离r,g,b颜色通道和添加噪声。更好一些的增强方法是生成对抗网络模型,有时交替使用遗传算法和生成对抗网络。 还有一些创造性的方法,比如将Instagram 样式的高亮滤镜应用于图像,应用随机区域锐化滤镜,以及基于聚类技术添加平均图像。 本文将介绍怎样使用 NumPy 对图像进行扩充。
下面列出了一些扩充技术的说明,如果你能想到任何其他方法来增强图像,提高图像分类器的质量,请留言一起讨论。

原始图像
增强
所有的代码都没有使用 OpenCV 库,只使用了 Numpy。
# 加载图像
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
img = Image.open('./NIKE.png')
img = np.array(img)
plt.imshow(img)
plt.show()
翻转(Flipping)
翻转图像是最流行的图像数据增强方法之一。这主要是由于翻转图像的代码比较简单,而且对于大多数问题而言,翻转图像会增强模型的性能。下面的模型可以被认为是看到左鞋而不是右鞋,因此通过这种数据增加,模型对于看到鞋的潜在变化变得更加有鲁棒性。

# 用 Numpy 翻转
flipped_img = np.fliplr(img)
plt.imshow(flipped_img)
plt.show()
平移(Translations)
很容易想象使用目标检测的分类器进行平移可以增加它的性能。好像这个分类模型试图检测鞋子何时在图像中而不是是否在图像中。 平移操作将有助于它看不到整个鞋子的情况下检测出鞋子。

# 向左平移
for i in range(HEIGHT, 1, -1):
for j in range(WIDTH):
if (i < HEIGHT-20):
img[j][i] = img[j][i-20]
elif (i < HEIGHT-1):
img[j][i] = 0
plt.imshow(img)
plt.show()

# 向右平移
for j in range(WIDTH):
for i in range(HEIGHT):
if (i < HEIGHT-20):
img[j][i] = img[j][i+20]
plt.imshow(img)
plt.show()

# 向上平移
for j in range(WIDTH):
for i in range(HEIGHT):
if (j < WIDTH - 20 and j > 20):
img[j][i] = img[j+20][i]
else:
img[j][i] = 0
plt.imshow(img)
plt.show()

# 向下平移
for j in range(WIDTH, 1, -1):
for i in range(278):
if (j < 144 and j > 20):
img[j][i] = img[j-20][i]
plt.imshow(img)
plt.show()
噪声(Noise)
噪声是一种有趣的增强技术,我开始对这类操作变得更加熟悉。我已经看过很多有趣的关于对抗网络训练的论文,将一些噪声加入到图像中,模型便无法正确分类。我仍然在寻找能产生比下图更好的添加噪声的方法。 添加噪声可能使畸变更明显,并使模型更加稳健。
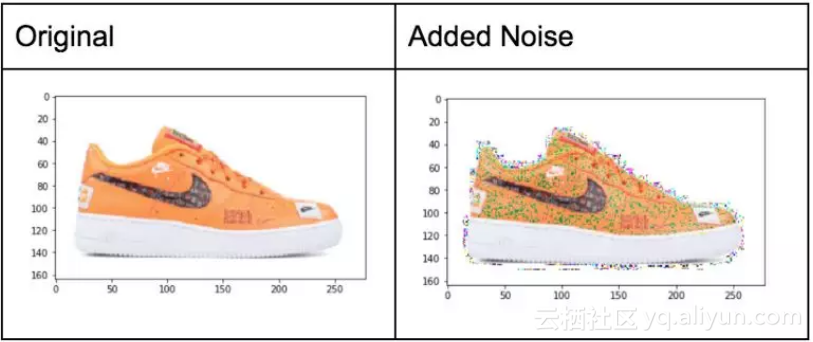
# 添加噪声
noise = np.random.randint(5, size = (164,278, 4), dtype = 'uint8')
for i in range(WIDTH):
for j in range(HEIGHT):
for k in range(DEPTH):
if (img[i][j][k] != 255):
img[i][j][k] += noise[i][j][k]
plt.imshow(img)
plt.show()
生成对抗网络(GAN)
我阅读过很多将生成对抗网络用于数据增强的文献,下面是我使用MNIST数据集生成的一些图像。

正如上图看到的那样,它们看起来确实像3,7和9。 我想扩展网络结构来支持的300x300x3尺寸的输出,而不是28x28x1 MNIST的数字,但是遇到了一些麻烦。 但是,我对这项研究感到非常兴奋,并期待继续这项研究!
原文发布时间为:2018-10-9
本文作者:小韩















 5384
5384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









